






选择性除氟树脂,填补污水除氟领域技术空缺
含氟工业废水治理是众多企业目前关注的热点问题。随着工业生产的加剧,高浓度含氟工业废水排放的现象也日益增多,且屡禁不止。含氟工业废水往往含有呈氟离子(F-)形态的氟,目前国内的企业在污水除氟方面不具备相应的设备条件和工艺技术,导致大多数企业在含氟废水的处理上不达标、做不到深度处理以及提标改造。
煤矿矿井水、煤化工行业、光伏行业、氟化工行业、金属冶炼行业、电镀行业、电子工业等行业均有含氟废水产生并需做相应的深度处理方可排放或回用,这些企业含氟废水氟浓度一般均在10mg/l以上。若处理不达标,不仅污染环境,也威胁着人类健康。并且因为行业性质不同,企业所处地域不同,对于氟化物的处理达标执行标准也有所区别,目前最严的是做到1mg/l以下。
设备、技术不成熟,国内污水除氟工艺尚不完善
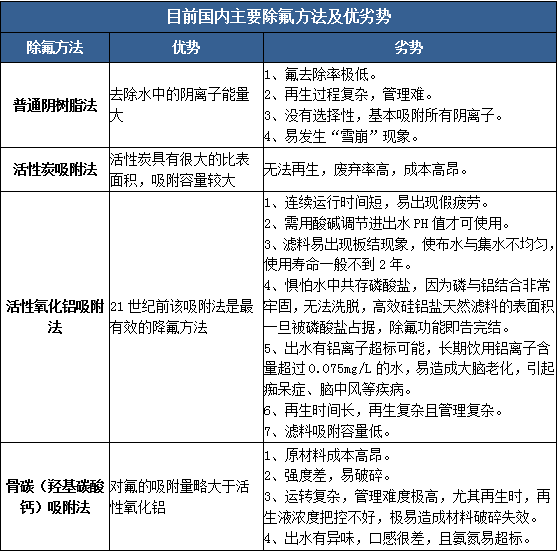
吸附法、沉淀法是当前我国工业含氟废水处理常用的两种办法。吸附法多用于饮用水等净水的处理,沉淀法则用于处理工业含氟废水。如下表中提到的活性氧化铝,羟基磷灰石,碳基磷灰石等吸附型材料最初都是用于净水中除氟,但也因它们很明显的缺陷(如:产水铝超标、再生操作复杂、吸附容量小、机械强度差、出水有异味等),在饮用水行业,铝系除氟材料的应用前景较为可疑,羟基磷灰石也已基本不采用。
工业含氟污水处理中之所以目前还有使用这些材料的项目或企业,首先是因为这些材料对于低浓度(<2mg/l的)的氟能够勉强做到达标(即使再生等很复杂,很麻烦);其次是因为污水除氟领域技术和设备尚不成熟,可选的可行工艺不多,但从当前国内工业废水除氟项目整体情况来看,活性氧化铝、羟基磷灰石、碳基磷灰石等材料实用性较差,均不适用于工业含氟废水的深度处理。
特种树脂深度除氟,精度高成本低易管理
针对国内现有工业含氟废水深度处理工艺技术跟不上的局面,CH-87选择性除氟特种树脂。它是一款去除水溶液中氟离子专用的螯合型选择性离子交换树脂,在中性至碱性的PH(7-11)范围内有极高的工作效率,并且极易再生。
CH-87特种除氟树脂:
1、处理精度高,可达到1ppm以下,稳定达标;
2、吸附量大,对于氟化物实际操作交换量能够达到6-8g/l;
3、选择性除氟,树脂可以在高盐环境运行,对氟的交换量不受水中硫酸盐含量的影响;
4、专门开发用于污水除氟的特种离子交换树脂;
5、模块组件形式,自动化程度高,操作简单。
填补国内行业技术空缺,应用场景广泛
CH-87特种除氟树脂目前在煤矿矿井水、煤化工行业、深井水行业、光伏行业、氟化工行业、金属冶炼行业、电镀行业、含氟矿物开采等多个行业均有广泛应用,在各行业含氟废水的深度处理上取得了良好的成效,已有众多成功案例,得到了工程公司及终端业主的一致好评。

















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









