






Python实现BlazePose姿态特征点检测代码(图像、视频、数据流)
文章目录
写这个博客主要是mediapipe上有BlazePose针对图像姿态估计的方法,其他包括视频、数据流的示例代码则空缺,今天就把我学习的过程和整个BlazePose在Python上的实现进行归纳总结,希望对你有所帮助。
姿态识别介绍
- 简介:姿态识别是一种计算机视觉技术,用于检测和分析人类或物体的姿势和动作。涉及从图像或视频中捕捉关节和肢体的位置信息,并将其转换为可解释的姿态数据。
- 应用:
- 运动分析:用于运动员的动作分析和纠正,提高训练效果。
- 虚拟现实和增强现实:通过捕捉用户的动作,使虚拟世界中的角色能够实时响应用户的动作。
- 智能监控:用于监控系统中识别人类的异常行为,例如跌倒检测。
- 人机交互:用于手势识别,使计算机或机器人能够通过识别用户的手势进行交互。
- 康复医疗:帮助医生监控和分析患者的恢复情况,提供更精确的康复指导。
- 姿态作画:通过捕捉和描绘人体或物体的动态姿态作为输入,创造出富有表现力和动感的作品。
BlazePose介绍
- 简介(一个字,快!):
- BlazePose是一个轻量化的,可应用于Python、Web以及移动设备的人体姿态估计网络,能够实现实时的姿态估计。
- 输入的形式包括图像、视频以及各种实时的摄像头、手机摄像头等。
- 可以实现多人的姿态识别
- 视频和数据流输入的过程中增加目标追踪方法从而实现更快速的姿态估计。
- 论文及团队详情:
- 研发团队:google research
- 论文出处:2020CVPR Workshop
- 论文链接:https://arxiv.org/pdf/2006.10204.pdf
- 论文代码:https://google.github.io/mediapipe/solutions/pose.html
BlazePose图像姿态识别
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import numpy as np
import mediapipe as mp
import cv2
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
def draw_landmarks_on_image(rgb_image, detection_result):
pose_landmarks_list = detection_result.pose_landmarks
annotated_image = np.copy(rgb_image)
print(rgb_image.shape)
# Loop through the detected poses to visualize.
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
# Draw the pose landmarks.
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
# STEP 2: Create an PoseLandmarker object.
base_options = python.BaseOptions(model_asset_path='pose_landmarker.task') # 需要提前下载好模型 填入模型地址
options = vision.PoseLandmarkerOptions(
num_poses=7,
base_options=base_options,
output_segmentation_masks=True)
detector = vision.PoseLandmarker.create_from_options(options)
# STEP 3: Load the input image.
image = mp.Image.create_from_file("img_1.png") # 你的图片路径输入
# STEP 4: Detect pose landmarks from the input image.
detection_result = detector.detect(image)
# STEP 5: Process the detection result. In this case, visualize it.
annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result)
cv2.imshow("new_image", cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))
cv2.waitKey(0)
BlazePose视频姿态识别
- 实现视频的姿态识别并保存结果
from mediapipe import solutions
from mediapipe.tasks import python
from mediapipe.framework.formats import landmark_pb2
from mediapipe.tasks.python import vision
import mediapipe as mp
import cv2
import numpy as np
def draw_landmarks_on_image(rgb_image, detection_result):
pose_landmarks_list = detection_result.pose_landmarks
annotated_image = np.copy(rgb_image)
print(rgb_image.shape)
# Loop through the detected poses to visualize.
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
# Draw the pose landmarks.
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
model_path = 'pose_landmarker.task' # 模型 需要自己下载
file_path = 'people.mp4' # 要检测的图像的路径
BaseOptions = mp.tasks.BaseOptions
PoseLandmarker = mp.tasks.vision.PoseLandmarker
PoseLandmarkerOptions = mp.tasks.vision.PoseLandmarkerOptions
VisionRunningMode = mp.tasks.vision.RunningMode
# Create a pose landmarker instance with the video mode:
options = PoseLandmarkerOptions(
base_options=BaseOptions(model_asset_path=model_path),
running_mode=VisionRunningMode.VIDEO)
with PoseLandmarker.create_from_options(options) as landmarker:
cap = cv2.VideoCapture(file_path)
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'v')
# 设置视频帧频
fps = cap.get(cv2.CAP_PROP_FPS)
# 设置视频大小
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# VideoWriter方法是cv2库提供的保存视频方法
# 按照设置的格式来out输出
out = cv2.VideoWriter('out.mp4', fourcc, fps, size)
count = 0
while True:
ret, frame = cap.read()
if ret:
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)
pose_landmarker_result = landmarker.detect_for_video(mp_image, count)
count += int(frame_count)
annotated_image = draw_landmarks_on_image(mp_image.numpy_view(), pose_landmarker_result)
cv2.imshow("new_image", annotated_image)
out.write(annotated_image)
if cv2.waitKey(1) == ord('q'):
break
else:
break
cap.release()
out.release()
cv2.destroyAllWindows()
BlazePose数据流姿态识别

- 异步获取姿态估计信息
import time
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import numpy as np
import mediapipe as mp
import cv2
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
def print_result(result, output_image: mp.Image, timestamp_ms: int):
print('pose landmarker_list: {}'.format(result))
live_stream = 0 # "http://192.168.43.88:81/stream"
model_path = 'pose_landmarker.task'
BaseOptions = mp.tasks.BaseOptions
PoseLandmarker = mp.tasks.vision.PoseLandmarker
PoseLandmarkerOptions = mp.tasks.vision.PoseLandmarkerOptions
PoseLandmarkerResult = mp.tasks.vision.PoseLandmarkerResult
VisionRunningMode = mp.tasks.vision.RunningMode
options = PoseLandmarkerOptions(
base_options=BaseOptions(model_asset_path=model_path),
running_mode=VisionRunningMode.LIVE_STREAM,
result_callback=print_result)
with PoseLandmarker.create_from_options(options) as landmarker:
cap = cv2.VideoCapture(live_stream)
count = 0
while True:
ret, frame = cap.read()
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)
landmarker.detect_async(mp_image, count) # 这里的count是 timestamp 单位毫秒
count += 30
if count > 10000:
break
time.sleep(0.1) # 运行太快了异步跟不上 所以采用暂停0.1s的方式
cap.release()
cv2.destroyAllWindows()
- 利用图像逐帧处理获取实时姿态识别
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import numpy as np
import mediapipe as mp
import cv2
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
def draw_landmarks_on_image(rgb_image, detection_result):
pose_landmarks_list = detection_result.pose_landmarks
annotated_image = np.copy(rgb_image)
print(rgb_image.shape)
# Loop through the detected poses to visualize.
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
# Draw the pose landmarks.
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
base_options = python.BaseOptions(model_asset_path='pose_landmarker.task')
live_stream = 0 # "http://192.168.43.88:81/stream"
BaseOptions = mp.tasks.BaseOptions
PoseLandmarker = vision.PoseLandmarker
PoseLandmarkerOptions = mp.tasks.vision.PoseLandmarkerOptions
PoseLandmarkerResult = mp.tasks.vision.PoseLandmarkerResult
VisionRunningMode = mp.tasks.vision.RunningMode
ccap = cv2.VideoCapture
options = vision.PoseLandmarkerOptions(
num_poses=1,
base_options=base_options,
output_segmentation_masks=False)
detector = vision.PoseLandmarker.create_from_options(options)
with PoseLandmarker.create_from_options(options) as landmarker:
cap = cv2.VideoCapture(live_stream)
while True:
ret, frame = cap.read()
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)
detection_result = detector.detect(mp_image)
annotated_image = draw_landmarks_on_image(mp_image.numpy_view(), detection_result)
cv2.imshow("new_image", annotated_image)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
结果展示
-
姿态估计点获取结果

-
姿态识别结果

- 外接摄像头识别结果
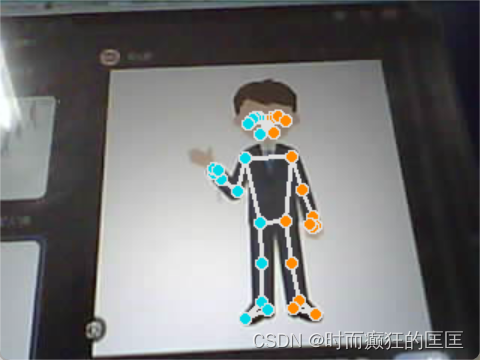
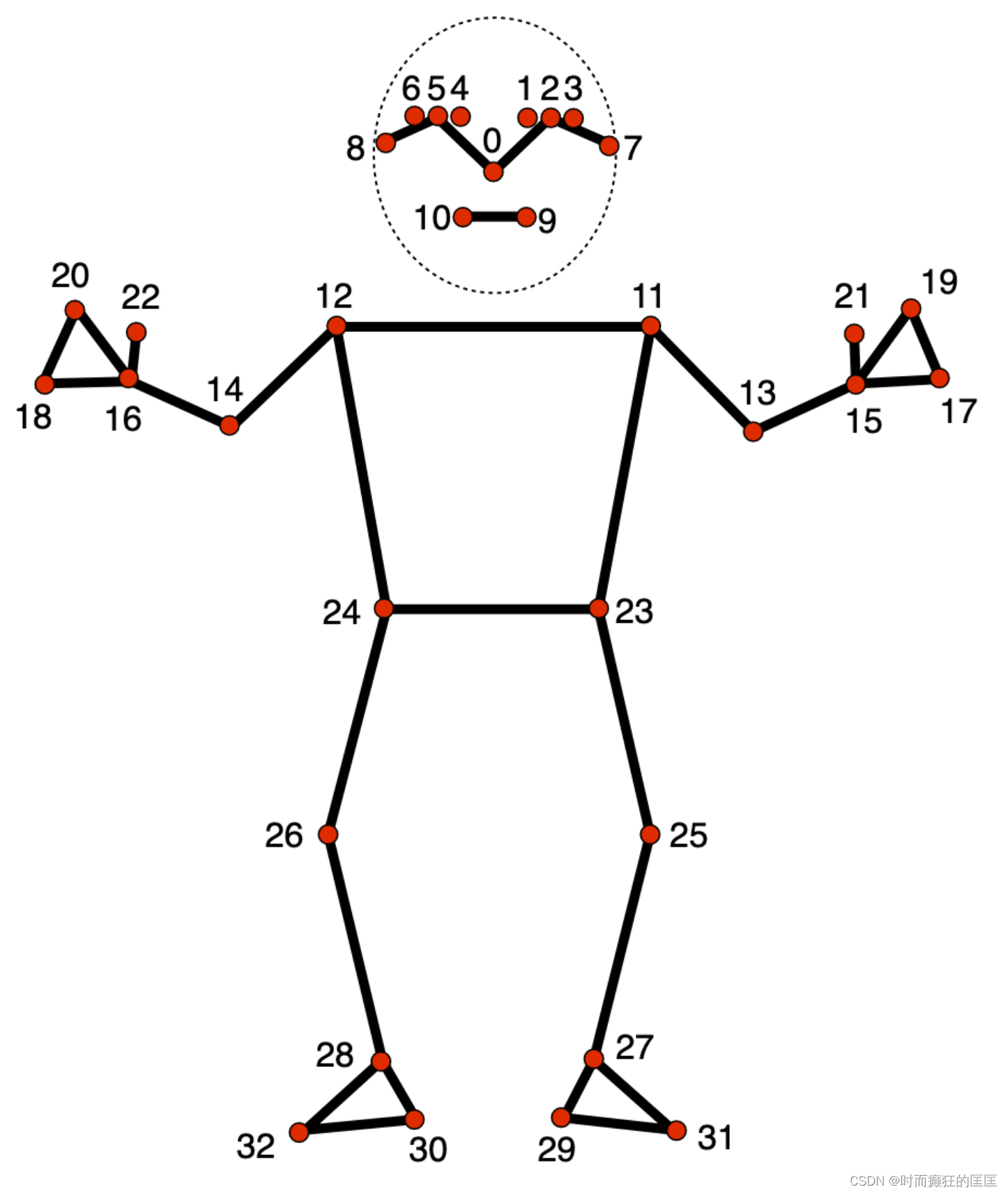
- 数据点说明


















 5165
5165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











