







 本文通过wordcount示例探讨Spark任务的提交与执行,重点讲解RDD的创建(如textFile、flatMap、map)及转换过程,特别是DAG的构建。在textFile步骤中,涉及HadoopRDD的创建和窄依赖;flatMap用于单词拆分;map操作保持数据结构;reduceByKey通过隐式转换和combineByKeyWithClassTag进行聚合,可能创建ShuffledRDD并形成ShuffleDependency。
本文通过wordcount示例探讨Spark任务的提交与执行,重点讲解RDD的创建(如textFile、flatMap、map)及转换过程,特别是DAG的构建。在textFile步骤中,涉及HadoopRDD的创建和窄依赖;flatMap用于单词拆分;map操作保持数据结构;reduceByKey通过隐式转换和combineByKeyWithClassTag进行聚合,可能创建ShuffledRDD并形成ShuffleDependency。
在这里通过使用wordcount例子来学习Spark是如何进行任务的提交与执行。本次先进行RDD的创建、转换以及DAG的构建进行学习。
整个wordcount的代码可以简单如下实现:
sc.textFile("/library/wordcount/input").flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).collect.foreach(println)程序的DAG图如下:
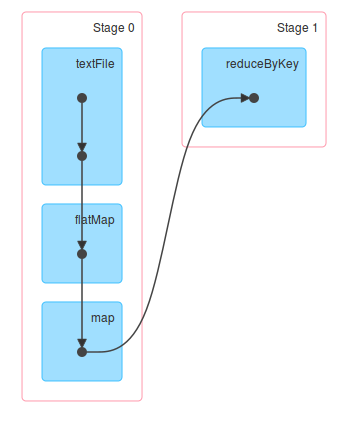
下面对每一步进行具体分析
1. textFile

SparkContext的testFile方法调用了hadoopFile方法用于创建HadoopRDD;其中hadoopFile方法包含三个步骤:
1. 将Hadoop的Configuration广播出去;
2. 设置文件输入路径;
3. 构建HadoopRDD实例对象;
对于构建的HadoopRDD实例对象调用map方法获得文件的内容,保存在MapPartitionsRDD类型的RDD中。在map方法中会调用clean方法,该方法实际调用ClosureCleaner的clean方法,这里是为了清除闭包中的不能被序列化的变量,防止RDD在网络传输过程中反序列化失败。
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString)
}
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobCo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7223
7223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









