







alpaca-lora项目地址:https://github.com/tloen/alpaca-lora
微调
1、将项目下载到本地
git clone https://github.com/tloen/alpaca-lora.git
模型地址:
https://huggingface.co/decapoda-research/llama-7b-hf
2、配置环境
安装所需的包
pip install -r requirements.txt
预训练模型:decapoda-research/llama-7b-hf 会自动下载。共计33个405M的bin文件,大约占用约14G内存。

微调数据:https://huggingface.co/datasets/yahma/alpaca-cleaned
该数据基于斯坦福alpca数据进行了清洗。
由于微调时间较长,这里直接后台运行。
nohup python -u finetune.py \
--base_model '/data/sim_chatgpt/llama-7b-hf' \
--data_path '/data/datasets/alpaca-cleaned' \
--output_dir './lora-alpaca' \
>> log.out 2>&1 &
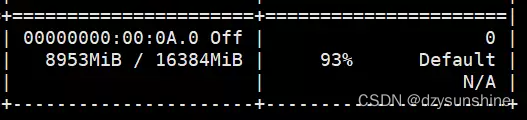
需要注意的是,运行代码后会报错:
解决方法:在finetune.py中增加一行代码:
with torch.autocast("cuda"):
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
微调过程预计需要60个小时,占用显存约9个G。

推理
设置generate.py文件,将share=True,便于公网访问。
python generate.py \
--load_8bit \
--base_model '/data/sim_chatgpt/llama-7b-hf' \
--lora_weights './lora-alpaca/checkpoint-1000'
如果报错,不能创建链接,降低下gradio版本即可,如:pip install gradio==3.13
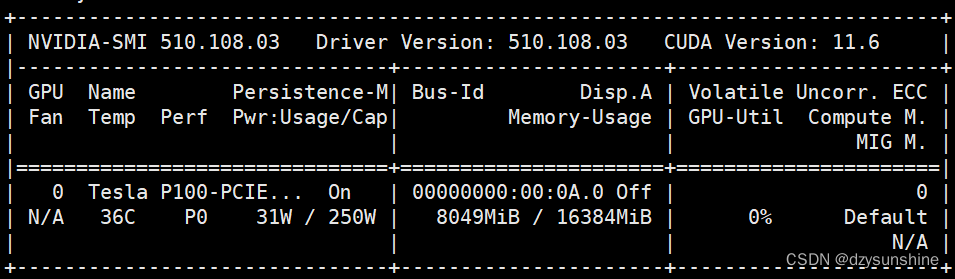
效果如下,显存占用约8个G(生成速度较慢,大概需要1分钟左右)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









