







引言
Python中有不少实用的内置装饰器实现,前面已经介绍了缓存、函数重载等方面的应用,相信能在实际工作中,帮助我们大大地简化一些样板化代码的编写,从而提高开发的效率,以及代码的可维护性。
@dataclass也是一个比较实用的内置装饰器,由于它的使用细节比较多,所以,今天这篇文章重点来聊聊@dataclass的使用。
本文的主要内容有:
1、dataclass的定义及基本使用
2、field的使用
3、ClassVar的使用
dataclass的定义及基本使用
dataclass的特性是在Python3.7之后开始引入的,如果自己的Python环境是相对较老的版本需要注意一下。
在开始使用dataclass之前,我们先来看下dataclass的定义:
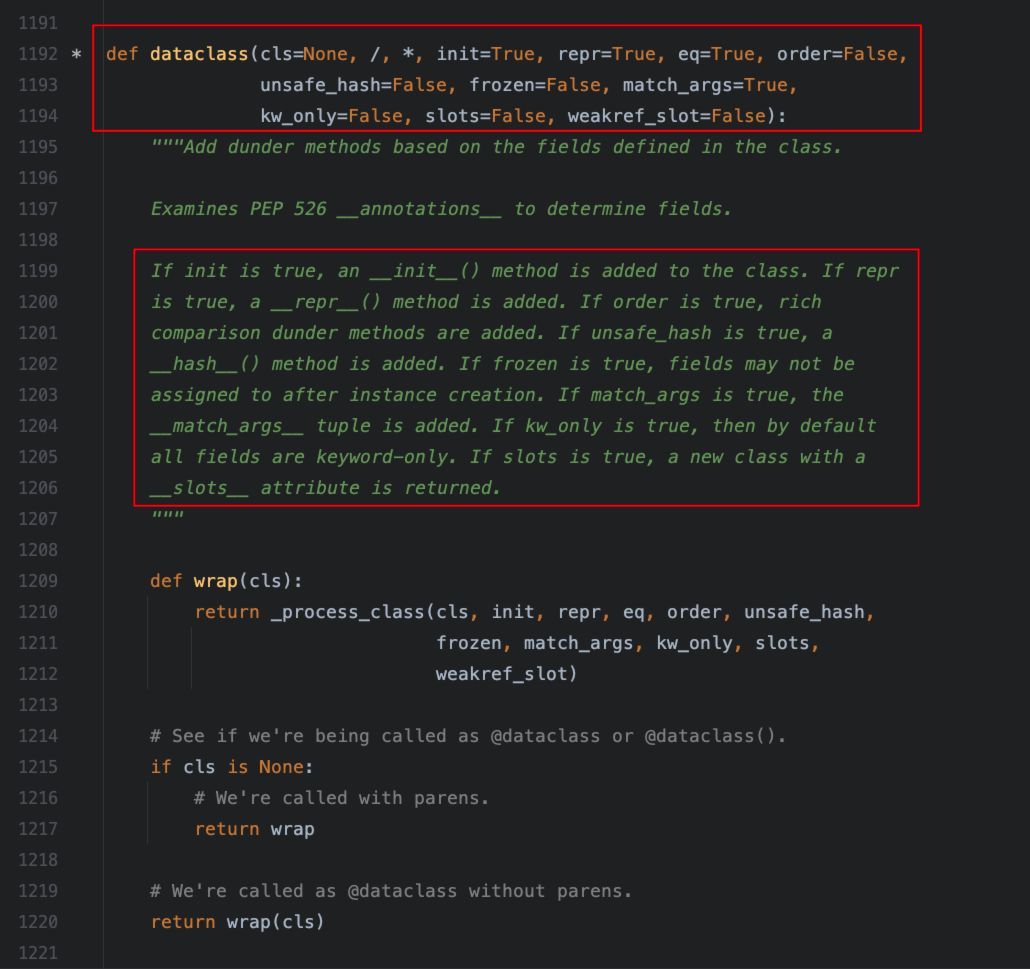
从定义中,我们应该有如下认知:
1、dataclass是一个函数装饰器,这个函数装饰器用于对类进行装饰增强。
2、这个装饰器的实现是基于类中定义的字段,自动生成相应的方法。
3、dataclass()函数中定义了一组默认的参数,这些参数用于控制第2点中所提及的自动生成的方法,比如__init__()、__repr__()等。
4、由于函数中的参数都带有默认值,所以,我们可以使用无参的装饰器,实现大部分场景中的装饰、动态扩充的需求。也可以,通过通过关键字参数的形式传入需要的参数,来更加灵活地使用该函数装饰器。
5、装饰器的核心实现机制在_process_class()函数中,感兴趣的可以自行查看其具体实现过程。
接下来,我们先来用一下无参的dataclass装饰器,直接看代码:
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
if __name__ == '__main__':
p1 = Point(0, 0)
p2 = Point(10, 20)
p3 = Point(0, 0)
print(p1)
print(p2)
print(p3)
print(p1 == p2)
print(p1 == p3)
print(p1 > p2)
执行结果:
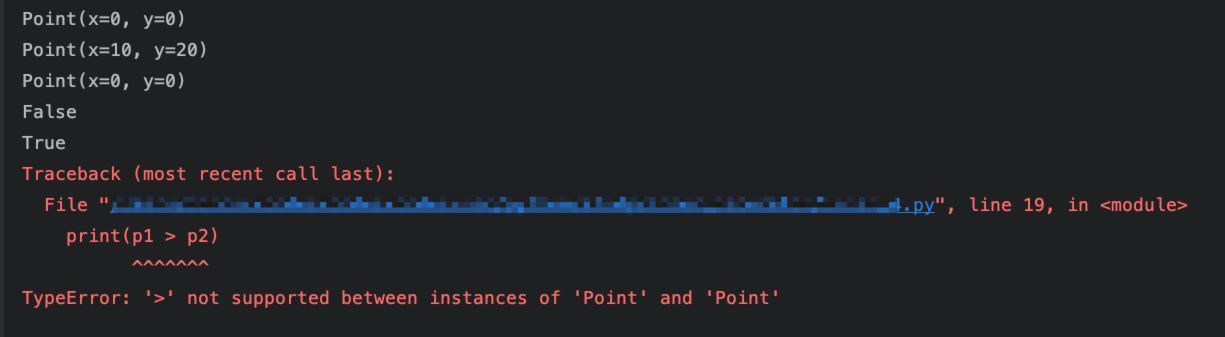
结合上面dataclass定义中,默认值为True的参数,以及当前的执行结果,可以得知:
1、参数init默认为True,则@dataclass装饰的类,会基于我们在类中定义的字段,自动生成实例对象的初始化方法:__init__()。
2、参数repr默认值为True,表示@dataclass装饰的类,会基于我们在类中定义的字段,自动生成实例对象的__repr__()方法。
3、参数eq默认值为True,表示@dataclass装饰的类,会基于我们在类中定义的字段,自动生成__eq__()方法,从而该类支持相等的判断。但是,仅限于=或者!=的操作,当我们尝试>、<等比较时,则会报错提示该类不支持这种操作。
4、参数match_args是在Python3.10中添加的新的参数,默认值为True,主要用于配合match...case...模式化匹配的新特性的使用。当该参数为True时,会自动生成__match_args__属性,该属性是一个包含字段名的元组,这样可以在模式匹配中进行数据类的自动化解包。
前3点是比较简单的,我们来举例说明一下match_args的作用:
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
if __name__ == '__main__':
p1 = Point(0, 0)
print(p1.__match_args__)
p2 = Point(10, 20)
match p2:
case Point(0, 0):
print('该点是原点')
case Point(x, y):
print(f'该点({x},{y})不是原点')
执行结果:
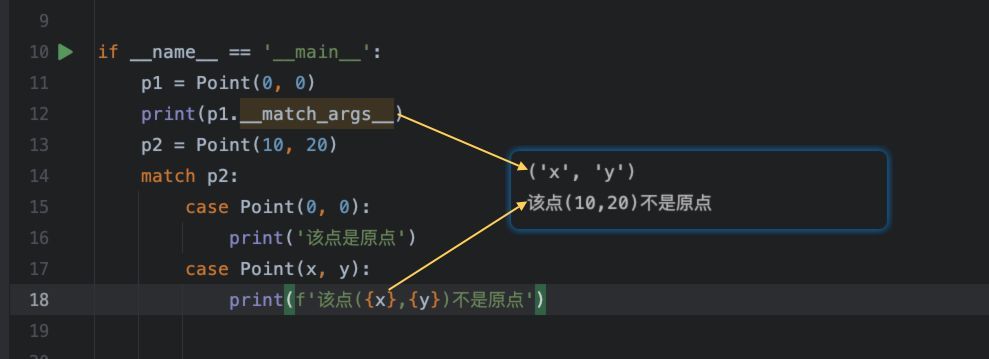
可以看到,在match...case...模式匹配中,自动将实例对象的字段解包到对应的x和y变量中了。
回到上面提到的第3点,@dataclass默认不支持>、<等的比较运算的,因为order参数默认为False,我们修改该参数,可以让数据类自动支持这些比较运算。
from dataclasses import dataclass
@dataclass(order=True)
class Point:
x: int
y: int
if __name__ == '__main__':
p1 = Point(0, 0)
p2 = Point(10, 20)
p3 = Point(15, 0)
p4 = Point(9, 100)
print(p1 < p2)
print(p3 <= p4)
ps = [p1, p2, p3, p4]
print(ps)
ps.sort()
print(ps)
执行结果:
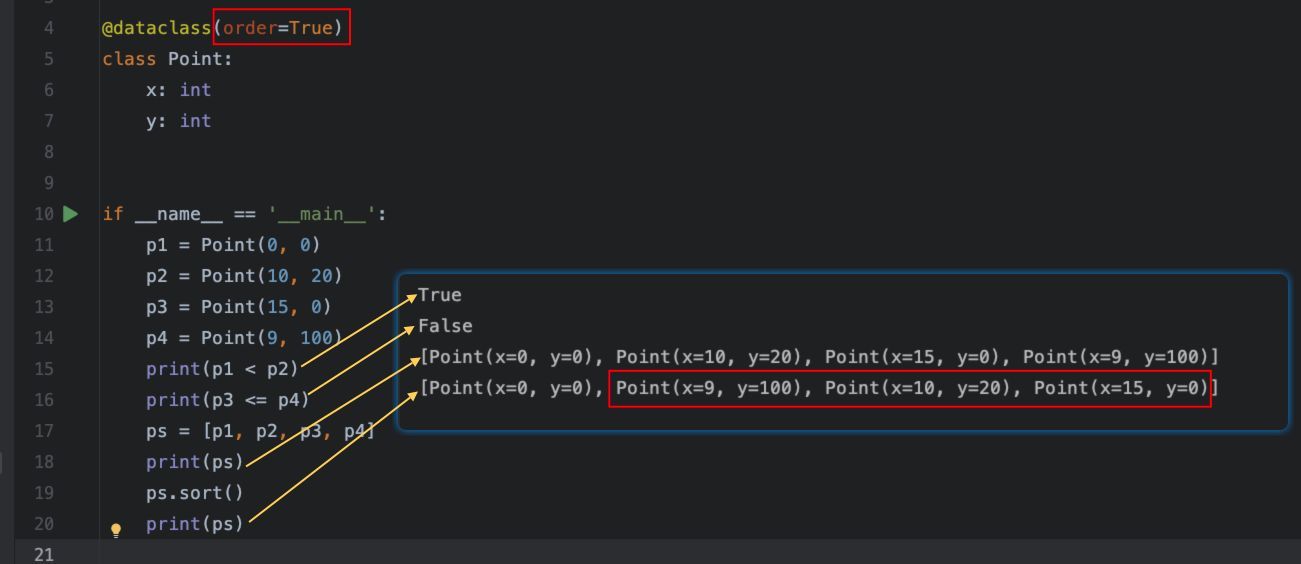
需要说明的是,当order为True时,比较运算的规则是:将在类中定义的字段按照定义的顺序组装为元组,然后进行元组的比较,也就是按照元组中的元素顺序进行比较。所以,这种情况下,如果需要自定义比较、排序的规则,只需要调整类中字段定义的顺序即可。
field的使用
在基本的使用中,在类中定义的所有字段都会出现在自动添加的方法中,我们如果需要控制字段在各个自动生成的方法中是否出现,可以通过filed来进行控制。
首先看一下field的定义:
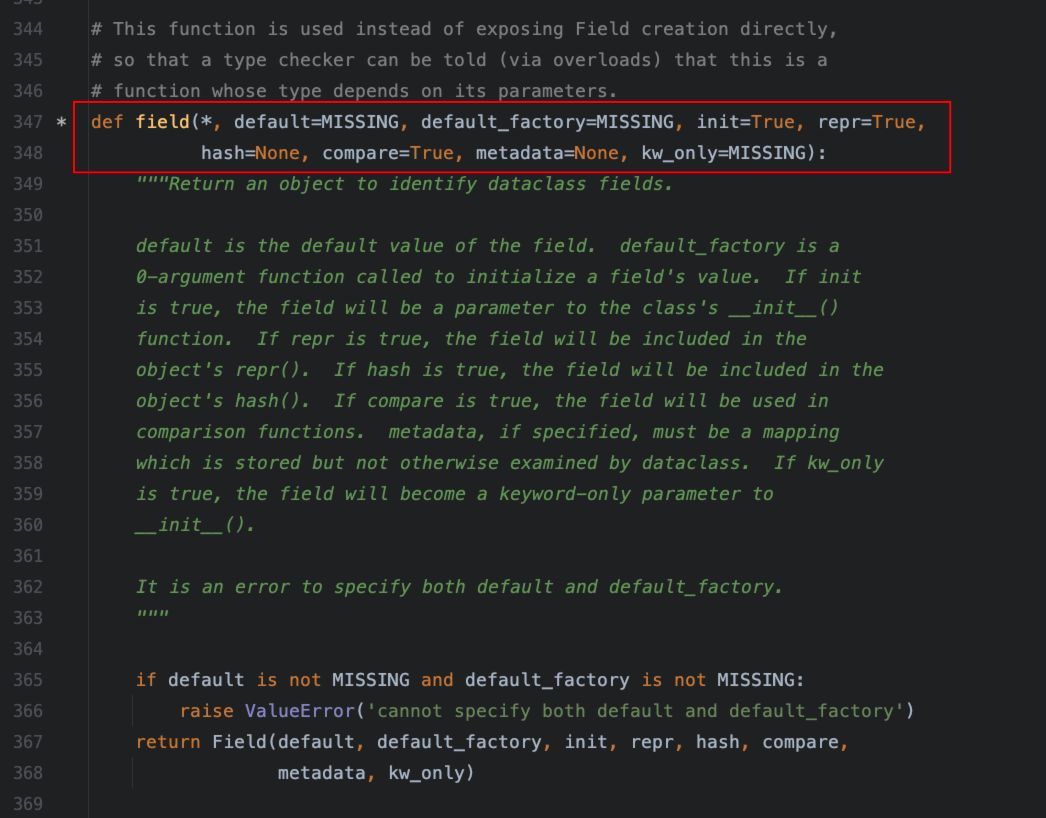
从定义中,可以知道,我们可以通过field控制类中定义的字段的默认值、默认值工厂函数、是否出现在特定方法中等。
此外,如果只需要给定字段默认值,是不需要用到field的。
接下来,我们通过代码修改一下Point类的定义:
from dataclasses import dataclass, field
@dataclass(order=True)
class Point:
x: int = field(compare=False)
y: int = 10
z: int = field(default=0, init=False, compare=False)
if __name__ == '__main__':
p1 = Point(0, 0)
p2 = Point(10, 20)
p3 = Point(15, 0)
p4 = Point(9, 100)
print(p1 < p2)
print(p3 <= p4)
ps = [p1, p2, p3, p4]
print(ps)
ps.sort()
print(ps)
代码中,我们做了如下的调整:
1、将一个二维平面的点,升级为了一个三维空间的点,增加了一个Z轴的坐标值,为了不影响用户端代码的使用,使用filed将z字段设置为默认值为1,不需要放到__init__()方法中,不参与比较运算。
2、我们修改了比较运算的规则,将x通过field设定为不参与比较运算。
3、给y设定了一个默认值为10。
用户侧(这里以if __name__ == '__main__'代码块为例)中的代码无需做任何修改。
执行结果:
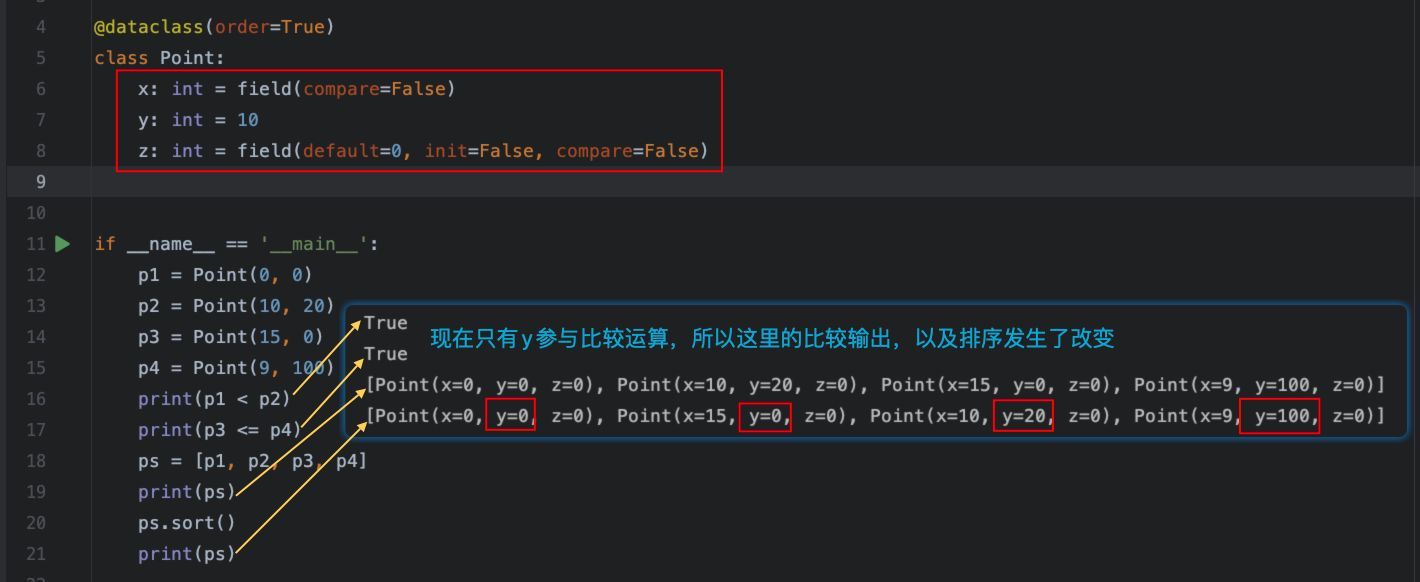
可以看到,比较和排序的规则已经变成了只比较y了。
ClassVar的使用
在定义类中,有时候我们还需要定义一些类变量,在@dataclass装饰器定义的数据类的语境中,我们可以通过ClassVar来进行类变量的定义:

其实,ClassVar是一个类型注解的相关函数,使用ClassVar包裹的注解表示该属性应当作为一个类属性存在。
简单看下ClassVar的使用:
from dataclasses import dataclass, field
from typing import ClassVar
@dataclass(order=True)
class Point:
x: int = field(compare=False)
y: int = 10
z: int = field(default=0, init=False, compare=False)
dimension: ClassVar[int] = 3
version: ClassVar[str] = 'v2'
if __name__ == '__main__':
p1 = Point(0, 0)
p2 = Point(10, 20)
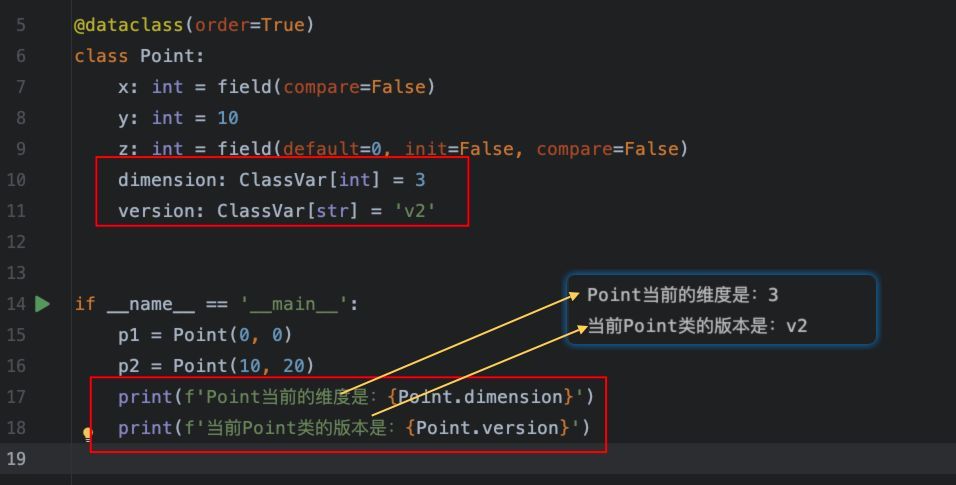
print(f'Point当前的维度是:{Point.dimension}')
print(f'当前Point类的版本是:{Point.version}')执行结果:
总结
本文详细介绍了@dataclass这个内部装饰器,在定义数据类中的各种用法,详细介绍了dataclass函数中几个比较重要的带默认值参数的使用。同时介绍了field()函数对@dataclass装饰器装饰效果的影响。此外,还介绍了在数据类中通过ClassVar[type]的类型注解,实现类变量的定义。
感谢您的拨冗阅读,希望对您有所帮助。



















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











