







安装步骤如没特殊指明哪台服务器,则说明都是在3台服务器上做同样的操作。
spark-env.sh增加scala_home
让环境变量生效
1.准备
1.1 装有centOS7的3台服务器
master 192.168.174.132
node1 192.168.174.133
node2 192.168.174.134
1.2 搭建hadoop集群环境
参考“hadoop学习1--hadoop2.7.3集群环境搭建”
1.3 准备安装包
scala-2.11.8.tgz
spark-2.0.0-bin-hadoop2.7.tgz
然后上传到3台服务器的/soft目录上
2.安装scala
2.1 解压
[root@node1 soft]# mkdir -p /soft/scala
[root@node1 soft]# tar -zxvf scala-2.11.8.tgz -C /soft/scala2.2 配置环境变量
[root@node1 soft]# echo -e "export SCALA_HOME=/soft/scala/scala-2.11.8" >> /etc/profile
[root@node1 soft]# echo -e "export PATH=$PATH:$SCALA_HOME/bin" >> /etc/profile3.安装spark
3.1 解压
[root@node1 soft]# mkdir -p /soft/spark
[root@node1 soft]# tar -zxvf spark-2.0.0-bin-hadoop2.7.tgz -C /soft/spark/3.2 配置环境变量
[root@node1 soft]# echo -e "export SPARK_HOME=/soft/spark/spark-2.0.0-bin-hadoop2.7" >> /etc/profile
[root@node1 soft]# echo -e "export PATH=$PATH:$SPARK_HOME/bin" >> /etc/profile3.3 配置集群
slaves增加node1,node2
[root@node1 spark-2.0.0-bin-hadoop2.7]# cd /soft/spark/spark-2.0.0-bin-hadoop2.7/conf/
[root@node1 conf]# cp slaves.template slaves
[root@node1 conf]# echo -e "node1\nnode2" > slavesspark-env.sh增加scala_home
[root@master conf]# cp spark-env.sh.template spark-env.sh[root@master conf]# echo -e "export SCALA_HOME=/soft/scala/scala-2.11.8" >> spark-env.sh
[root@master conf]# echo -e "JAVA_HOME=/soft/java/jdk1.7.0_79" >> spark-env.sh让环境变量生效
source /etc/profile
4.启动
启动hadoop集群,master上执行
[root@master conf]# $HADOOP_HOME/sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /soft/hadoop/hadoop-2.7.3/logs/hadoop-root-namenode-master.out
node1: starting datanode, logging to /soft/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to /soft/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-node2.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /soft/hadoop/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /soft/hadoop/hadoop-2.7.3/logs/yarn-root-resourcemanager-master.out
node1: starting nodemanager, logging to /soft/hadoop/hadoop-2.7.3/logs/yarn-root-nodemanager-node1.out
node2: starting nodemanager, logging to /soft/hadoop/hadoop-2.7.3/logs/yarn-root-nodemanager-node2.out
[root@master conf]# $SPARK_HOME/sbin/start-all.sh
org.apache.spark.deploy.master.Master running as process 3075. Stop it first.
node2: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/spark-2.0.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node2.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/spark-2.0.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node1.out
[root@master conf]# 5.验证
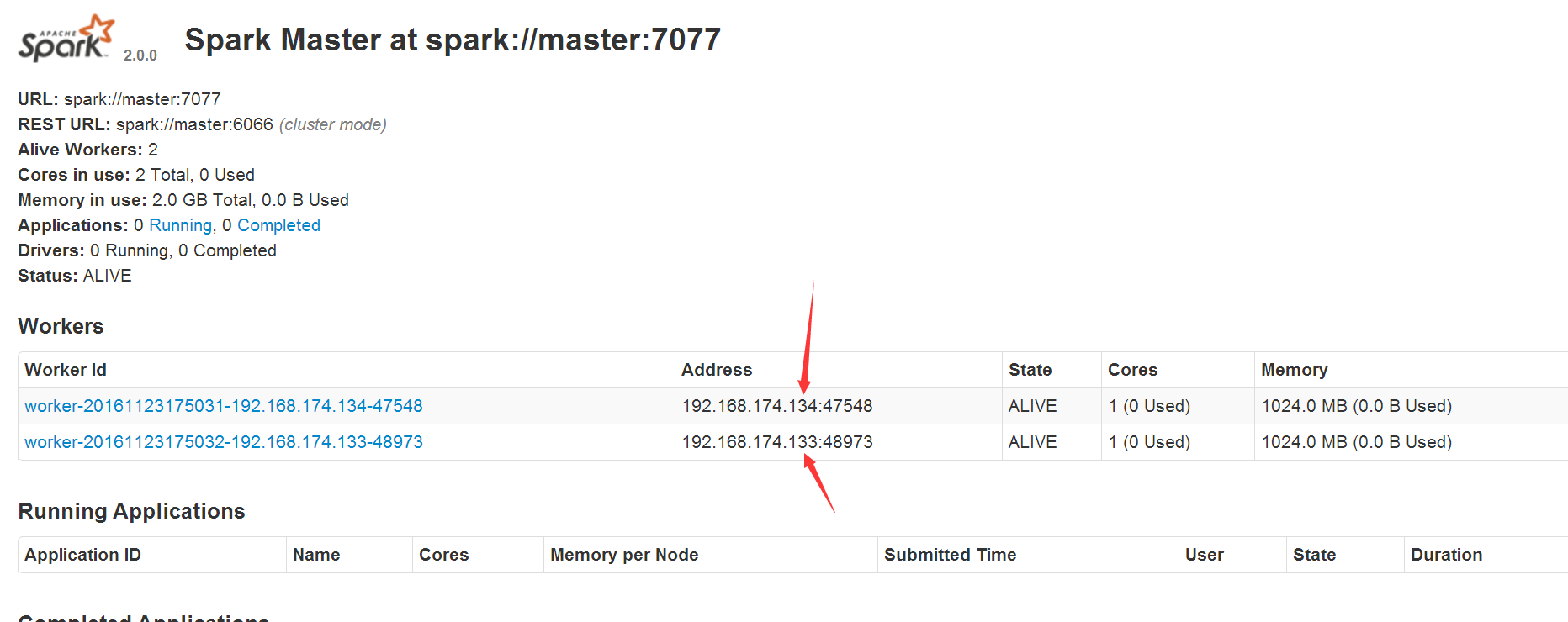
访问master的8080,比如http://192.168.174.132:8080/















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









