







前言
最近一直在研究组合优化问题,上周看到2019年NeurIPS会议上有篇文章提出了一种端到端的学习和优化框架,并且开源了代码,于是复现了一下,发现在社区检测任务上的效果真的不错,而且方法非常简单。
NeurIPS 2019:图上端到端的学习和优化
End to end learning and optimization on graphs
GitHub源码
组合优化
图中的很多问题都是组合优化问题,比如最大独立集、最小覆盖集、图分割、最短路等等。很多组合优化问题都是NP难问题,不存在多项式时间复杂度的求解算法,所以传统多是用贪婪算法或者启发式算法(比如遗传算法、粒子群算法等等)来求解。
最近,很多研究人员尝试用深度学习或者强化学习来解决组合优化问题,这几年相关研究也经常出现在IAAA、NIPS这样的顶会上。我在之前的一篇博客中整理一些代表性研究(包含文章及代码链接),感兴趣的可以移步看看。
社区检测
社区检测是网络科学中的一个经典问题了,其目的是发现网络中的社区结构。社区结构一般是指网络中一些内部联系非常紧密的子图,这些子图往往具有一些特定的功能或者属性。当然,社区结构有很多种,比如层次社区结构、重叠社区结构等等,这方面的文章有不少是发表在《Nature》《Science》这样级别的期刊上的。想深入了解社区检测问题可以看看下面几篇文章。
Finding and evaluating community structure in networks (2003)
Modularity and community structure in networks (2006)
Community detection in graphs (2009)
Community detection algorithms: a comparative analysis (2009)
Community detection in networks: A user guide (2016)
我之前也写了一篇关于社区检测的文章,里面给出了社区可视化的代码,用python3和networkx包实现的。
大多数社区检测算法都将模块度作为优化函数,其目的就是寻找一种最优划分将所有节点分配到不同的社区中,使得模块度值最大。因此,社区检测问题本质上也是一个组合优化问题。
下面就逐步介绍一下这篇文章的主要研究内容。
端到端的学习与优化
作者介绍
这篇文章发表在2019年的NeurIPS会议上。四位作者分别来自哈佛大学和南加州大学,其中一作Bryan Wilder是即将毕业的博士生,非常厉害,博士期间发表了很多高质量文章,其个人主页上有详细介绍。Bistra Dilkina是南加州大学的副教授,发表过很多关于组合优化问题的文章,如经典文章 Learning combinatorial optimization algorithms over graphs。

核心思想
许多实际应用同时涉及到图上的学习问题与优化问题,传统的做法是先解决学习问题然后再解决优化问题,这样有个缺点就是下游优化的结果无法反过来指导学习过程,实现不了学习与优化的协同改善。文章的目的就是提出一种端到端的框架,将学习过程和优化过程合并在一个网络中,这样最终优化任务的误差可以一直反向传播到学习任务上,网络参数就可以一起优化,改善模型在优化任务上的性能。
技术手段
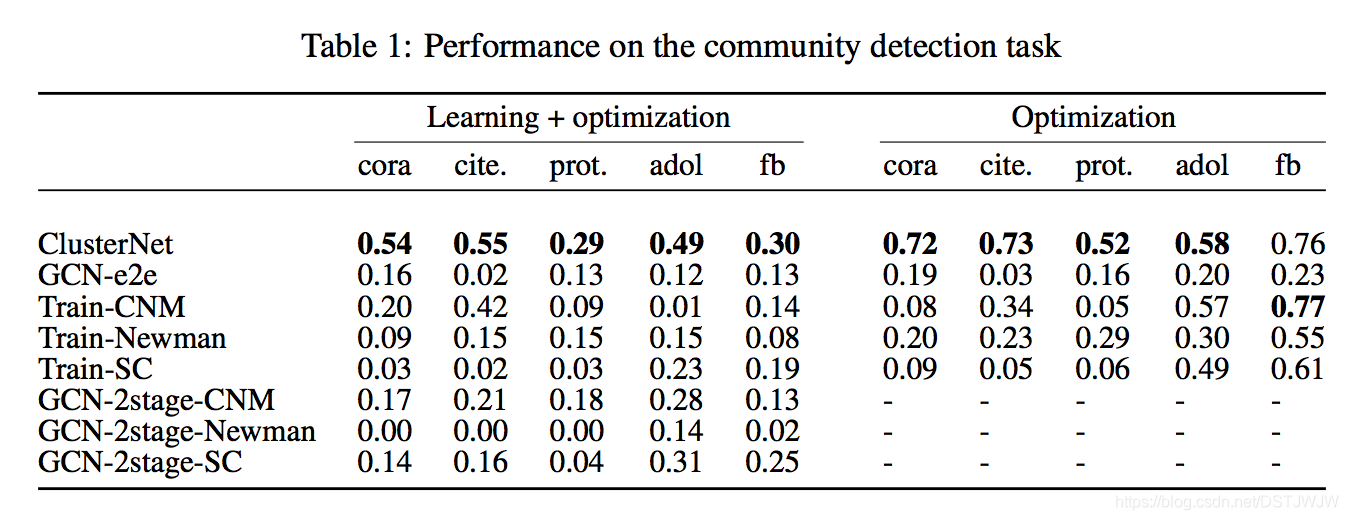
这篇文章以链路预测作为学习问题的代表,以社区检测为优化问题的代表来开展研究。具体上,文章假定在进行社区检测之前,网络结构不是完全已知的,只有部分(40%)网络结构是能够观察到的,所以要先用链路预测来找出出网络中那些没有被观察到的连边,然后再在这种“复原”后的网络上进行社区检测,利用模块度指标来评估社区检测的效果。同时,文章还设立了对照实验,即在原始网络(不隐藏任何连边)上执行社区检测任务,通过观察两组实验的结果来分析他们提出的模型的有效性。
方法创新
文章提出了一种新的端到端的网络模型(ClusterNet),其中主要包含四个步骤:
- 基于GCN的节点嵌入
- 基于K-means的节点聚类
- 作出决策并计算当前的解的损失
- 误差的反向传播和参数优化
整个模型框架如下图所示,上面是ClusterNet,下面是两阶段优化模型。
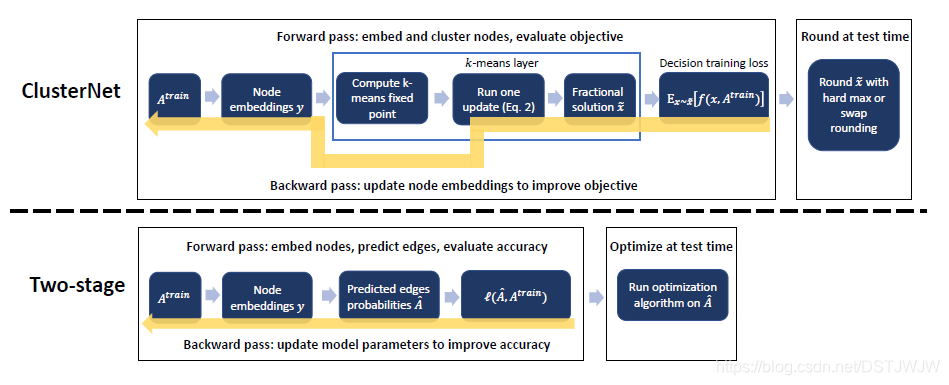
其中关键在于决策和误差反向传播。
针对不同的优化任务,决策函数是不一样的,而且训练阶段和测试阶段也有些不同。本文只介绍社区检测这一任务,在训练阶段,节点聚类的结果是概率值,被当做社区的软划分,这样计算梯度更准确,有利于参数优化;而在测试阶段(推理过程),对节点聚类的结果进行softmax操作就可以得到社区的硬划分(二值化),这样可以计算出最终的模块度值。
在误差反向传播过程中,有两个影响优化效果的重要参数,一个是 β \beta β,即聚类分配的严格程度(hardness), δ \delta δ,即类别之间的区分程度。这两个参数的乘积决定了社区划分的效果,一般情况下,大一些比较好。在代码中,这两个参数只用其乘积一个参数来代表了。

作者们还证明了该模型可以通过梯度下降来寻优,并推导出了参数的梯度计算公式。对公式感兴趣的可以去看原文。
除了决策和参数优化之外,K-means聚类的作用也是极为重要的。如果没有中间聚类这一步的话,效果是要大打折扣的。对于社区检测任务来说,如果去掉中间的聚类层,那么最后的结果基本上都是将所有节点都分配到同一个社区,这样网络中全部边都在社区内部,也算是最优了,但是没有任何意义。文中也特意设计了一种直接优化的方法(不含聚类层),也就是GCN-e2e方法,可以看出其效果比ClusterNet要差很多。
代码复现
下面,就一步一步复现一下文中的代码。
导入包
import numpy as np
import sklearn
import sklearn.cluster
import scipy.sparse as sp
import math
import torch
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.parameter import Parameter
数据转换
将networkx中的graph对象转换为网络要求的输入,输入数据有两个,一个是归一化后的邻接矩阵(稀疏矩阵),一个是节点的特征矩阵(没有特征的图默认为单位矩阵)。
## Data handling
def normalize(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1), dtype=np.float32)
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def mx_to_sparse_tensor(mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
mx = mx.tocoo().astype(np.float32)
indices = torch.from_numpy(np.vstack( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2267
2267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









