







 本文介绍了k-d树,一种用于高维数据存取的数据结构,其在静态查询和插入方面表现高效。k-d树是一种特殊的二叉搜索树,每个节点代表多维空间中的一个点或区域。插入操作基于节点所在层数选择相应维度的key值进行划分。查找操作包括精确匹配、部分匹配、区域查询和最近点查找。尽管k-d树对删除操作支持不佳,但可以通过优化操作恢复平衡,保持查询效率。文章还探讨了k-d树的构建、查找和优化的复杂度。
本文介绍了k-d树,一种用于高维数据存取的数据结构,其在静态查询和插入方面表现高效。k-d树是一种特殊的二叉搜索树,每个节点代表多维空间中的一个点或区域。插入操作基于节点所在层数选择相应维度的key值进行划分。查找操作包括精确匹配、部分匹配、区域查询和最近点查找。尽管k-d树对删除操作支持不佳,但可以通过优化操作恢复平衡,保持查询效率。文章还探讨了k-d树的构建、查找和优化的复杂度。
作为存取高维数据的一种数据结构,k-d tree 在静态查询和插入方面的效率还是很高的。本文在这里对 k-d tree 的内容作一些介绍,可能也会结合自己使用 k-d tree 的一些体验作一些点评。其实,k-d tree 是早在1975年的时候由 Stanford 的 Bentley 提出来的。本文的内容也主要来自于他的两篇最原始的文章 [Ben75] 和 [FBF77] 。
k-d tree 概述 与 插入操作(Insertion)
首先,k-d tree 也是二叉搜索树的一种,与常见的平衡二叉搜索树(BST)不同的是,在 k-d tree 中,每个节点内存储的都是一条记录(record),或者说是多维空间中的一个点,用一个向量来表示。而且在 k-d tree中,这个点也代表了空间中的一个区域。每个节点都有两个子节点,而且两个子节点各自代表的区域是父节点的区域一个划分。
在一维的情形中,每条 record 都是由一个单独的 key 来表示的。因此,对于 k-d tree 中的每个节点,key 值小于或者等于当前节点的 key 值的点就属于左子树,比当前节点 key 值大的就属于右子树。因此,这里的 key 值就成为了一种鉴别器(discriminator)。而在 k 维的情况中,一条 record 是由 k 个 key 值来表示的,这里每一维的 key 值都可以作为 discriminator 来将一个点向某个节点的左右子树来分类。而在 k-d tree 中,discriminator 的选取是和该节点所在的层数有关的,即在根节点处,即第0层,按照第一维的 key 值来进行分类,第一维的 key 值小于等于根节点的第一维的 key 值的属于根节点的左子树,大于根节点的第一维的 key 值的属于根节点的右子树。然后在根节点的左右子节点的位置上,即第一层的位置上,根据第二维的 key 值来区分,以此类推。即第 k 层要比较的 key 值的维数为 D=L mod k+1 。其中L是当前节点所在的层数,其中根节点即为第0层。
按照 k-d tree 的规则依次插入(0,0), (-10, 10), (10, -10), (-40, -20), (-20, 11), (20, 0)这几个点,我们可以得到如下左图所示的 k-d tree,右图是这几个点在平面的示意图。其中蓝线表示该点处是以第一维的 key 值进行区分,红线表示该点处是以第二维的 key 值进行区分。
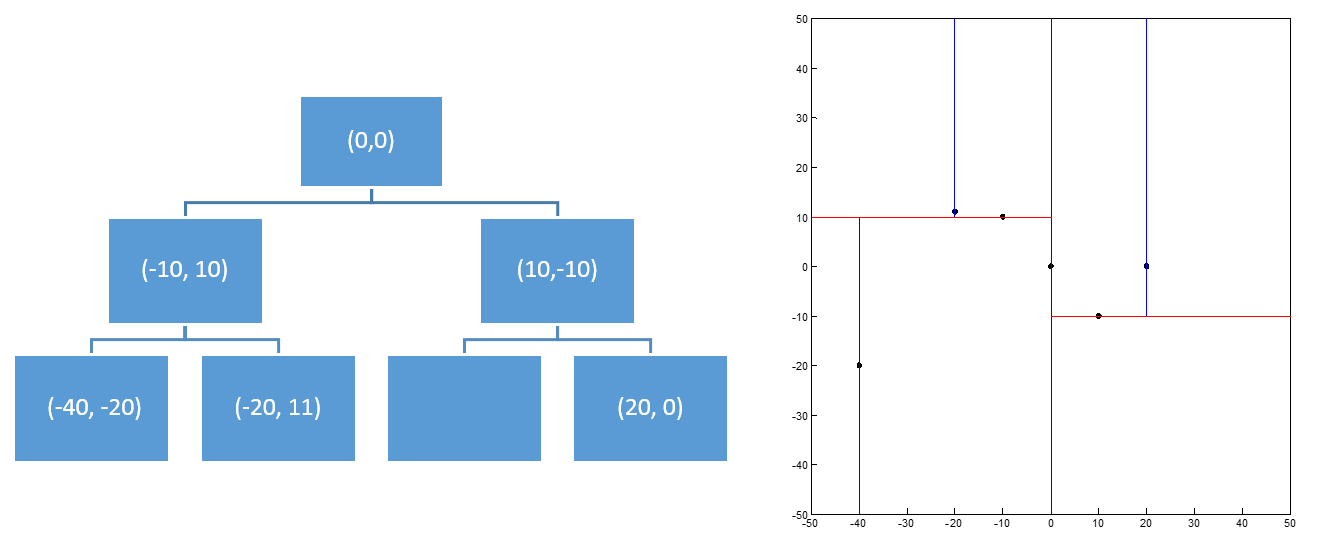
同时我们还可以看出,k-d tree 中每一个节点其实也代表了k维空间中的一个区域(region)。我们以上述几个二维空间中的点为例。根节点 (0,0) 代表的是全平面,即 (-50, -50, 50, 50) 这样一个区域,这里的区域我们用 (xmin,ymin,xmax,ymax) 来表示,因为根节点 (0,0) 是在第一维,即 x 轴出进行区分的,因此它的左子节点就代表了左半平面,右子节点就代表了右半平面。即点 (-10, 10) 代表的是 (-50, -50, 0, 50) 这样一个区域,点 (10, -10) 代表的是 (0, -50,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5965
5965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









