






AI大模型训练微调与数据集准备的系统性教程
模型训练微调与数据集准备的系统性教程
引言
本教程基于 Unsloth 框架、Google Colab 和 Hugging Face,利用 Google Colab 免费提供的 Tesla T4 GPU,指导您完成从数据收集、清洗、转换到模型微调和部署的全流程以及其他微调工具链推荐和规划系统性学习模型微调和数据集准备的教程学习路线(在文章底部)。我们将使用 Qwen2.5-7B 模型和 Alpaca 数据集,展示如何高效地进行模型训练和推理。本教程适合初学者和有经验的开发者,涵盖基础、中级和高级内容,帮助您掌握现代 AI 模型微调的完整技能。
章节 1:环境准备与安装
1.1 基础:环境配置与基本安装
目标
在 Google Colab 或本地环境中安装 Unsloth 和必要的依赖库。
内容
-
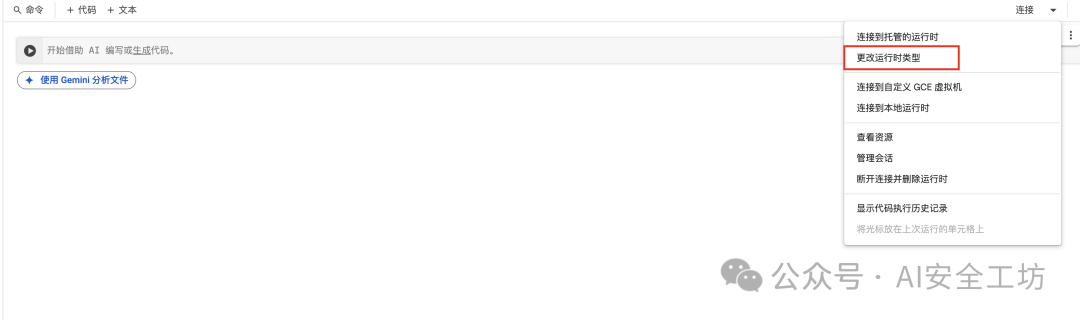
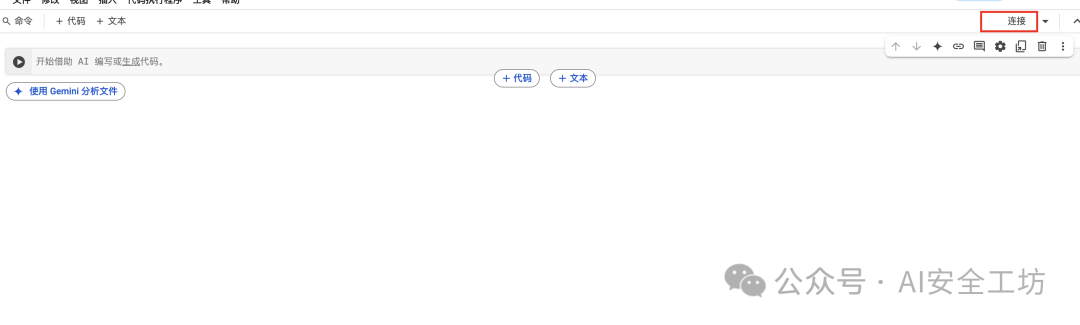
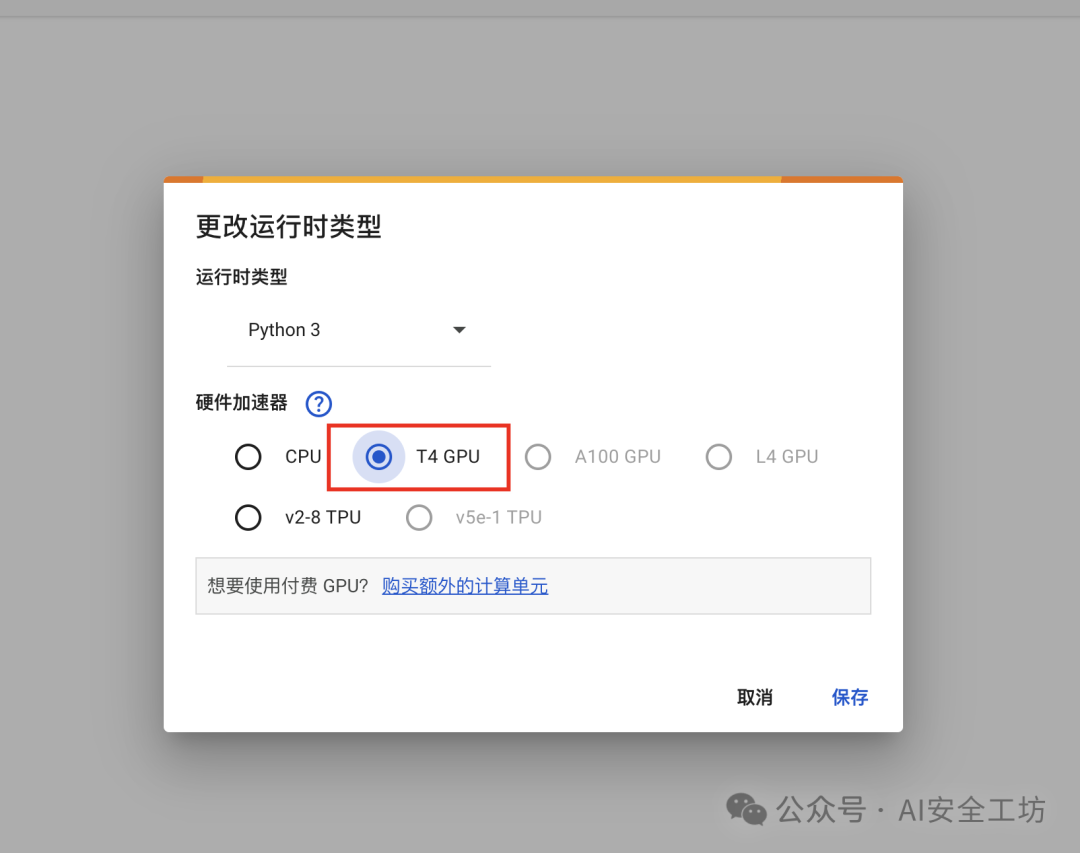
Google Colab 配置
:利用免费 Tesla T4 GPU,先更改运行时类型-选择T4GPU-保存,按 “连接” -> 执行。
-
-
-
-
本地安装
:参考 [Unsloth 安装指南]https://docs.unsloth.ai/get-started/installing-±updating。
-
代码示例:
%%capture import os if "COLAB_" not in "".join(os.environ.keys()): !pip install unsloth else: !pip install --no-deps bitsandbytes accelerate xformers==0.0.29 peft trl triton !pip install --no-deps cut_cross_entropy unsloth_zoo !pip install sentencepiece protobuf datasets huggingface_hub hf_transfer !pip install --no-deps unsloth -
解释
:根据运行环境(Colab 或本地),选择性安装依赖,确保兼容性。
-
定义:解决Colab兼容性问题,指定版本。
-
代码示例:
%%capture !pip install --no-deps "xformers==0.0.29" "trl==0.8.6" peft==0.11.1 accelerate==0.30.1 bitsandbytes==0.43.1 !pip install --no-deps unsloth import unsloth, xformers, trl print(f"Unsloth: {unsloth.__version__}, Xformers: {xformers.__version__}, TRL: {trl.__version__}")
实践
-
在 Colab 中运行上述代码,检查安装是否成功:
import unsloth print(unsloth.__version__) # 验证版本
1.2 中级:优化安装与资源管理
目标
优化依赖安装,减少内存占用,提升效率。
内容
-
依赖版本管理
:明确每个库的作用,例如 bitsandbytes 用于 4bit 量化,xformers 优化注意力机制。
-
增强代码:
!pip install --no-deps --upgrade bitsandbytes==0.43.0 accelerate==0.27.2 xformers==0.0.29 !pip install unsloth --no-cache-dir # 避免缓存占用空间 -
资源检查:在安装后查看 GPU 内存:
# 内存监控 import torch gpu_stats = torch.cuda.get_device_properties(0) print(f"GPU: {gpu_stats.name}, Total Memory: {gpu_stats.total_memory / 1024**3:.3f} GB") #第二种方法 !nvidia-smi import torch print(f"GPU可用:{torch.cuda.is_available()}, 名称:{torch.cuda.get_device_name(0)}") -
性能测试
-
定义:测试加载速度,验证优化效果。
-
代码示例:
import torch, time from unsloth import FastLanguageModel start = time.time() model, _ = FastLanguageModel.from_pretrained("unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit", load_in_4bit=True) # 自己用什么模型就替换什么模型 print(f"模型加载耗时:{time.time() - start:.2f}秒")
实践
- 运行优化后的安装脚本,记录安装时间和内存使用情况。
1.3 高级:自定义环境与多 GPU 支持
目标
为复杂任务配置多 GPU 环境并自定义依赖。
内容
-
多 GPU 配置:修改安装脚本支持多 GPU:
!pip install unsloth --extra-index-url https://download.pytorch.org/whl/cu121 --no-cache-dir os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" # 指定 GPU -
自定义编译:从源码安装 Unsloth 以支持特定硬件:
git clone https://github.com/unslothai/unsloth.git cd unsloth python setup.py install -
验证:检查多 GPU 可用性:
print(torch.cuda.device_count()) # 输出可用 GPU 数量
实践
- 在本地多 GPU 机器上运行上述代码,确保所有 GPU 被正确识别。
章节 2:数据集准备、清洗与转换
2.1 基础:数据加载与格式化
目标
加载 Alpaca 数据集并将其格式化为模型训练所需的结构。
内容
-
数据来源
:使用 [yahma/alpaca-cleaned]https://huggingface.co/datasets/yahma/alpaca-cleaned)数据集(52K 条)。
-
数据集如何收集:
-
- 使用huggingface上已有的数据集,使用DeepSeek生成清洗转换Python脚本,转换为自己需要多数据集格式。
- 通过爬虫爬需要的网站数据,清洗(可能存在违法行为,需谨慎)。
- 通过某些渠道购买专业团队做的内部未公开数据集(可能存在违法行为,需谨慎)。
- 其他方法还有很多…,但是请谨记遵守国家法律法规,合法合规合理获取数据集(别回头铁窗泪)。
-
数据集的格式区别
-
-
Alpaca格式:
-
- 结构:{“instruction”: “…”, “input”: “…”, “output”: “…”}
- 优点:适合指令任务。
-
ShareGPT格式:
-
- 结构:[{“role”: “user”, “content”: “…”}, {“role”: “assistant”, “content”: “…”}]
- 优点:适合对话。
-
深入了解看这个文章:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
-
-
格式化模板:
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: {} ### Input: {} ### Response: {}""" EOS_TOKEN = tokenizer.eos_token def formatting_prompts_func(examples): instructions = examples["instruction"] inputs = examples["input"] outputs = examples["output"] texts = [] for instruction, input, output in zip(instructions, inputs, outputs): text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN texts.append(text) return { "text" : texts, } from datasets import load_dataset dataset = load_dataset("yahma/alpaca-cleaned", split = "train") dataset = dataset.map(formatting_prompts_func, batched = True,) -
解释
:将指令、输入和输出格式化为统一文本,添加 EOS 标记防止无限生成。
实践
-
加载数据集并打印前 5 条格式化后的数据:
for i in range(5): print(dataset[i]["text"])
2.2 中级:数据清洗与增强
目标
清洗数据中的噪声并增强数据集多样性(善用Claude和DeepSeek辅助)。
内容
-
清洗规则:移除空值、重复项和无效字符:
def clean_dataset(examples): instructions = [i.strip() for i in examples["instruction"] if i] inputs = [i.strip() for i in examples["input"] if i] outputs = [o.strip() for o in examples["output"] if o] return {"instruction": instructions, "input": inputs, "output": outputs} dataset = dataset.map(clean_dataset, batched=True).filter(lambda x: len(x["instruction"]) > 0) -
数据增强:通过同义词替换增强数据:
from nltk.corpus import wordnet import random def augment_text(text): words = text.split() for i, word in enumerate(words): synonyms = [syn.lemmas()[0].name() for syn in wordnet.synsets(word)] if synonyms and random.random() > 0.7: words[i] = random.choice(synonyms) return " ".join(words) dataset = dataset.map(lambda x: {"instruction": augment_text(x["instruction"])}, batched=False)
实践
- 清洗并增强数据集,比较清洗前后数据量变化。
2.3 高级:自定义数据集与多模态支持
目标
从头构建自定义数据集并支持多模态数据。
内容
-
自定义数据集:从 CSV 文件加载数据:
import pandas as pd from datasets import Dataset df = pd.read_csv("custom_data.csv") # 假设包含 instruction, input, output 列 dataset = Dataset.from_pandas(df) dataset = dataset.map(formatting_prompts_func, batched=True) -
多模态支持:处理图像+文本数据:
from PIL import Image def process_multimodal(examples): texts = [] for instruction, image_path in zip(examples["instruction"], examples["image_path"]): img = Image.open(image_path).convert("RGB") text = f"{instruction} [Image: {image_path}]" + EOS_TOKEN texts.append(text) return {"text": texts} dataset = dataset.map(process_multimodal, batched=True)
实践
- 创建包含 100 条自定义数据的数据集,包含文本和图像路径,验证格式化结果。
章节 3:模型加载与微调
3.1 基础:加载预训练模型与 LoRA 配置
目标
加载 Qwen2.5-7B 模型并添加 LoRA 适配器。
内容
-
模型加载:
from unsloth import FastLanguageModel import torch max_seq_length = 2048 dtype = None load_in_4bit = True model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Qwen2.5-7B", max_seq_length = max_seq_length, dtype = dtype, load_in_4bit = load_in_4bit, ) -
LoRA 配置:
model = FastLanguageModel.get_peft_model( model, r = 16, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], lora_alpha = 16, lora_dropout = 0, bias = "none", use_gradient_checkpointing = "unsloth", random_state = 3407, use_rslora = False, loftq_config = None, ) -
解释
:使用 4bit 量化减少内存占用,LoRA 仅更新 1-10% 参数。
实践
-
加载模型并检查内存占用:
print(torch.cuda.memory_allocated() / 1024**3, "GB")
3.2 中级:超参数调优与训练优化
目标
调整 LoRA 参数和训练设置以提升性能。
内容
-
超参数调整:
model = FastLanguageModel.get_peft_model( model, r = 32, # 增加秩以提升表达能力 lora_alpha = 32, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"], use_rslora = True, # 启用秩稳定 LoRA ) -
训练设置:
from trl import SFTTrainer from transformers import TrainingArguments trainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = dataset, dataset_text_field = "text", max_seq_length = max_seq_length, args = TrainingArguments( per_device_train_batch_size = 4, # 增大 batch size gradient_accumulation_steps = 2, warmup_steps = 10, max_steps = 100, learning_rate = 1e-4, fp16 = True, logging_steps = 5, optim = "adamw_8bit", output_dir = "outputs", ), )
实践
- 运行 50 步训练,记录损失变化并调整 learning_rate。
3.3 高级:多模型融合与长序列支持
目标
融合多个预训练模型并支持超长序列。
内容
-
模型融合:
model2, _ = FastLanguageModel.from_pretrained("unsloth/Meta-Llama-3.1-8B-bnb-4bit") model.merge_and_unload() # 融合 LoRA 权重 model = FastLanguageModel.merge_models(model, model2) # 自定义融合函数需实现 -
长序列支持:
max_seq_length = 8192 # 增加到 8K model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Qwen2.5-7B", max_seq_length = max_seq_length, dtype = torch.bfloat16, )
实践
- 融合两个模型并测试长序列输入(例如 4000 token 的文本)。
章节 4:模型训练与评估
4.1 基础:简单训练与内存监控
目标
使用 SFTTrainer 进行基础训练并监控资源。
内容
-
训练代码:
trainer_stats = trainer.train() -
内存监控:
gpu_stats = torch.cuda.get_device_properties(0) start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3) max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3) print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.") print(f"{start_gpu_memory} GB of memory reserved.")
实践
- 运行 60 步训练,记录训练时间和内存峰值。
4.2 中级:损失分析与早停策略
目标
分析训练损失并实现早停。
内容
-
损失记录:
trainer = SFTTrainer(..., callbacks=[lambda trainer: print(trainer.state.log_history[-1])]) trainer.train() -
早停实现:
from transformers import EarlyStoppingCallback trainer = SFTTrainer( ..., callbacks=[EarlyStoppingCallback(early_stopping_patience=10)], )
实践
- 训练 200 步,绘制损失曲线并验证早停效果。
4.3 高级:分布式训练与评估指标
目标
实现分布式训练并添加评估指标。
内容
-
分布式训练:
trainer = SFTTrainer( ..., args = TrainingArguments(..., num_gpus=2, strategy="ddp"), ) -
评估指标:
from datasets import load_metric metric = load_metric("bleu") def compute_metrics(eval_pred): predictions, labels = eval_pred return metric.compute(predictions=predictions, references=labels) trainer = SFTTrainer(..., compute_metrics=compute_metrics)
实践
- 在多 GPU 上训练并计算 BLEU 分数。
章节 5:模型推理与部署
5.1 基础:简单推理
目标
使用训练后的模型进行推理。
内容
-
推理代码:
from datasets import load_metric metric = load_metric("bleu") def compute_metrics(eval_pred): predictions, labels = eval_pred return metric.compute(predictions=predictions, references=labels) trainer = SFTTrainer(..., compute_metrics=compute_metrics)
实践
- 输入不同序列,验证模型输出。
5.2 中级:流式推理与速度优化
目标
实现流式输出并提升推理速度。
内容
-
流式推理:
FastLanguageModel.for_inference(model) inputs = tokenizer( [alpaca_prompt.format("Continue the fibonnaci sequence.", "1, 1, 2, 3, 5, 8", "")], return_tensors = "pt").to("cuda") outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True) tokenizer.batch_decode(outputs) -
速度优化:
from transformers import TextStreamer text_streamer = TextStreamer(tokenizer) _ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
实践
- 比较流式与非流式推理的时间差异。
5.3 高级:模型保存与在线部署
目标
保存模型并部署到 Hugging Face Hub。
内容
-
保存模型:
model.save_pretrained("lora_model") tokenizer.save_pretrained("lora_model") -
在线部署:
model.push_to_hub("your_name/lora_model", token="your_hf_token") tokenizer.push_to_hub("your_name/lora_model", token="your_hf_token")
实践
- 将模型上传至 Hugging Face 并通过 API 调用测试。
章节 6:其他微调工具链介绍
除了 Unsloth,还有许多工具适用于大型语言模型的微调。以下是几个主流工具的介绍及其特点。
6.1 DeepSpeed
介绍与特点
DeepSpeed 是微软开发的深度学习优化库,支持大规模模型训练。主要特点:
- ZeRO优化:减少内存冗余。
- 管道并行:提高训练效率。
- 混合精度训练:降低资源需求。
安装方法
pip install deepspeed
使用示例
import deepspeed
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("gpt2")
ds_config = {"train_batch_size": 8, "fp16": {"enabled": True}}
model_engine, optimizer, _, _ = deepspeed.initialize(model=model, config=ds_config)
6.2 Megatron-LM
介绍与特点
Megatron-LM 是 NVIDIA 开发的框架,专注于超大规模 Transformer 模型训练。主要特点:
- 模型并行:分布参数到多个 GPU。
- 数据并行:并行处理数据。
安装方法
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
pip install -r requirements.txt
使用示例
python pretrain_gpt.py --num-layers 24 --hidden-size 1024 --micro-batch-size 4
6.3 FairScale
介绍与特点
FairScale 是 Facebook 开发的 PyTorch 扩展,支持模型并行和内存优化。主要特点:
- 模型并行:拆分模型到多个 GPU。
- ZeRO技术:优化内存使用。
安装方法
pip install fairscale
使用示例
from fairscale.nn import FullyShardedDataParallel as FSDP
model = FSDP(AutoModelForCausalLM.from_pretrained("gpt2"))
6.4 LLaMA-Factory
介绍与特点
LLaMA-Factory 是一个高效的微调框架,支持超过 100 种模型,通过 LoRA 和 QLoRA 实现快速微调。主要特点:
- 高效性:显著提升训练速度。
- 易用性:提供 WebUI 和 CLI。
- 灵活性:支持多模态任务。
安装方法
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
使用示例
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
与Unsloth对比
- Unsloth:适合单 GPU 快速微调,简单易用。
- LLaMA-Factory:支持多模态和复杂任务,提供更多配置选项。
6.5、总结与选择建议
- Unsloth:适合单 GPU 快速实验,易用性高,推荐初学者和资源有限时使用。
- DeepSpeed:适合多 GPU 大规模训练,适用于工业级任务。
- Megatron-LM:专注于超大规模模型,适合研究人员。
- FairScale:PyTorch 扩展,适合分布式训练场景。
- LLaMA-Factory:支持多模态任务,灵活高效,适合复杂需求。
根据您的资源和任务需求选择工具:
- 如果您在 Colab 上快速实验,Unsloth 是最佳选择。
- 如果有多个 GPU 和大规模数据,考虑 DeepSpeed 或 Megatron-LM。
- 如果需要多模态支持或更高灵活性,尝试 LLaMA-Factory。
系统学习模型训练微调课程:
就系统看下面这些就足够,不要再乱看其他的了
- Hugging Face 课程:https://huggingface.co/learn/nlp-course/zh-CN/chapter0/1?fw=pt
- 动手做大模型系列:https://github.com/echonoshy/cgft-llm/
- 用unsloth对模型进行微调Fine-tuning并本地应用:https://www.youtube.com/watch?v=uXTmBF4gZrk
- Llama3.1 8B 使用《史记》七十列传文本数据微调训练,实现现代文翻译至古文 :https://www.youtube.com/watch?v=Tq6qPw8EUVg
- 如何整理训练数据以及微调优化建议:https://www.youtube.com/watch?v=tOVG1YZ9bcI&t=13s[1]
- 【AI数据标注】企业标注流程及label studio打标工具介绍:https://www.youtube.com/watch?v=rTNrfq5Ay7o
- Unsloth官方文档:https://docs.unsloth.ai/
- Unsloth官方工具仓库:https://github.com/unslothai/unsloth
- LLaMA-Factory官方工具仓库(Web可视化微调训练):https://github.com/hiyouga/LLaMA-Factory
- LLaMA-Factory 数据集格式说明:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
- Colab官方地址:https://colab.research.google.com/
- huggingface官网:https://huggingface.co/
- 大模型基础:https://github.com/datawhalechina/so-large-lm
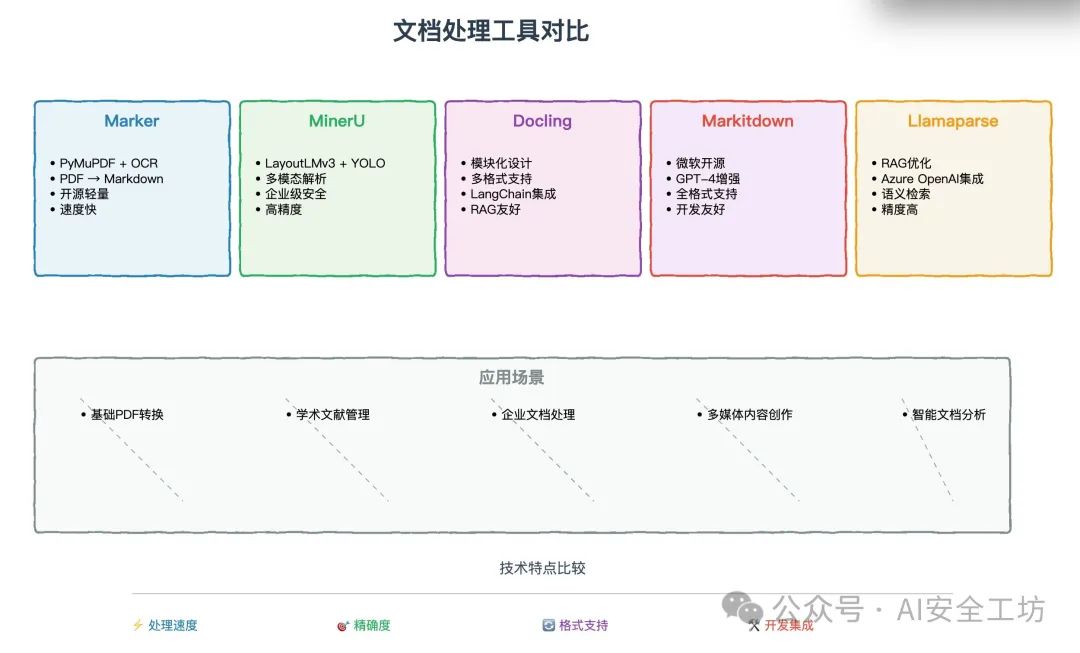
- 对于PDF文档做数据集推荐使用:https://olmocr.allenai.org/ 进行PDF识别转换其他格式进而清洗成数据集,其他工具链对比看下图
注意事项
- 环境:使用Colab免费T4 GPU,运行前确保GPU已启用。
- 替换变量:将YOUR_HF_TOKEN替换为实际值。
- 训练规模:当前设置为100步快速训练,可调整max_steps或改为num_train_epochs=1。
本教程通过详细步骤和完整代码展示了如何使用 Unsloth、Colab 和 Hugging Face 微调 Qwen2.5-7B 模型,同时补充了其他工具链的介绍。希望这篇文章能全面满足您的需求并为您的微调任务提供帮助!如果还有遗漏或需要补充的内容,请随时告知
结论
本教程从环境配置到模型部署,提供了从基础到高级的完整指南。通过实践,您可以掌握数据处理、模型微调和推理部署的核心技能。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


















 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









