









笔记来源B站:https://www.bilibili.com/video/BV1xt411v7z9?p=21
python学习笔记
1 Numpy
1.1 Numpy优势
1.1.1 Numpy介绍
Numpy(Numerical Python)是python的数值计算库,用于快速处理任意维度的数组
Numpy支持常见的数组和矩阵操作
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器
1.1.2 ndarray介绍
ndarray:N-dimensional array
用法示例:
import numpy as np
score = np.ndarray([],[],[])
1.1.3 ndarray与Python原生list效率对比
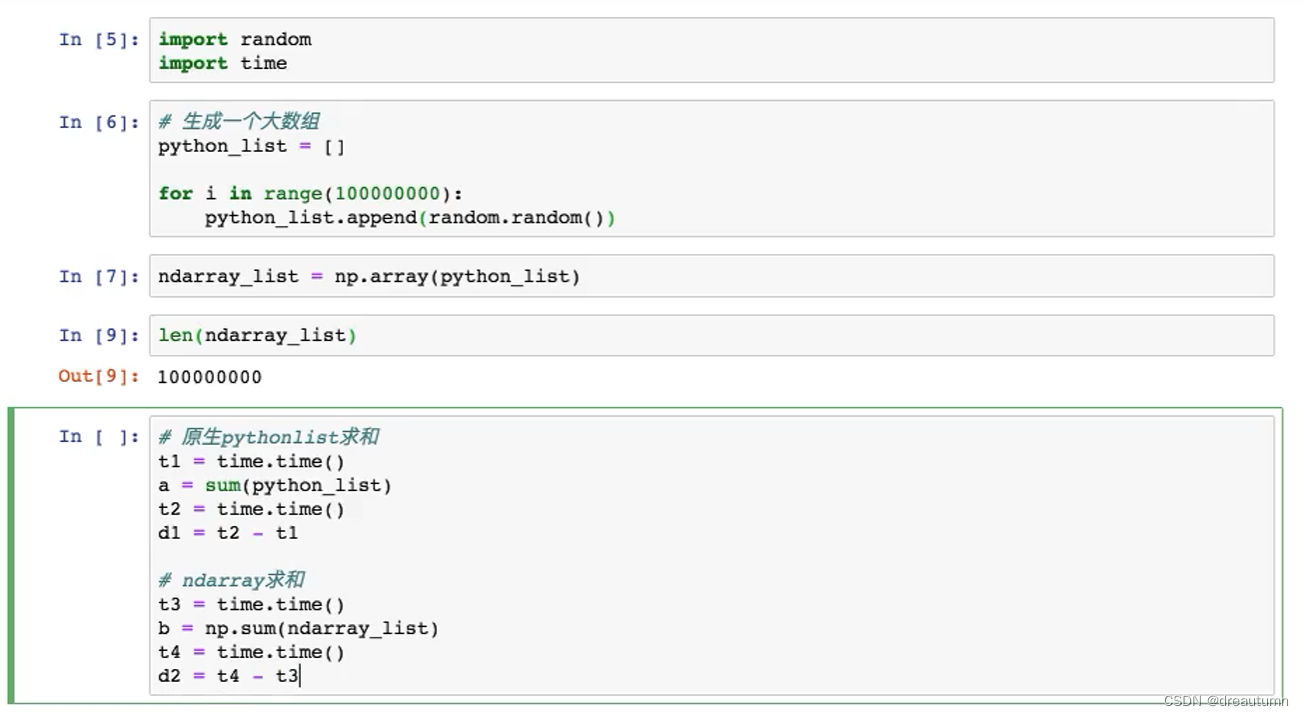
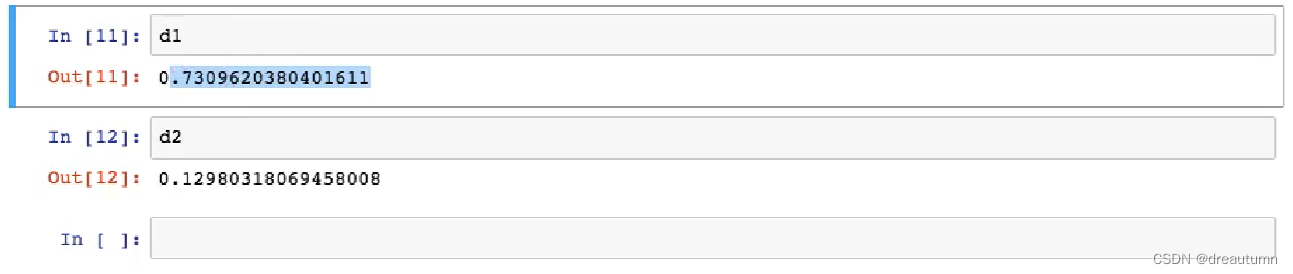
结果:
1.1.4 ndarray优势
-
内存块风格
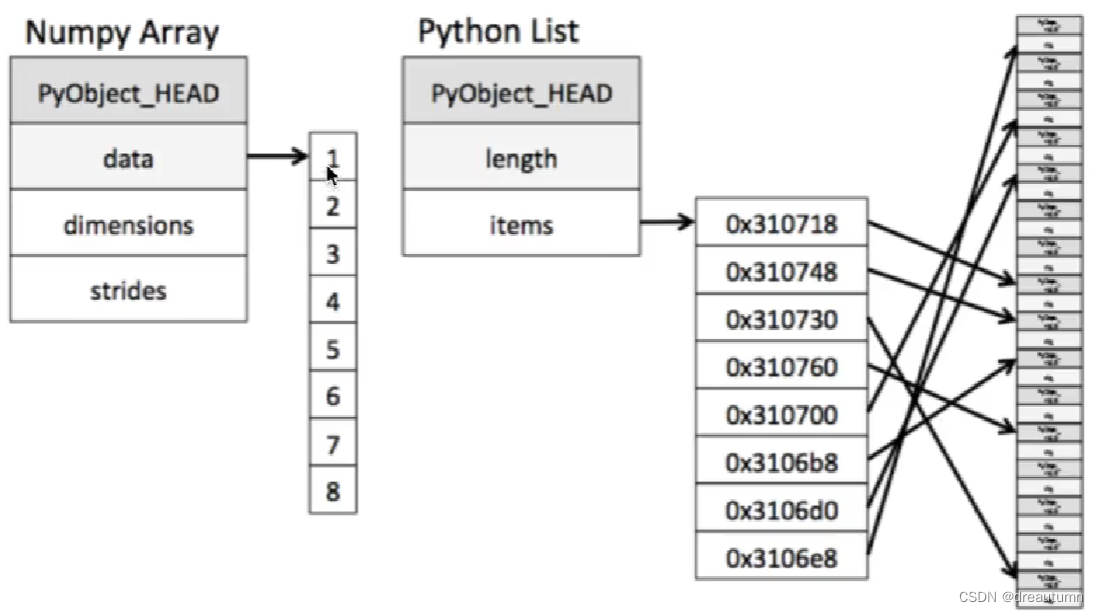
- ndarray存储的都是相同类型的数据,这样存储数据时数据与数据的地址都是连续的,虽然通用性比较差,但是能极大的提高运算效率
- list可以存储不同类型的数据,因此通用性较强,但是数据的地址不是连续的,读取数据的时候只能一个一个寻址,造成效率不高
-
ndarray支持并行化(向量化)运算
-
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码
1.2 认识N维数组-ndarray属性
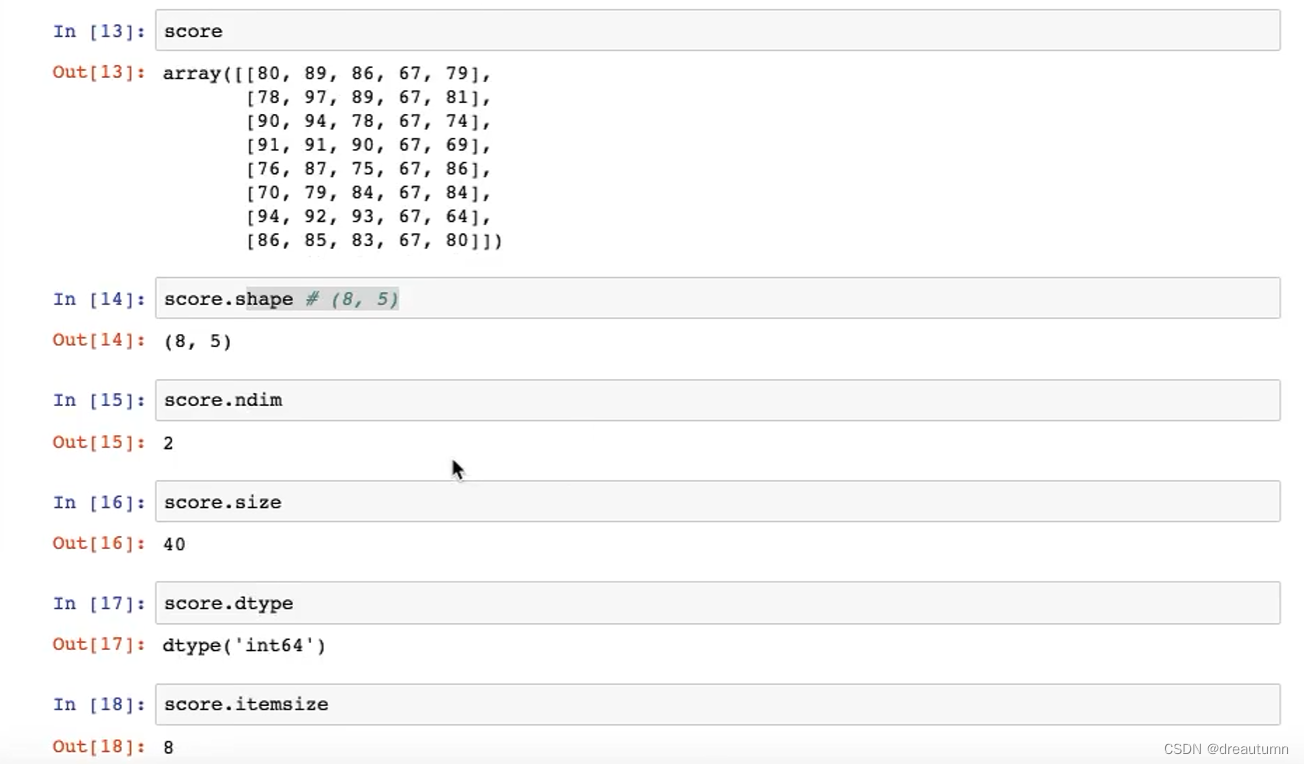
1.2.1 ndarray的属性
数组属性反映了数组本身固有的信息
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.dtype | 数组元素的类型 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
其中上面两个加粗的属性比较重要,知道上面两个加粗的属性之后,就相当于知道了所有的其他属性
1.2.2 ndarray的形状
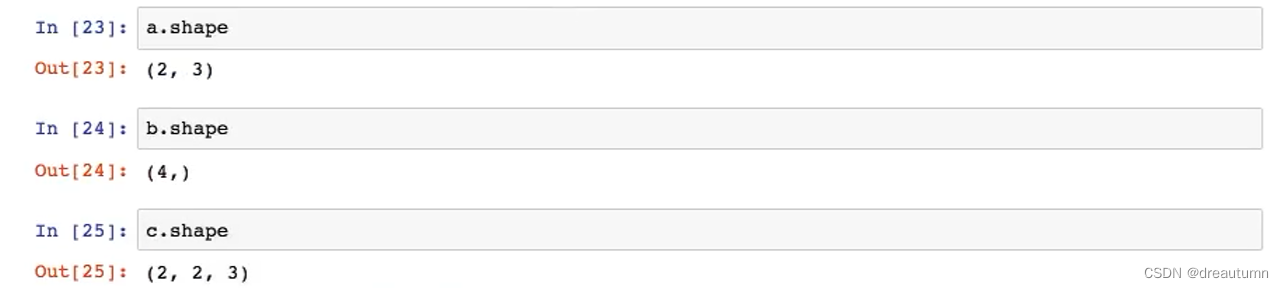
创建三个不同的数组
a = np.array([[1,2,3],[4,5,6]])
b = np.array([1,2,3,4])
c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
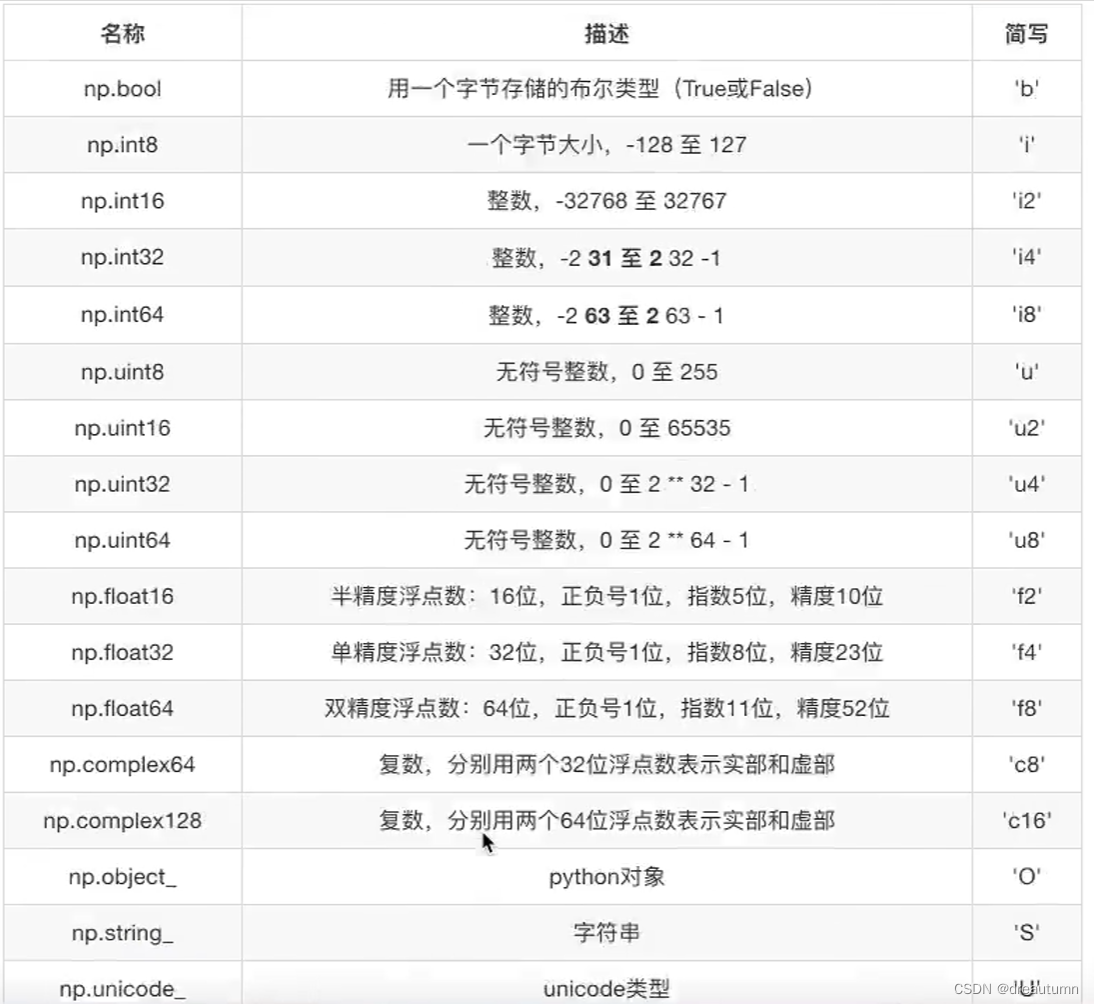
1.2.3 ndarray的类型
1.3 基本操作
1.3.1 生成数组的方法
-
生成0和1的数组
np.zeros(shape)
np.ones(shape)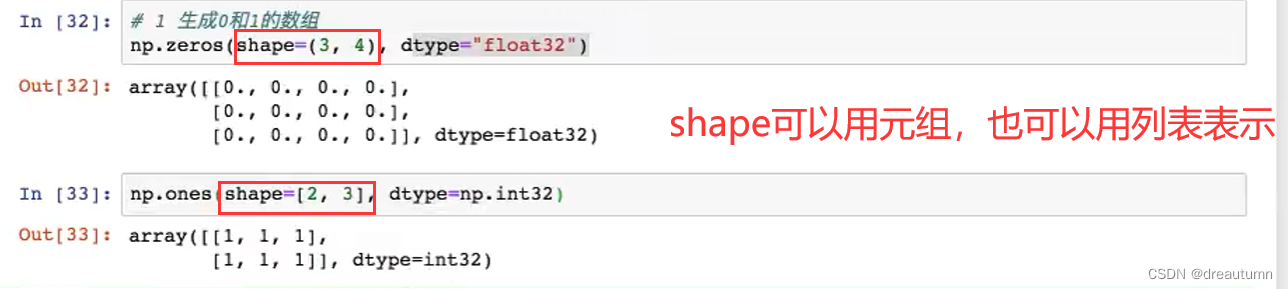
-
从现有数组中生成
np.array()
np.copy()
np.asarray()注意:前两者是创建了一个新的数组,最后
np.asarray()是指拷贝了索引值,因此当原数组发生改变的时候,使用最后一种方法所“创建”的数组也会发生变化 -
生成固定范围的数组
np.linspace(0, 10, 101)
# 生成[0,10]之间的等间距101个点
np.arange(a, b, c)
# 生成[a, b)之间的点,c是步长 -
生成随机数组
- np.random模块
- 均匀分布
np.random.uniform(low = 0.0, high = 1.0, size = None) - 正态分布
np.randoom.normal(loc = 0.0, scale = 1.0, size = None)
- 均匀分布
- np.random模块
1.3.2 切片索引
- 二维数组索引
res = data[0, 0:3]- 代表索引data的第一行,第1到3列
- 注意:用
:索引时是左闭右开的
- 三维数组索引
- 方法一样,从高维向低维索引即可
1.3.3 形状修改
-
ndarray.reshape((a,b))- 将数组修改为a行b列,返回一个新的数组
- 注意:只会将形状重新排列,内部的数据顺序不会改变(不能实现转置)
import numpy as np a1 = np.array([[1,2,3],[4,5,6]]) print("-------before---------") print(a1) a2 = a1.reshape((3,2)) print("-------after:a1---------") print(a1) print("-------after:a2---------") print(a2)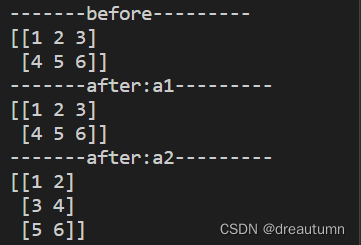
-
ndarray.resize((a,b))- 将原数组修改为a行b列,使用的时候不需要新数组来接,直接用
- 注意:只会将形状重新排列,内部的数据顺序不会改变(不能实现转置)
import numpy as np a1 = np.array([[1,2,3],[4,5,6]]) print("-------before---------") print(a1) a1.resize((3,2)) print("-------after:a1---------") print(a1)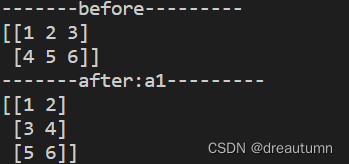
-
ndarray.T- 返回转置后的新数组
import numpy as np a1 = np.array([[1,2,3],[4,5,6]]) print("-------before---------") print(a1) a2 = a1.T print("-------after:a1---------") print(a1) print("-------after:a2---------") print(a2)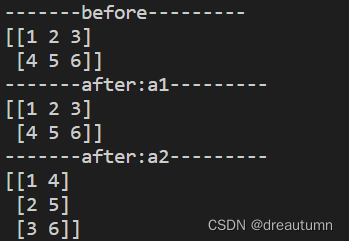
- 返回转置后的新数组
1.3.4 类型修改
ndarray.astype(type)type是类型的字符串
ndarray.tostring()序列化到本地
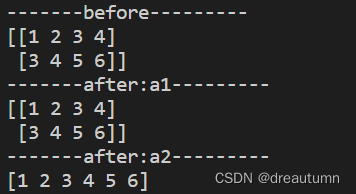
1.3.5 数组去重
import numpy as np
a1 = np.array([[1,2,3,4],[3,4,5,6]])
print("-------before---------")
print(a1)
a2 = np.unique(a1)
print("-------after:a1---------")
print(a1)
print("-------after:a2---------")
print(a2)
1.4 Ndarray运算
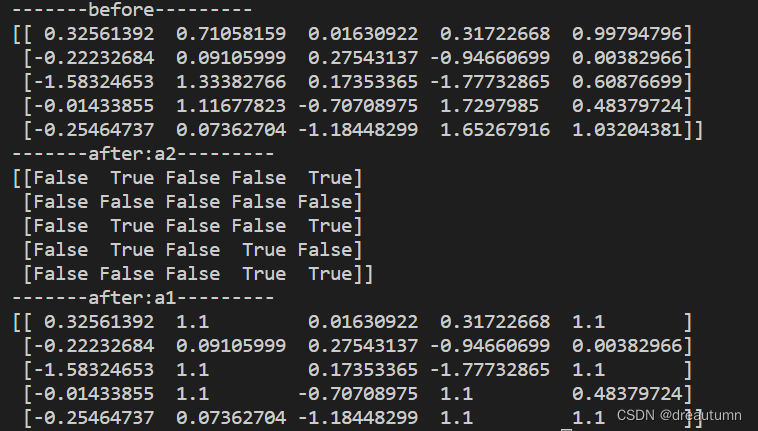
1.4.1 逻辑运算
import numpy as np
# 生成5*5的数组,每行都是正态分布
a1 = np.random.normal(loc = 0, scale= 1.0, size=(5,5))
print("-------before---------")
print(a1)
# 逻辑运算 >0.5为True,否则为False
a2 = a1 > 0.5
print("-------after:a2---------")
print(a2)
# 布尔索引,大于0.5的值都改为1.1
a1[a1 > 0.5] = 1.1
print("-------after:a1---------")
print(a1)
结果:
1.4.2 通用判断函数
-
np.all(判断条件)- 当判断条件只要有一项不满足,就返回False
- 只有当判断条件全部都满足时,才返回True
-
np.any(判断条件)- 判断条件只要有一项满足,就返回True
- 只有判断条件全部都不满足时,才返回False
-
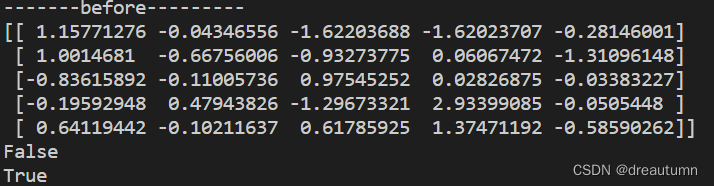
代码示例
import numpy as np # 生成5*5的数组,每行都是正态分布 a1 = np.random.normal(loc = 0, scale= 1.0, size=(5,5)) print("-------before---------") print(a1) # 判断前两行是不是全都大于零 print(np.all(a1[:2,:]>0)) # 判断后三行有没有小于零的 print(np.any(a1[3:,:]<0))结果:
1.4.3 三元运算符
-
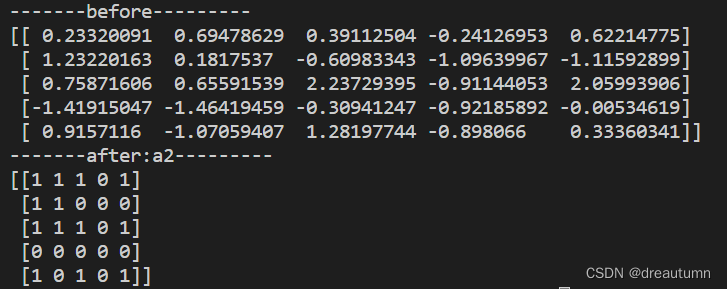
np.where(判断条件,条件成立赋值,条件不成立赋值)import numpy as np # 生成5*5的数组,每行都是正态分布 a1 = np.random.normal(loc = 0, scale= 1.0, size=(5,5)) print("-------before---------") print(a1) # a1 > 0的就赋1,小于0的就赋0 a2 = np.where(a1>0,1,0) print("-------after:a2---------") print(a2)结果:
-
复合逻辑需要结合
np.logical_and和np.logical_or使用import numpy as np # 生成5*5的数组,每行都是正态分布 a1 = np.random.normal(loc = 0, scale= 1.0, size=(5,5)) print("-------before---------") print(a1) # a1 > 0 并且 a1 < 1 的就赋1,小于0的就赋0 a2 = np.where(np.logical_and(a1 >0, a1 < 1),1,0) print("-------after:a2---------") print(a2)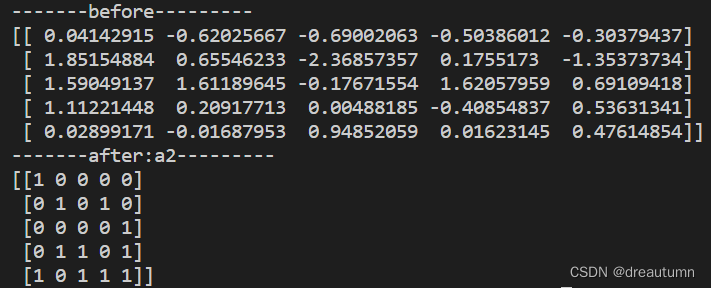
小结:
ndarray > XX 这种逻辑判断的语句可以返回一个逻辑数组,数组里面只有True或者False,代表相应位置的元素是否满足判断条件
1.4.4 统计运算
1.4.4.1 统计指标
- 统计指标两中调用方法:
np.函数名()ndarray.方法名()
- 上面的函数/方法包括
np.max()# 最小值np.min()# 最大值np.mean()# 平均值np.median()# 中位数np.var()# 方差np.std()# 标准差
- 参数axis
- 直接调用上述方法会求所有数据的最大值、最小值……
- 当出现按行/列求最大/最小……的需求时,需要用到参数
axis - axis的值对应以数组的第几维为基准进行求值,具体在用的时候可以先试试
代码示例:
import numpy as np
# 生成5*5的数组,每行都是正态分布
a1 = np.random.normal(loc = 0, scale= 1.0, size=(5,4))
print("-------before---------")
print(a1)
print(np.max(a1, axis=0))
print(a1.max(axis=1))
print(np.max(a1, axis= -1))
结果:
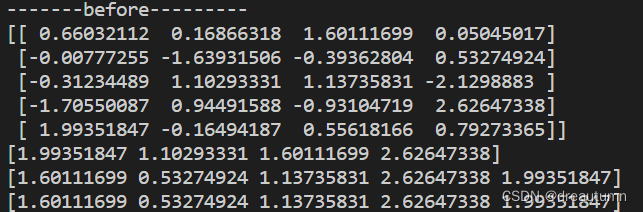
分析
- 通过结果不难看出,axis=0时,代码是按列求最大值,当axis=1或者axis=-1时,代码是按行求最大值
- 分析结果,数组a1的shape为(5,4),第一个5代表数组的第一个
[]中有5个小的[],第二个5代表第二个[]中有4个元素。所以当axis=0时,以5为维度求最大值,是对5个[]之间进行比较。当axis=1时,以4为维度求最大值,是对每个[]里面的元素求最大值。axis=-1代表维度的最后一个,在本例中跟axis=1的情况一样
1.4.4.2 返回最大值/最小值所在的位置
np.argmax(ndarray, axis= )np.argmin(ndarray, axis= )
1.5 数组间运算
1.5.1 数组与数的运算
数组与数字的加减乘除可以通过运算符号直接进行,默认对数组中的每一个数字进行操作
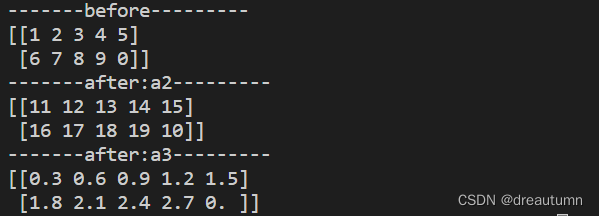
import numpy as np
a1 = np.array([[1,2,3,4,5],[6,7,8,9,0]])
print("-------before---------")
print(a1)
a2 = a1 + 10
a3 = a1 * 0.3
print("-------after:a2---------")
print(a2)
print("-------after:a3---------")
print(a3)
1.5.2 数组与数组的运算
数组与数组的运算要满足广播机制
- 执行broadcast的前提在于,两个ndarray执行的是element-wise的运算,Broadcast机制的功能是为了方便不同形状的ndarray(numpy库的核心数据结构)进行数学运算。
- 当操作两个数组时,numpy会逐个比较它们的shape(构成的元组tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算。
- 维度相等
- shape(其中相对应的一个地方为1)
以下都是可以运算的情况

代码示例(满足广播机制):
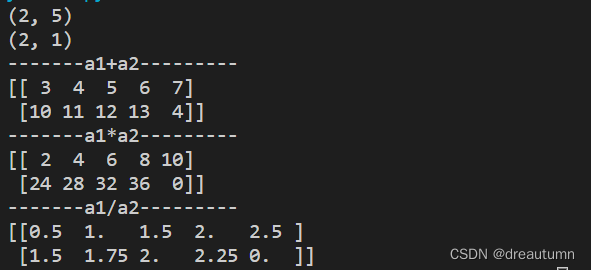
import numpy as np
a1 = np.array([[1,2,3,4,5],[6,7,8,9,0]])
a2 = np.array([[2],[4]])
print(a1.shape)
print(a2.shape)
print("-------a1+a2---------")
print(a1+a2)
print("-------a1*a2---------")
print(a1*a2)
print("-------a1/a2---------")
print(a1/a2)
结果:
1.5.3 矩阵运算
- 矩阵的存储
np.array([[a,b,c],[d,e,f]])# 还是以数组的形式存储np.mat([[a,b,c],[d,e,f]])# 以矩阵的形式存储
- 矩阵乘法
- 必须要满足矩阵的乘法规则(具体去看线代)
- 如果用ndarray的形式存储矩阵,两个乘法api:
np.matmul()np.dot()
- 如果用mat的形式存储矩阵
- 两个矩阵直接使用
*运算符
- 两个矩阵直接使用
import numpy as np
a1 = np.array([[1,2],[3,4]])
a2 = np.array([[0.3],[0.7]])
print(a1.shape)
print(a2.shape)
a1_mat = np.mat(a1)
a2_mat = np.mat(a2)
print("-------np.matmul(a1,a2)---------")
print(np.matmul(a1,a2))
print("-------np.dot(a1,a2)---------")
print(np.dot(a1,a2))
print("-------a1_mat*a2_mat---------")
print(a1_mat*a2_mat)

1.6 合并、分割
1.6.1 合并
np.hstack(元组)# 水平合并np.vstack(元组)# 垂直合并np.concatenate(元组, axis=)# 指定方向进行拼接
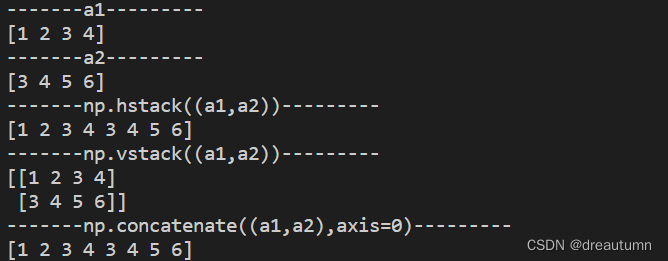
import numpy as np
a1 = np.array([1,2,3,4])
a2 = np.array([3,4,5,6])
print("-------a1---------")
print(a1)
print("-------a2---------")
print(a2)
print("-------np.hstack((a1,a2))---------")
print(np.hstack((a1,a2)))
print("-------np.vstack((a1,a2))---------")
print(np.vstack((a1,a2)))
print("-------np.concatenate((a1,a2),axis=0)---------")
print(np.concatenate((a1,a2),axis=0))
注意:上面两个数组用concatenate合并,axis只能等于0(暂不知道为啥)
1.6.2 分割
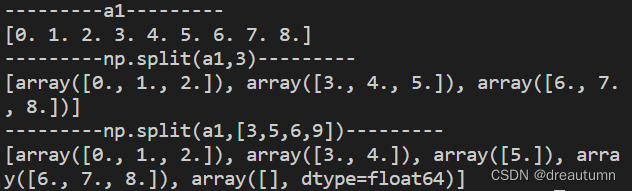
import numpy as np
a1 = np.arange(9.0)
print("---------a1---------")
print(a1)
print("---------np.split(a1,3)---------")
print(np.split(a1,3))
print("---------np.split(a1,[3,5,6,9])---------")
print(np.split(a1,[3,5,6,9]))
1.7 IO操作与数据处理
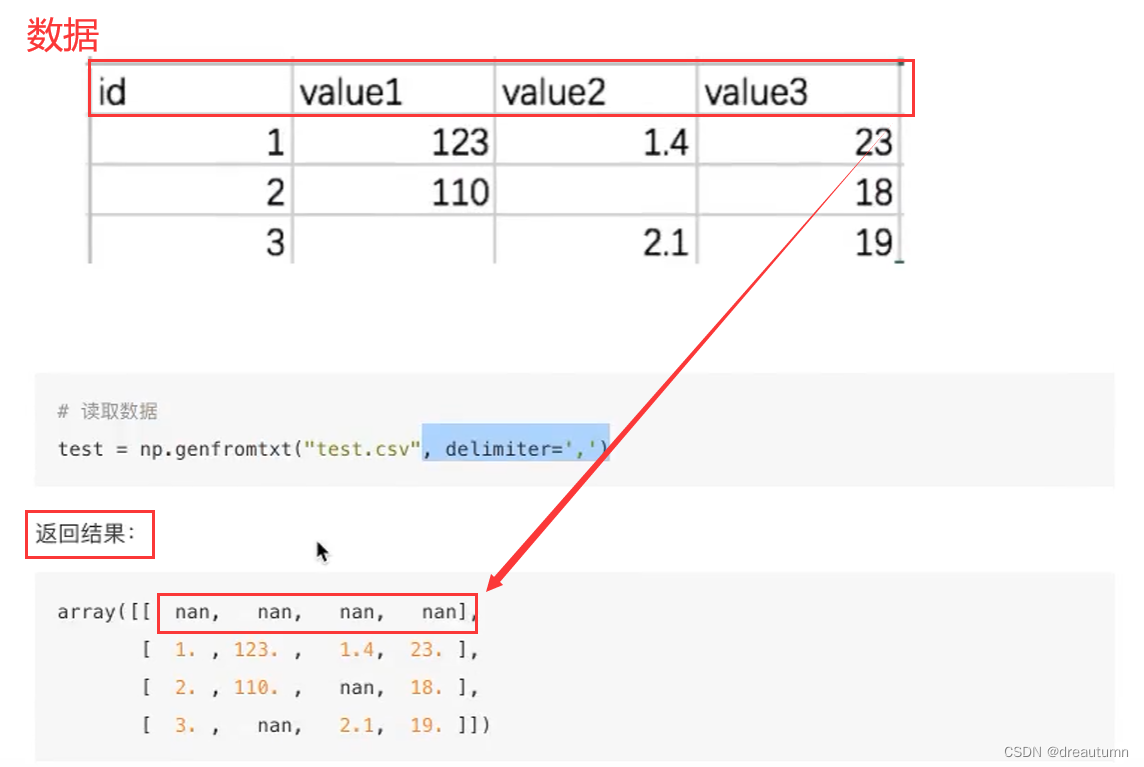
1.7.1 Numpy读取文件
text = np.genfromtxt("文件路径", delimiter="分隔符")
注意:numpy不能处理字符串,因此当数据中有字符串时会返回nan,因此一般也不用numpy读取文件
1.7.2 缺失值处理
建议使用pandas
2 Pandas
2.1 Pandas介绍
- Panel + Data + Analysis 面板数据研究
- 数据处理的python库
- 集成了Numpy和Matplotlib
- pandas的优点:
- 便捷的数据处理能力
- 读取文件方便
- 封装了matplotlib和numpy的画图和运算
- pandas三大核心数据结构
- DataFrame
- Panel
- Series
2.1.1 DataFrame
- 既有行索引也有列索引的二维数组
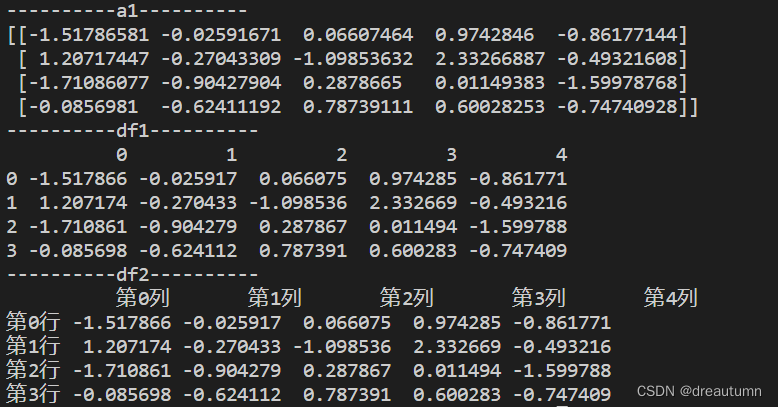
df = pd.DataFrame(array, index=行索引, column=列索引)
import pandas as pd
import numpy as np
a1 = np.random.normal(0,1.0,(4,5))
print("----------a1----------")
print(a1)
df1 = pd.DataFrame(a1)
print("----------df1----------")
print(df1)
# 添加行索引
INDEX = ["第{}行".format(i) for i in range(4)]
# 添加列索引
COLUMN = ["第{}列".format(i) for i in range(5)]
df2 = pd.DataFrame(a1, index=INDEX, columns= COLUMN)
print("----------df2----------")
print(df2)
2.1.2 DataFrame的属性
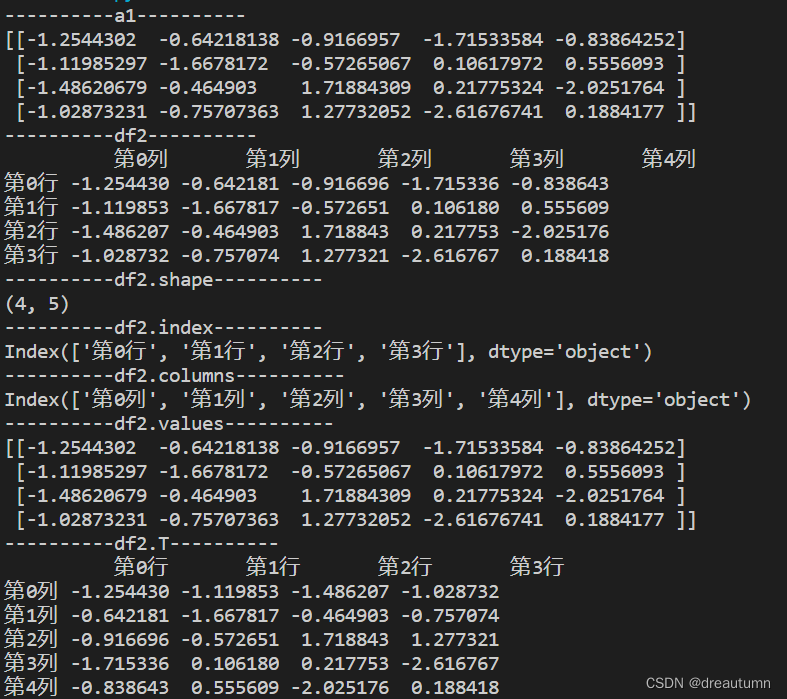
df.shape# 形状df.index# 行索引df.columns# 列索引df.values# 去掉行索引和列索引的部分,就是一个ndarraydf.T# 转置,行列互换
补充两个常用方法:
df.head(a)# 返回数据的前a行,默认前5行df.tail(a)# 返回数据的后a行。默认后5行- 以上两个函数可以用于快速的浏览数据整体结构,查看一下行列标签等
import pandas as pd
import numpy as np
a1 = np.random.normal(0,1.0,(4,5))
print("----------a1----------")
print(a1)
# 添加行索引
INDEX = ["第{}行".format(i) for i in range(4)]
# 添加列索引
COLUMN = ["第{}列".format(i) for i in range(5)]
df2 = pd.DataFrame(a1, index=INDEX, columns= COLUMN)
print("----------df2----------")
print(df2)
print("----------df2.shape----------")
print(df2.shape)
print("----------df2.index----------")
print(df2.index)
print("----------df2.columns----------")
print(df2.columns)
print("----------df2.values----------")
print(df2.values)
print("----------df2.T----------")
print(df2.T)
2.1.3 DataFrame的索引设置
- 修改行列索引值
- 索引值不支持单独修改,只能全部修改
- 如:修改行索引
df.index = [新的索引值]
- 重设索引
df.reset_index(drop=True/False)drop默认为False,不删掉原来的索引,原来的行索引被当作是第一列drop=True,删除原来的行索引
- 设置新索引
df.set_index(keys, drop=True)- keys:列索引名或者列索引名称的列表
- drop:默认为True,把用来当作索引的那一列从原数据中删除
- 代码示例:
import pandas as pd import numpy as np df = pd.DataFrame({'month':[1,4,7,10], 'year':[2012,2013,2014,2015], 'scale':[55,56,78,36]}) print("--------df-------") print(df) df_Ture = df.set_index("month", drop=True) print("--------df_True-------") print(df_Ture) df_False = df.set_index("month",drop=False) print("--------df_False-------") print(df_False) df_Mul = df.set_index(["month", "year"]) print("--------df_Mul-------") print(df_Mul) print(df_Mul.index)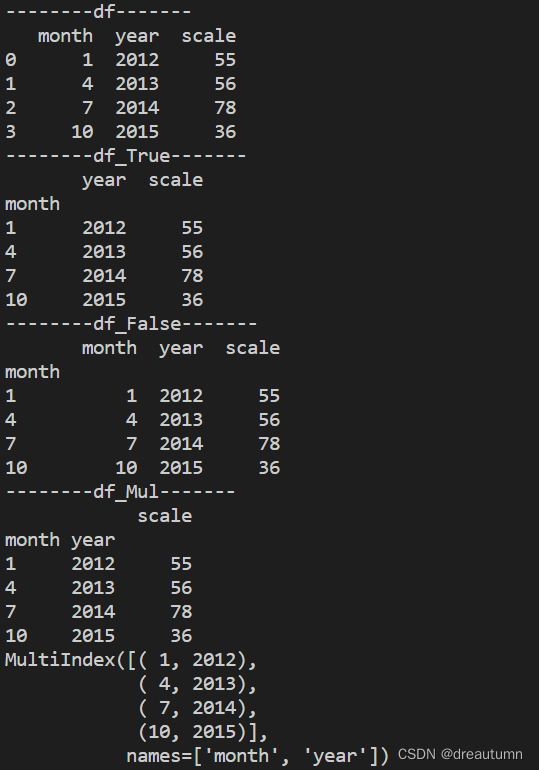
2.1.4 MultiIndex与Panel
- MultiIndex
- 如果给一个DataFrame设置多个索引,则可以看作是一个带MultiIndex的DataFrame,可以用来存储三维数据
- 如果一个index是MultiIndex,则这个index还有两个属性
df.index.names# 各个索引的名称是什么df.index.levels# 各个索引的值是什么
- Panel
- 用于存储三维数据的数据结构
- 注意:Pandas从版本0.20.0开始弃用Panel:推荐的用于表示3D数据的方法是DataFrame上的Multilndex方法
2.1.5 Series
- 带索引的一维数组,即从DataFrame中取取某一行或某一列得到的数据
- series结构只有行索引
- 属性
sr.index# 索引名称sr.values# 去掉索引的一位ndarray
- 方法
sr=pd.Series([数据], index=[索引])# 创建Seriessr=pd.Series({字典})# 通过字典创建Series
2.2 基本数据操作
2.2.1 索引操作
- 直接索引
- 必须先列后行 进行索引
df["列索引"]["行索引"]
- 按名字索引
- 结合loc使用索引
df.loc["行索引","列索引"]
- 按数字索引
- 结合iloc使用索引
df.iloc[a, b]a和b为对应的行列数字值
- 组合索引
- 使用ix组合索引
df.ix[0:4,[列索引名1, 列索引名2, ...]]- 注意:组合索引的方法在最新版的Python中已经取消
- 曲线救国:使用loc或者iloc实现组合索引
df.loc[df.index[0:4], [列索引名1, 列索引名2, ...]]df.iloc[0:4, df.columns.get_indexer([列索引名1, 列索引名2, ...])]
代码示例:
import pandas as pd
import numpy as np
a1 = np.random.normal(0,1.0,(4,5))
# 添加行索引
INDEX = ["第{}行".format(i) for i in range(4)]
# 添加列索引
COLUMN = ["第{}列".format(i) for i in range(5)]
df = pd.DataFrame(a1, index=INDEX, columns= COLUMN)
print("-------df-------")
print(df)
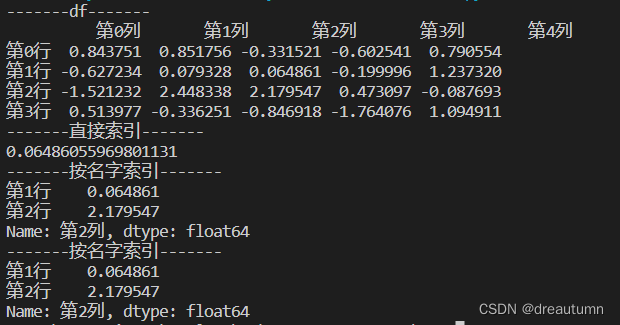
print("-------直接索引-------")
print(df["第2列"]["第1行"])
print("-------按名字索引-------")
print(df.loc[["第1行","第2行"],"第2列"])
print("-------按名字索引-------")
print(df.iloc[1:3,2])
结果
2.2.2 赋值操作
- 对某一列所有的值进行统一赋值
df.列索引名 = 新值df[列索引名] = 新值
- 对某一个值进行赋值操作
- 用上述索引方法找到相应的值,然后直接使用
=进行赋值
- 用上述索引方法找到相应的值,然后直接使用
2.2.3 排序
- 对内容进行排序
df.sort_values(by='列索引名', ascending=)ascending = True升序排列ascending = False降序排列
- 排序基准为多个关键词时
df.sort_values(by=['列索引名1', '列索引名2', ...], ascending=)
- 对索引排序
df.sort_index()
2.3 DataFrame运算
2.3.1 算数运算
- 使用运算符(加减乘除)
- 索引到所需要的运算级别(DataFrame->Serise->具体值)
- 使用运算符直接运算,如
df.iloc[2,3] = df.iloc[2,3] + 10
- 使用运算函数
- 索引到所需要的运算级别(DataFrame->Serise->具体值)
- 使用运算函数进行运算
.add().sub()
- 使用运算函数的好处是可以继续在后面加
.,比如df.add(10).head()
2.3.2 逻辑运算
- 逻辑运算符
<, >, |, &- 与numpy类似,也可以进行布尔索引(即以某个行/列的值作为条件,筛选出dataframe满足行要求的行/列)
- 代码示例(单个条件)
import pandas as pd import numpy as np a1 = np.random.normal(0,1.0,(4,5)) # 添加行索引 INDEX = ["第{}行".format(i) for i in range(4)] # 添加列索引 COLUMN = ["第{}列".format(i) for i in range(5)] df = pd.DataFrame(a1, index=INDEX, columns= COLUMN) print("-------df-------") print(df) print("-------逻辑运算-------") print(df["第2列"]>0) print("-------布尔运算-------") print(df[df["第2列"]>0]) - 结果
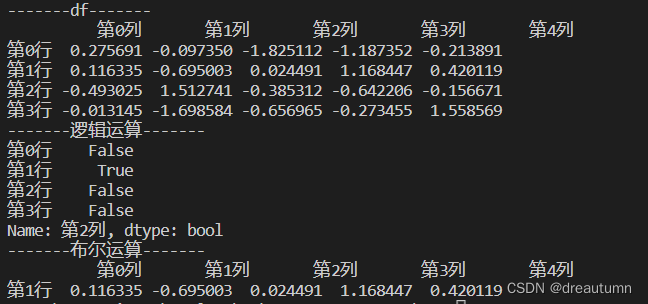
返回了满足第2列数据>0的所有数据 - 代码示例(多个判断条件)
import pandas as pd import numpy as np a1 = np.random.normal(0,1.0,(7,5)) # 添加行索引 INDEX = ["第{}行".format(i) for i in range(7)] # 添加列索引 COLUMN = ["第{}列".format(i) for i in range(5)] df = pd.DataFrame(a1, index=INDEX, columns= COLUMN) print("-------df-------") print(df) print("-------逻辑运算-------") print((df["第2列"]>-0.5) & (df["第3列"]< 0.5)) print("-------布尔运算-------") print(df[(df["第2列"]>-0.5) & (df["第3列"]< 0.5)]) - 结果
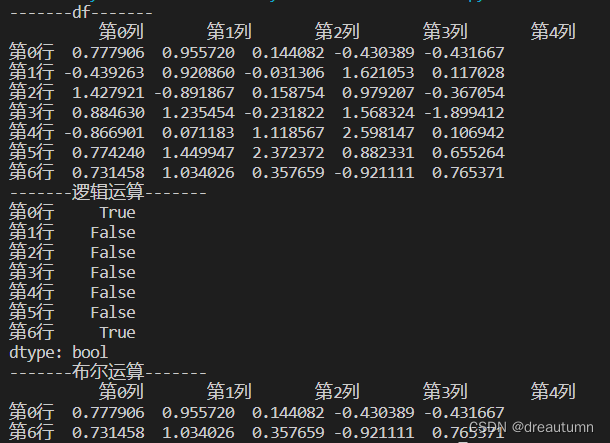
- 逻辑运算函数
query(expr)好用,推荐!- expr:查询字符串,要实现上面的效果,只需要编写一个字符串即可
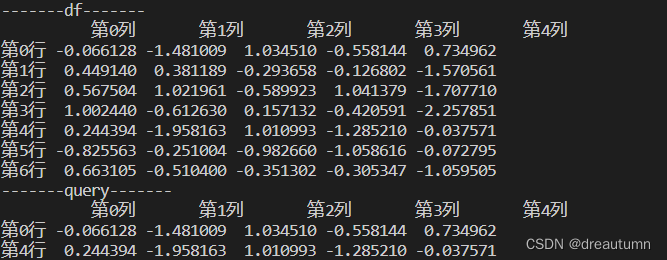
- 代码示例
import pandas as pd import numpy as np a1 = np.random.normal(0,1.0,(7,5)) # 添加行索引 INDEX = ["第{}行".format(i) for i in range(7)] # 添加列索引 COLUMN = ["第{}列".format(i) for i in range(5)] df = pd.DataFrame(a1, index=INDEX, columns= COLUMN) print("-------df-------") print(df) print("-------query-------") print(df.query("第2列 > 0 & 第3列 < -0.5")) - 图片
isin()- 判断一组数中是否有某些值
- 逻辑判断
df[列索引名].isin([值1, 值2, 值3]) - 布尔索引
df[df[列索引名].isin([值1, 值2, 值3])]
2.3.3 统计运算
count,mean,std,min,max等idnmax(),idxmin()返回最大值、最小值的索引- 上述两中API都有一个参数
axis,默认为0表示按列进行运算,当axis=1时表示按行进行运算,但是一般也没有什么实际意义 describle()- 综合分析,能够直接得出上述统计 结果
- 代码示例
import pandas as pd import numpy as np a1 = np.random.normal(0,1.0,(7,5)) # 添加行索引 INDEX = ["第{}行".format(i) for i in range(7)] # 添加列索引 COLUMN = ["第{}列".format(i) for i in range(5)] df = pd.DataFrame(a1, index=INDEX, columns= COLUMN) print("-------df-------") print(df) print("-------df.describe()-------") print(df.describe()) - 结果
2.3.4 累计统计函数
cumsum累加,计算前n个数的和cummax累计求最大,计算前1、2、3……n个数的最大值cummin累计求最小,计算前1、2、3……n个数的最小值cumprod累乘,计算前n个数的积- 使用方法:
- 在DataFrame中拿出一个Series后面
.函数名()即可
- 在DataFrame中拿出一个Series后面
2.3.5 自定义运算
apply(func, axis=0)- func: 自定义函数
- axis=0 默认是按列进行运算,axis=1为按行进行运算
- 例子:设计一个函数,计算每一列的最大值和最小值之差
df.apply(lambda x: x.max() - x.min())
2.4 Pandas画图
2.4.1 pandas.DataFrame.plot
DataFrame.plot (x=None,y=None,kind='line')- x: label or position,default None
- y: label,position or list of label,positions,default None
- Allows plotting of one column versus another
- kind: str
- ‘line’: line plot(default)
- ‘bar’: vertical bar plot
- ‘barh’: horizontal bar plot
- ‘hist’: histogram
- ‘pie’: pie plot
- ‘scatter’: scatter plot
2.4.2 pandas.Series.plot
2.5 文件读取与存储
2.5.1 csv文件的读取与存储
pandas.read_csv(filepath_or_buffer, sep=',',delimiter=None)- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式
- names:一个字符串列表,用于指定列索引名称
DataFrame.to_csv(path_or_buf=None, sep=',', columns=None, header=True, index=True, index_label=None, mode='w',encoding=None)- path_or_buf: 文件路径
- sep:分隔符,默认为
, - columns:选择要写进文件的是哪几列
- mode:
w:重写,a:追加 - index:是否写进行索引
- header:是否写进列索引
4.5.2 HDF5文件的读取与存储
4.5.3 Json文件的读取与存储
pandas_read_json(path)- orient=“records”
- lines:布尔值,是否按照每行读取json对象,默认为False,一般得改成True
DataFrame.to_json(path)- orient=“records”
- lines:布尔值,是否按照每行读取json对象,默认为False,一般得改成True















 2306
2306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











