






导读
本文主要从三个方面来介绍下本人2021年的上半年的工作,优化跨境电商的搜索相关性中的一块工作:搜索query实体理解,因为只有做好query实体理解这第一步,才能继续做很多后面相关性的事情。比如词改写,替换,扩展等。
- 训练数据获取
- 模型架构设计和优化
- 线上工程化
- 迭代和优化
一. 训练数据获取
我们都知道要训练一个模型,是少不了训练数据的。目前还没有一个很标准的英文电商实体的数据集,所以这个数据集只能靠自己建立了。基于我们对自己业务的理解,并参考国内电商业界的定义,我们定义了总共15类实体,品类,修饰,人群,品类修饰词,品牌,型号,IP, 颜色,材质,年龄,尺寸规格,款式元素,风格,功能功效,场景。
品类:名词,在句子中代表某一种或者某一类商品
人群:代表某一类人群(man woman baby lady )
品牌:代表品牌
品类修饰词:该词本身表示某一品类,但是在句子中表示修饰作用,比如car perfume iphone case 里的car iphone
型号:比如 iPhone 12 Samsung note 9中的12 和note 9
IP:影视,动漫,娱乐,音乐等的组合 人名 角色等,如black pink
颜色:就是颜色
材质:服装类的布料材质,饰品的 金银等,家具的木材材质
年龄:年龄,把英文中表示整个年龄的字符都标出来比如 10 years old, age of 10, 1-10 years old 等
尺寸规格:服装 鞋子家具的物品大小
款式元素:表示物品的部分形状特征和组成元素,如 短袖 长袖
风格:表示物品整体的特征,性感 可爱 修身 大码等
功能功效:物品的某项功效,祛痘 美白 消毒 清洁,主要美妆类,家居类
场景:物品的使用场合和地方,如厨房 户外 室内 聚会
修饰:一般形容词,但是不包含以上类别形容词
有了实体定义之后,我们就应该想想从哪里获取标注数据。我们从日常用户搜索的query中随机抽取,当然要做一些筛选,比如去掉特别长尾的,像一个月就搜过一次的;去掉query特别长或者特别短的等。最终取了50000个待标注样本。有了标注数据,就要想如何省时省力完成数据的标注工作。最终我们采取内部提供工具,给外包标注的形式进行了整个数据的标注工作。
我们自己基于开源的标注工具doccano,搭建了一个内部的标注网站提供给外包公司,参考链接一站式文本标注工具doccano(你值得拥有) - 知乎。新的版本有更新,可以使用最新版本。我们建好标注工程,给到标注公司,规定大概某个时间点完成 。当然这里面还有校验工作,每天我们会安排公司内部业务同学对外包的新增标注进行抽检,如果准确率达不到标准,会要求他们重标或者重新培训。
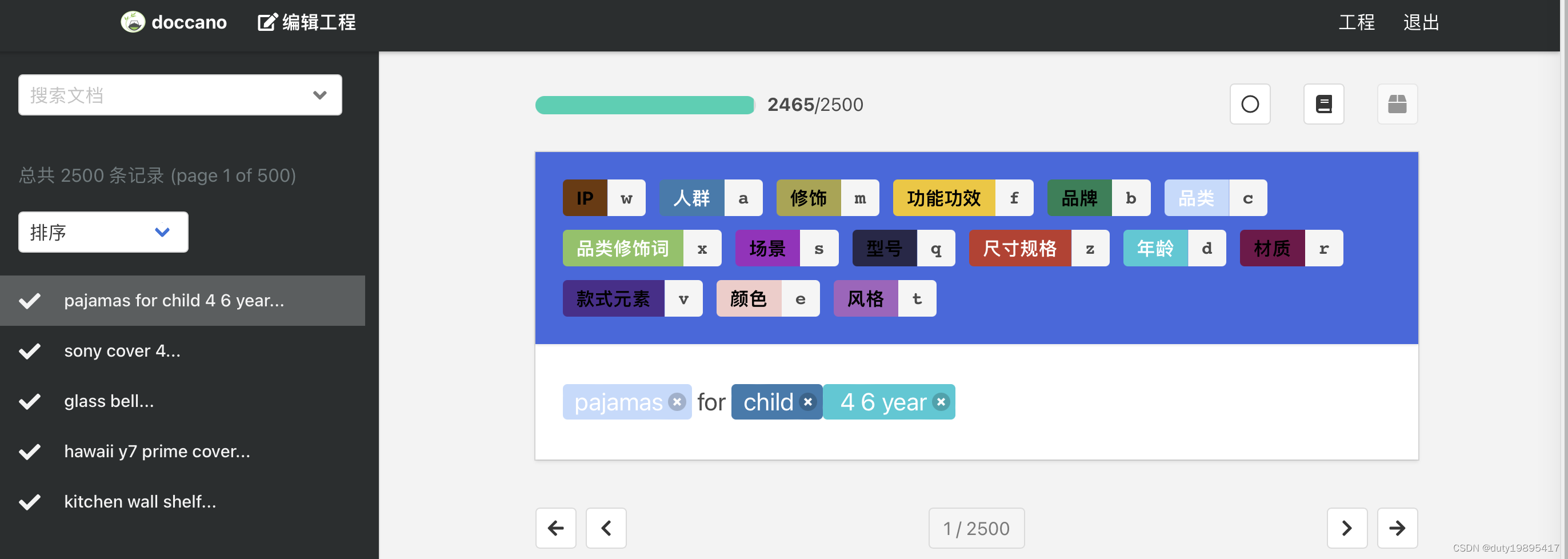
五万条数据经历了差不多一个月时间全部标注完成。最终标注好后转换完成的数据格式:jordan 11 shoe;B_type E_type S_category,当然可以根据模型输入需要更改。
模型架构设计和优化
基于bert的强大理解能力,第一想法就是直接用bert来做实体识别,当然也有试过其他的,最后确实bert效果最好。代码参考:GitHub - dutyhong/spanbert。但由于通用的预训练的bert模型是基于比较正规的英文文本进行训练的,而搜索query中其实是有很多缩写,不规范英文单词的。这个时候需要把这些词加入词汇表中进行微调训练。我们最后根据这些词的搜索频率进行了筛选加入千级别个数的词生成新的词汇表。
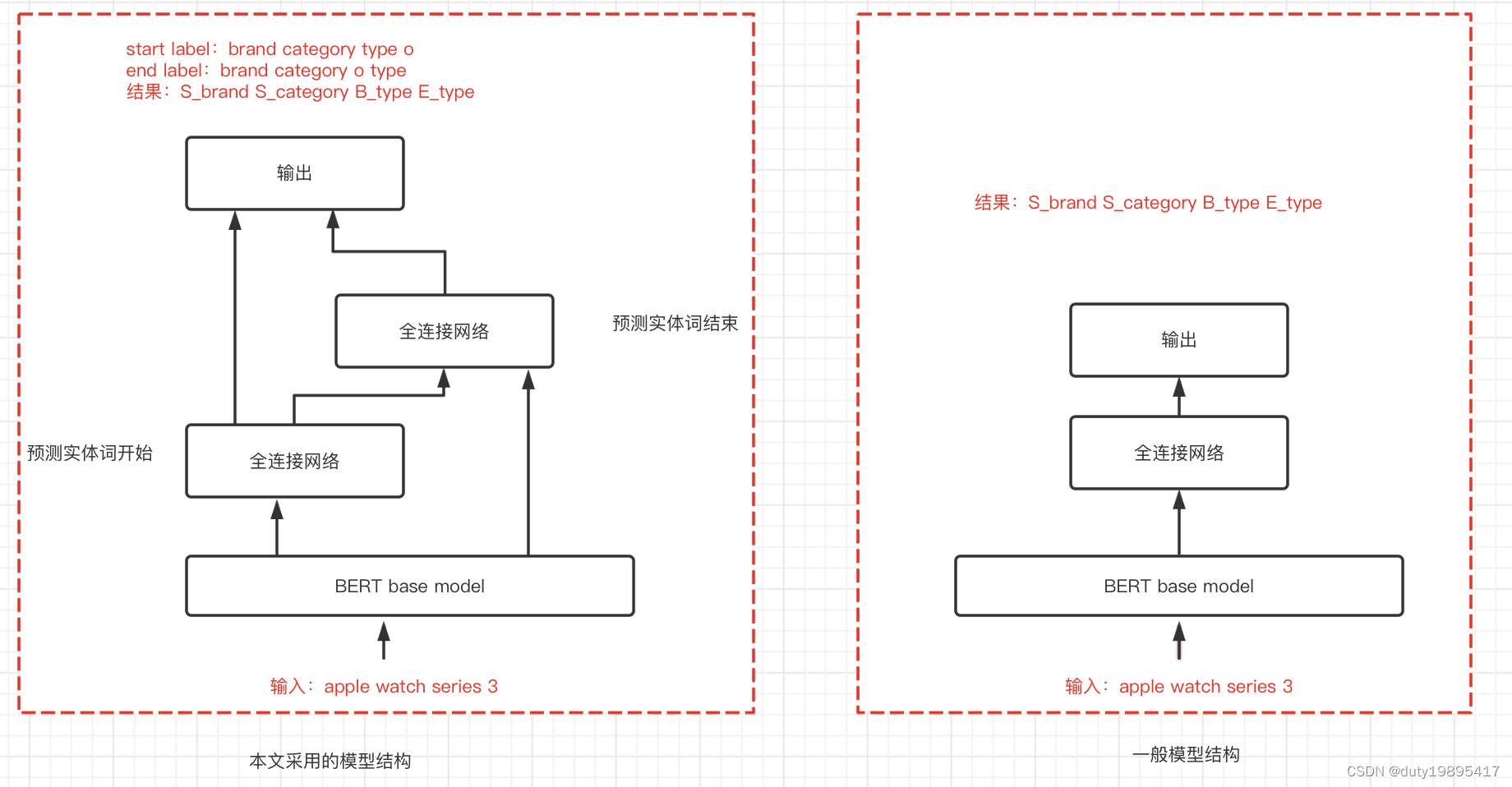
解释上图的左边模型结构,模型结构在一般模型结构的基础上进行了一点优化。我们先用一个全连接网络来预测每个标注样本的所有实体词的开始token,然后将这个全连接的输出logits进行softmax和bert的输出进行合并输入下一个全连接来预测实体的结尾。为什么要这么设计呢,可以理解为有了整个query的信息和每个实体词的开始token信息,这样来预测每个实体词的结尾更加准确。而且这样可以避免一般模型结构中预测每个token的实体信息要更好。比如当实体比较长的时候,如steam coffee machine,只需开始steam和结尾machine准确就可以了。
有人问为什么选择模型改成这样呢。因为效果好啊,这个模型结构不管是召回还是准确都比一般的模型结构结果好3-4个点。最终模型准确率能达到88+%,在模型识别的基础上在加上一些规则,最终准确率是91%+。规则还是个好东西啊。
线上工程化
模型训练完成,接下来想的就是如何满足线上要求的情况下上线使用。为了和线上系统兼容并不增加其他系统的情况,本文采用了java调用onnx模型的方式进行线上调用。离线测试每个query的耗时为30-50ms之间,线上可以接受。代码参考:GitHub - dutyhong/onnxpredict。注意调用的时候一些内存泄漏问题。
迭代和优化
每个模型都有后续的迭代和优化的过程,为了每次优化badcase更加方便快捷,基于streamlit做了个前端页面可以让每个人都能来优化模型。
1. 标注待优化的样本,通过标注完上传待优化样本
2. 将待优化的样本和旧的样本组合成新的样本重新训练模型
3. 训练完成评估测试集结果,是否有较大差异(为了保证优化后的模型与之前模型不能有较大差异)
4. 查看优化样本的结果,为了分析模型优化之后对于待优化的case是否都已优化完成
5. 确认优化完成,同步模型到线上


















 3299
3299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









