










Relation Net阅读笔记
Sung F, Yang Y, Zhang L, et al. Learning to compare: Relation network for few-shot learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1199-1208.
乱扯
这篇文章叫Relation Network,今天早上醒来一看群里,今天组会分享的同学发的PPT也叫Relation Network,这不赶巧了吗,打开一看,我说婷婷,这个小伙子不讲⑤德,此Relation Network非彼Relation Network,他那篇是MSRA的一篇工作,我以前也看过MSRA对那篇文章的解读,挺有意思的,更扯淡的是这篇论文的标题叫做Relation Network for Object Detection,后半截基本长得差不多(好像也差得多),这两篇论文以这样的标题来骗,来偷袭我21岁的小同志,这好吗,这不好,我劝这篇论文耗子尾汁,不要再犯这样的聪明,小聪明啊。
好了,机灵抖完了,回过头来看看这篇论文。
文章主要思想
这篇论文也是一个基于Metrics learning的方法。前面我们其实也讲了一些用metrics learning来做FSL的工作比如Siamese Network,Matching Net等等,这些方法的创新基本都是在Embedding方案或者网络结构上的,但是metrics measurement上大多都直接选取了一个固定的从cosine或者其他的变体。然而我们知道其实metrics learning另一个重要的部件就是度量,所以这篇文章就希望从measurement的角度去创新,作者希望提供一个深度学习模型去学习这种度量方案。
整篇文章的思路其实非常简单,方案也非常简单。
Details
总体思路
大体上就是按照传统的metrics learning的套路去做,先搞了一个embedding的module去support set的图像和query 图像进行embedding,然后将support set样本和query样本embedding的结果concat后放到relation module中去,判定所属的类别。
在训练的方法上作者依旧采用了传统的FSL的training strategy进行N-way,K-shot的训练,分为training tasks和Test Tasks,每一个task由support set和query set组成训练样本。但是这里对于one shot和few shot显然有一个不一样了,对于one shot来说,进行relation判定的时候,每一个class只有一个样本,所以只需要对一个query和每一个类别的shot进行判定就可以了,但是对于few shot来说,是从每个类别中选取一个样本呢还是其他什么方法呢?作者的方法是将所有shot在embedding后的feature map进行加和,因为有很多样本很难去抉择选择哪一个,不过这个加和的方案是不是一个好方案呢,明天的另一篇文章有新的想法。
然后对于这个任务来说,其实就是一个Classification Task,但是作者最终选用了MSE作为loss,奇怪了,分类任务怎么用起MSE了,这就和他的relation module有关了,他的relation module实际上并不是输出的0,1的值,而一个介于0~1的score,这也是深度学习的常规操作了,所以这个结果就导致原本的Classification Task cast to Regression Task。所以如果我们讲support set中的图像embedding i,query set中的图像embedding j的relation score定义为
r
i
,
j
r_{i,j}
ri,j,那么最后我们将得到这个目标函数:
ϕ
,
φ
←
a
r
g
m
i
n
ϕ
,
φ
∑
i
=
1
m
∑
j
=
1
n
(
r
i
,
j
−
I
(
y
i
=
=
y
j
)
)
2
\phi, \varphi \leftarrow \mathop{argmin}\limits_{\phi, \varphi}\sum_{i=1}^{m}\sum_{j=1}^{n}(r_{i,j}-I(y_i==y_j))^2
ϕ,φ←ϕ,φargmini=1∑mj=1∑n(ri,j−I(yi==yj))2
模型架构
模型的架构总体架构如图:

其中整个模型的网络结构如图,每个卷积模块是由一个有64个 3 × 3 3\times3 3×3的卷积、bn层、relu构成的:
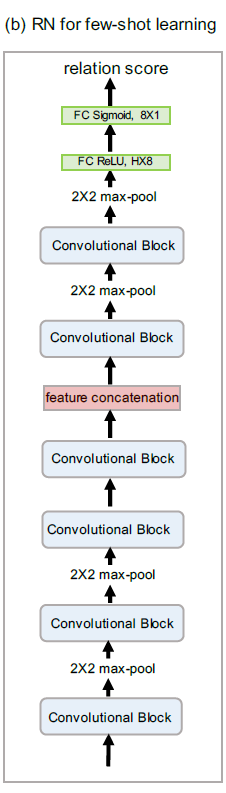
同时author为了适配zero shot learning,也给出了针对zero shot learning的architecture如下,这个很好理解,因为往往zero shot learning可能是给定一个特征vector,所以作者将原本的embedding方式分开处理:

实验
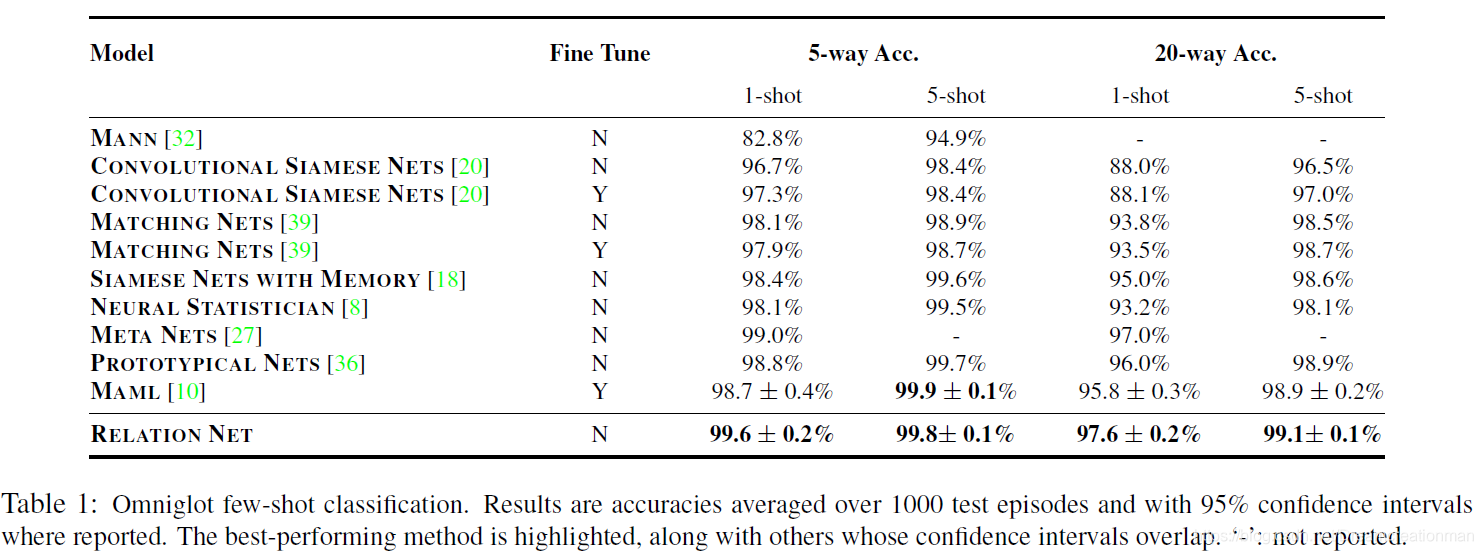
感觉这篇paper的代码很好实现,有空(择日不如撞日,明天吧)整一个。这是作者在Omniglot上的测试结果:
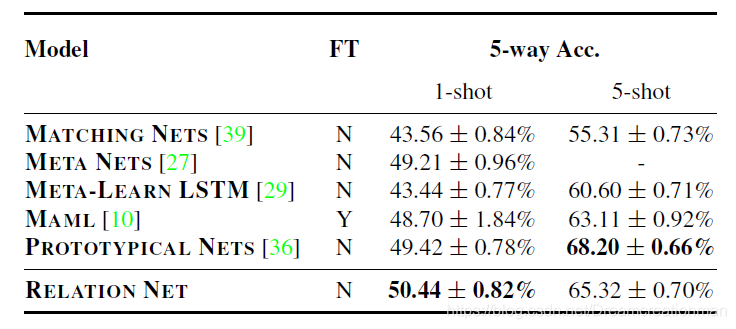
这是在miniImageNet上的结果,这里面横空出世的这个Prototypical Network打算一会儿把文章写出来:
文中还有作者对于zero shot learning的实验结果,我这里就不放了,感兴趣的话可以自行查看原论文。
My comment
正如前文所说,这篇文章基本上就是一个全深度学习的网络了,从表现上看结果还是比较不错的,主要创新就是使用了神经网络结构作为一个可学习的非线性metrics measurement,使得模型的整体性能表现非常不错。另外个人认为相比于matching net来说整个文章采用的结构都比较简单,这也和FSL任务本身有很大的关系,FSL可能还是要偏向Semi-supervised或者Unsupervised,如果使用这种training的话个人觉得要尽可能避免现在神经网络这种算力的角逐。
后记
这篇文章本来又该昨天发的,但是昨天看奇葩说去了哈哈哈,看完又有点小事,忙到晚上一点多(至于是什么事后面如果有好消息会写成一篇博客谈谈哈哈哈)另外,其实我这个是我自己的论文笔记,不是论文解读,所以可能有些地方有点晦涩,不过欢迎大佬一起交流或者指正。

如果你觉得我的文章写的不错的话,麻烦帮忙向大家推广关注我的公众号啊(名称:洋可喵)!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









