










Few-shot Object Detection via Feature Reweighting 阅读笔记
文章目录
Kang B, Liu Z, Wang X, et al. Few-shot object detection via feature reweighting[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 8420-8429.
文章简介
ICCV 2019的一篇文章,文章自称是第一个做Few Shot Object Detection的工作,我去瞅了瞅,可能是吧。小样本学习其实也就是从2016年Matching Net以及Prototypical Net和Relation Net之后才逐渐发展起来的,但是现在小样本学习的研究主要还是处于理论阶段,做小样本图像分类。由于样本量小带来的泛化能力不足、模型的鲁棒性问题是解决的核心问题。
这篇文章在2019年就能利用Few Shot Learning的思路来解决Object Detection的问题,在那个时候肯定是比较前沿的,但是在整体的解决思路和方法上相较于昨天CVPR上那篇工作都有较大不同,这篇工作的主要贡献在以下几个方面:
- 作为开山之作,开启了小样本目标检测的研究。个人觉得小样本学习是比无监督学习、自监督更类似于人类智能的学习模式,但并不是现在的小样本学习范式,同时现在小样本学习在实际的应用上还需要跟多的探索,不能只停留在Image Classification任务上。
- 作者设计了一个一阶段的小样本检测的模型,包含一个meta feature learner和一个reweighting module来分配权重,并通过实验来证明了模型的有效性。
Methodology
模型希望获得一个小样本目标检测模型,通过利用基类的知识来学习并在测试中检测novel class的图像。整个模型我觉得非常地简单易懂,这张图画的很清晰,首先是两个分支,上面分支就是一个backbone提取特征;下面分支通过一个Reweighting模块将每个不同的类比编码成一个一维向量,并channel-wise将其与上分支图像的特征图相乘,然后通过一个Predictor获得很多个类似于YOLO的预测向量。这是个一阶段模型,与昨天的那个工作不同,不需要region proposal,所以这篇工作和昨天的工作优化的基本点不同。
那么我们现在就需要弄懂几个问题,第一:few shot learning问题的problem setting,不同的方法解决Few Shot Learning问题的思路不一样,其对应的problem setting也不同;第二,下分支的Mask是个什么东西;第三,下分支的Reweighting Module是怎么做的。
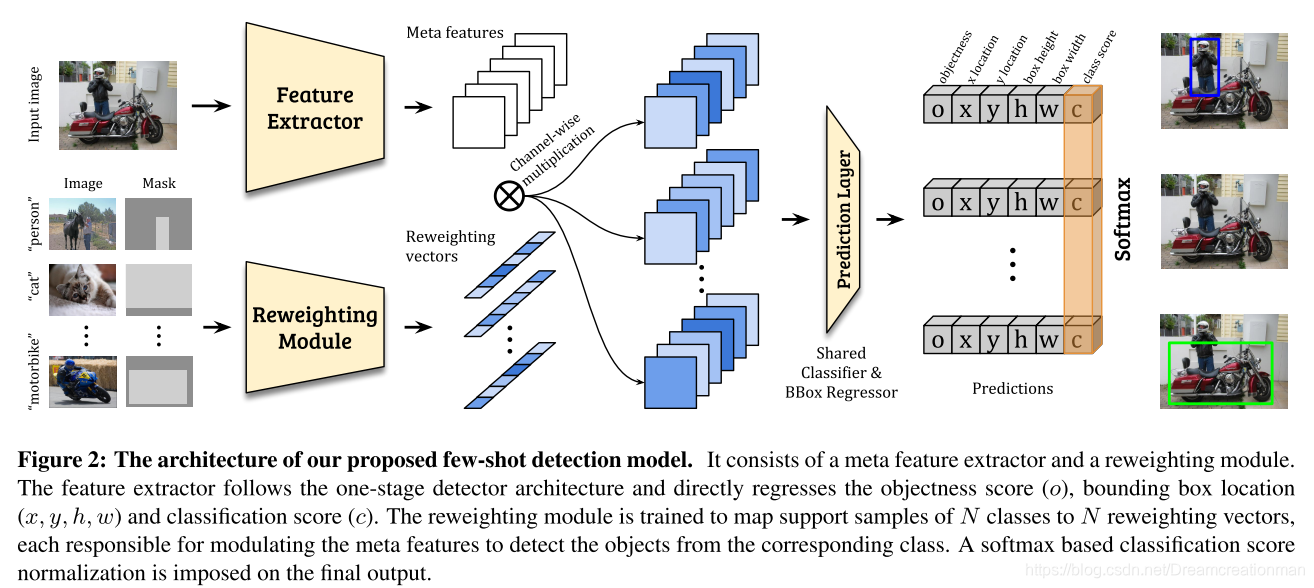
Reweighting Module
本文宣称为了便于学习和提高计算效率,所以采用轻量化的CNN来设计Reweighting Module。作者从Support Set中提取图像 I i I_i Ii及其包围框 M i M_i Mi,这个图像中包含novel set可能的(至少)一个分类类别,那么我们要学习且只想学习这个分类类别特征,但是一张图像除去包围框以外还有其他部分啊,咋办?本文做了一个和图像一样大的mask,mask落在包围框内为1,否则为0,然后把这个包围框和图像进行星乘。如果有多个包围框还是只用一个,其他的都mask为0。所以前面问题2解决了。然后mask后的图像经过reweighting module后可以得到一个特征向量……之后的故事上面都有了。
那么为什么要做mask,而不直接用原图像或者直接把包围框的部分截取出来呢?作者做了实验如下:
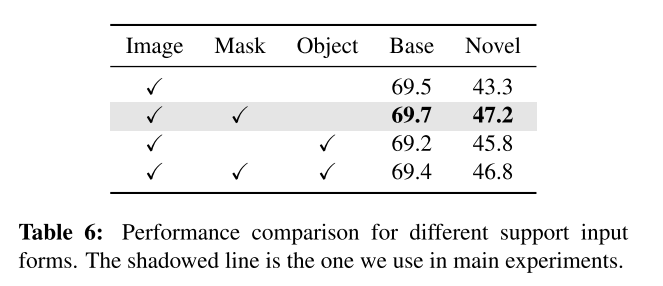
首先从结果上看使用image+mask的效果最好,结果正义上来讲应该是选这个。从思考的角度上讲,我个人理解是,首先由于包围框大小不同,并不好输入,输入的话需要裁剪或者resize,效果不一定会很好,直接mask是一个比较方便的选择;其次,如果不做mask,图片中的其他冗余像素肯定会对下游任务产生干扰。至于作者是怎么做的这个the cropped target object论文中没有详细阐述,所以第四种方式为什么比第二种还差一些,我不知道怎么圆。
学习策略
后面两个问题都解决了就剩下前面的那一个问题了:Problem Definition以及怎么学。
整个模型的训练分为两个阶段,首先在大规模的base set上进行训练,而且照着我们上面的model architecture的示意图进行训练。作者说这样是为了保证训练的协调,也因为这种训练方式,我觉得这里不足以称作是预训练;然后作者进行few shot finetuning,作者结合base set和novel set进行训练,在novel class上只有k个标注的包围框(同时base set也有k个)。
本文构建了采用episodic training,构建了很多个training episode,每一个task包含一个Support Set和一个Query Set,Support Set里包含N个图像,并且每张图像都至少包含一个不同的base class。定义目标函数为: L d e t = L c + L b b x + L o b j \mathcal{L}_{det} = \mathcal{L}_c + \mathcal{L}_{bbx} + \mathcal{L}_{obj} Ldet=Lc+Lbbx+Lobj,后面两个损失函数都和YOLOv2回归框和物体的Loss一样。前面这个 L c \mathcal{L}_c Lc是啥?在上面Model flowchart上最后的预测它是每一个类别都生成了一个vector,然后进行判别,最后这一部分怎么计算Loss?
直观的方法就是只要是target class那么就设为1,其他设为0,然后对每个类别使用binary cross-entropy,但是作者说这样会使得一列火车被检测为car或者bus,因为binary cross entropy倾向于平衡正负样本,而我们这种训练会导致N个类别中只有一个正例。所以作者直接使用了Softmax,将所有类别整成一个classification score,即$
\hat{c}{i}=\frac{e{c_{i}}}{\sum_{i=1}{N} e^{c{j}}}
,
最
终
l
o
s
s
就
可
以
计
算
为
,
其
中
,最终loss就可以计算为,其中
,最终loss就可以计算为,其中\mathbb{1}(\cdot)$是指示函数:
L
c
=
−
∑
i
=
1
N
1
(
⋅
,
i
)
log
(
c
^
i
)
,
\mathcal{L}_{c}=-\sum_{i=1}^{N} \mathbb{1}(\cdot, i) \log \left(\hat{c}_{i}\right),
Lc=−i=1∑N1(⋅,i)log(c^i),
实验
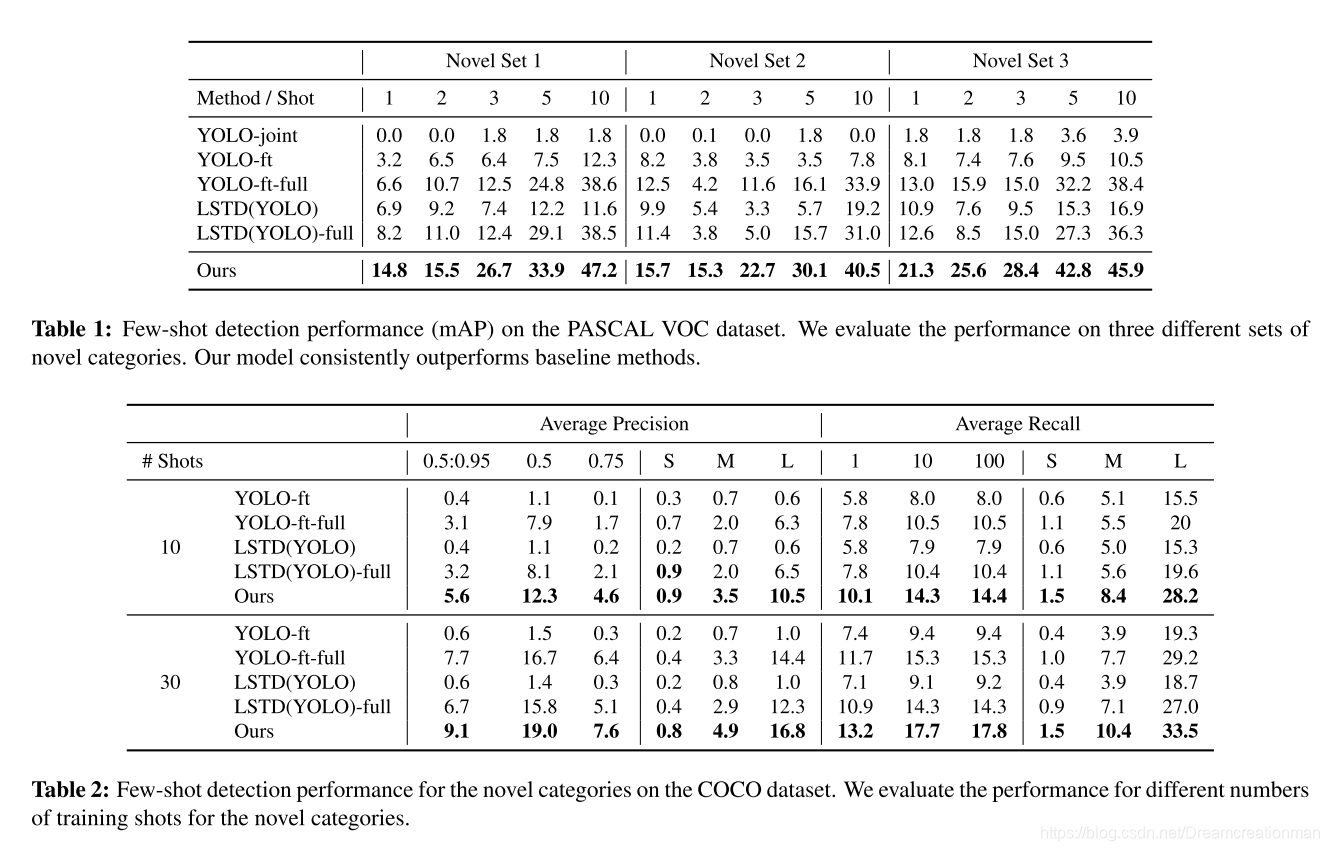
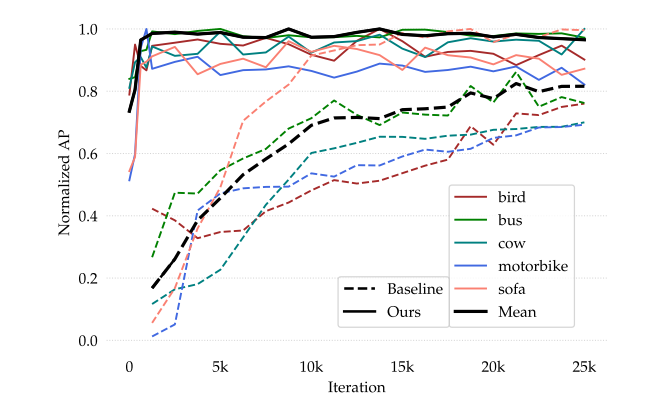
从上面这张图可以看到实验结果还是比较competitive的,在1 shot上的表现还是比较差;从下面这张可以看出模型的收敛速度非常可观。
My Comment
这篇开山之作,首先还是比较有意思,这篇文章之后我也看到了一些在这方面做的工作,这篇工作在处理思路上和昨天那篇完全不同,不论是从model的选择上还是基本假设上。
作者在Learning Scheme的部分提了一下: After this, the reweighting module can be completely removed during inference,我对这个挺感兴趣的,前一段时间组会的时候也和同门讨论了清华大学丁霄汉他们组的RepXXX系列工作,最近听一个分享也听到了一个动态推理网络,他们的共同思想就是为什么训练和推理一定要用相同的model structure呢?我偏不,inference的时候很多不必要的模块就被去掉了,这样可以在保证准确率的情况下极大程度的提高inference的速度,我觉得真的是一个很好的insight。
这篇工作里面这个reweighting模块的实现可能就是一个简单的CNN,我觉得能不能融合一些其他的先验?我想起了Distibution Calibration,今年ICLR的一个工作,通过对Base Set的先验的探究来促进训练?无论如何我觉得FSOD方面有很多地方可以思考和深入,后续会持续关注更多的工作。














 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









