









利用Eclipse构建Spark集成开发环境
1.安装Scala
ubuntu下安装Scala以前已经实现过,我博客中有相关记载,这里不再赘述,可以参考该网址http://blog.csdn.net/dubo160/article/details/44962043进行Scala的安装。
2.构建Spark集成开发环境
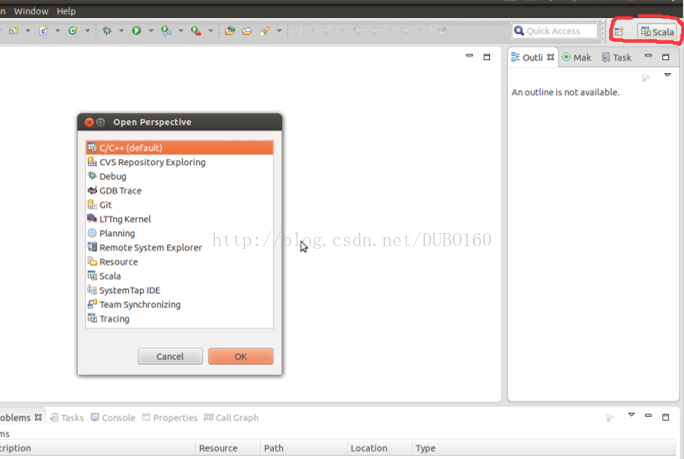
(1)重新启动Eclipse,点击eclipse右上角方框按钮,如下图所示,展开查看是否有“Scala”一项,有的话,直接点击打开,否则进行(2)操作。
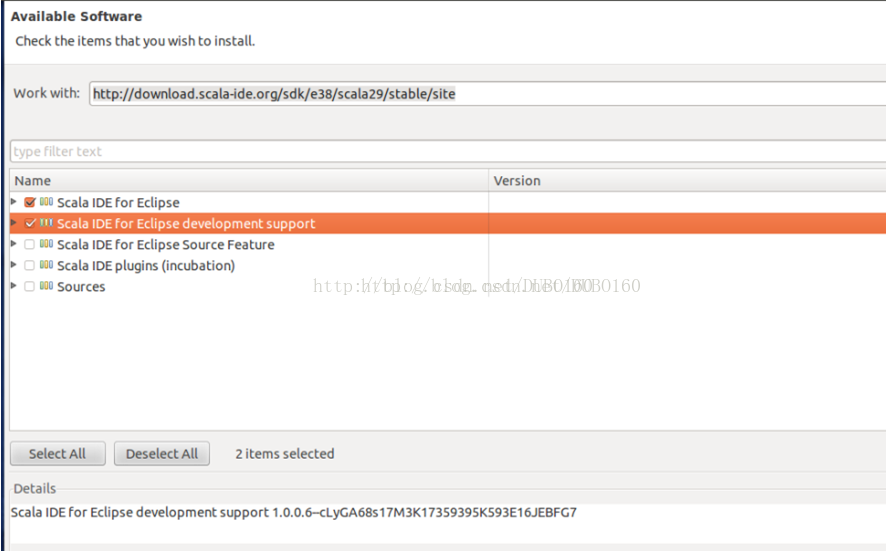
(2)在Eclipse中,依次选择“Help” –> “Install New Software…”,在打开的卡里填入http://download.scala-ide.org/sdk/e38/scala29/stable/site,并按回车键,可看到以下内容,选择前两项进行安装即可。安装完后,重复操作一遍(1)便可。
3.使用Scala语言开发Spark程序
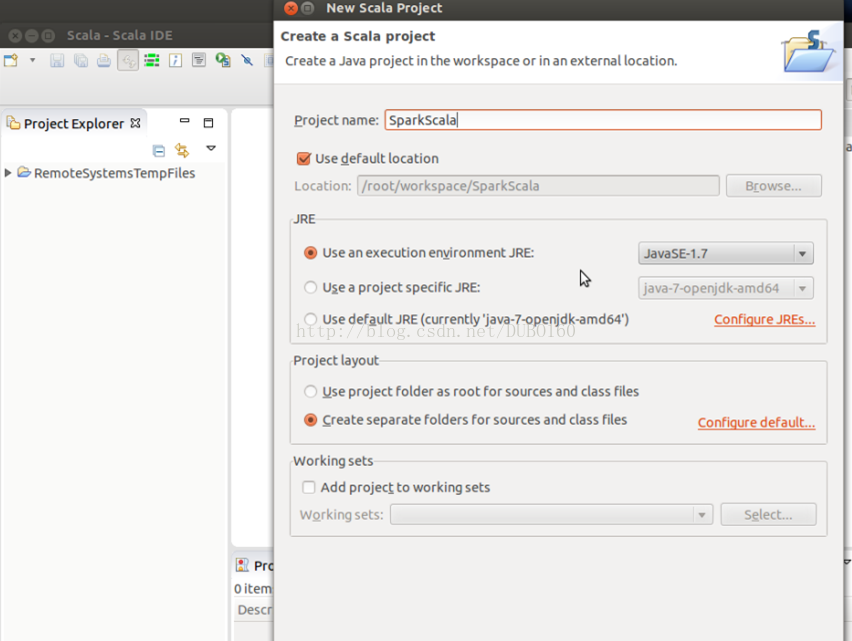
在eclipse中,依次选择“File” –>“New” –> “Other…” –> “Scala Wizard” –> “Scala Project”,创建一个Scala工程,并命名为“SparkScala”。

4.下载编译spark
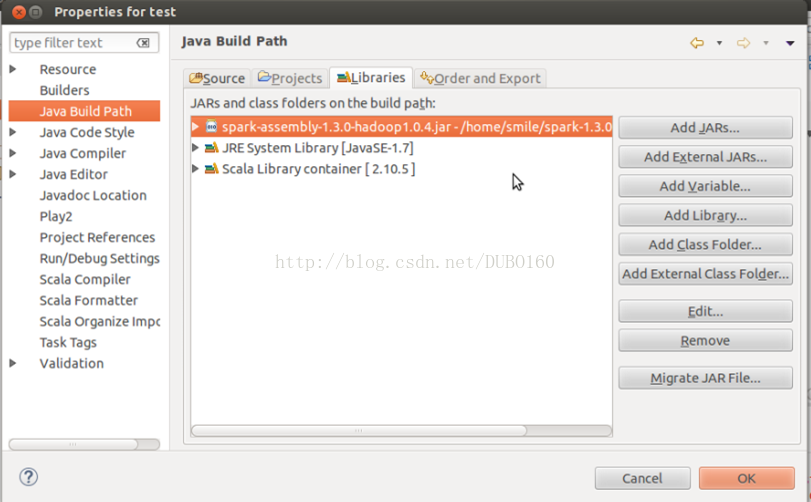
右击“SaprkScala”工程,选择“Properties”,在弹出的框中,按照下图所示,依次选择“Java Build Path” –>“Libraties” –>“Add External JARs”,导入spark安装目录下的spark-1.3.0-bin-hadoop1\lib\spark-assembly-1.3.0-hadoop1.0.4.jar
5.增加一个Scala Object
跟创建Scala工程类似,在工程中增加一个Scala object,命名为:WordCount。
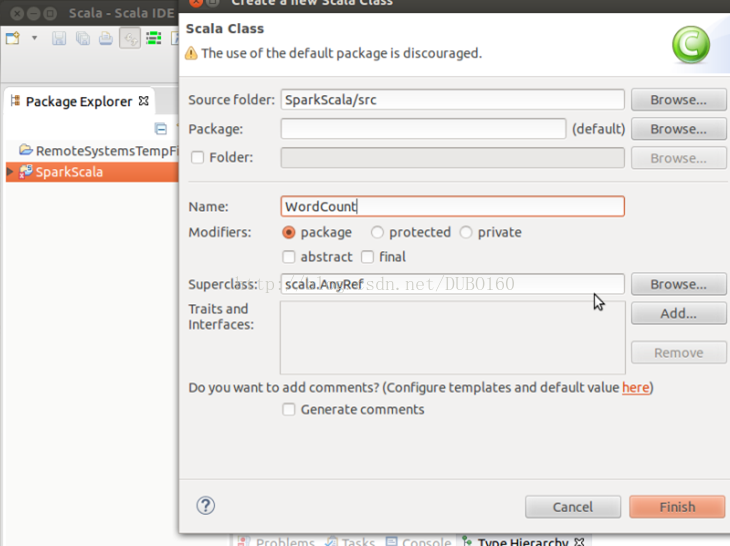
WordCount就是最经典的词频统计程序,它将统计输入目录中所有单词出现的总次数,Scala代码如下(这个代码没有进行测试,测试的是spark中自带的代码SparkPi.scala):
<div style="text-align: justify;"><span style="font-family: 宋体; font-size: 14px;">import org.apache.spark._ </span></div><div style="text-align: justify;"><span style="font-size: 14px;">import SparkContext._ </span></div><div style="text-align: justify;"><span style="font-family: 宋体; font-size: 14px;"> def main(args: Array[String]) { </span></div><div style="text-align: justify;"><span style="font-size: 14px;">object WordCount { </span></div><div style="text-align: justify;"><span style="font-family: 宋体; font-size: 14px;"> println("usage is org.test.WordCount <master> <input> <output>") </span></div><div style="text-align: justify;"><span style="font-size: 14px;"> if (args.length != 3 ){ </span></div> return
<div style="text-align: justify;"><span style="font-family: 宋体; font-size: 14px;"> val sc = new SparkContext(args(0), "WordCount", </span></div> }
<div style="text-align: justify;"><span style="font-family: 宋体; font-size: 14px;"> System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR"))) </span></div> val textFile = sc.textFile(args(1))
<div style="text-align: justify;"><span style="font-family: 宋体; font-size: 14px;"> .map(word => (word, 1)).reduceByKey(_ + _) </span></div> val result = textFile.flatMap(line => line.split("\\s+"))
result.saveAsTextFile(args(2))
} <span style="font-size: 14px;">} </span>6.测试
按照上面方法我新建了一个test的工程,运行的代码是spark中本身自带的一个例子。
位置:spark-1.3.0-bin-hadoop1\examples\src\main\scala\org\apache\spark\examples\SparkPi.scala















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









