







使用Pytorch实现手写数字识别
目标
- 知道如何使用Pytorch完成神经网络的构建
- 知道Pytorch中激活函数的使用方法
- 知道Pytorch中
torchvision.transforms中常见图形处理函数的使用- 知道如何训练模型和如何评估模型
1. 思路和流程分析
流程:
- 准备数据,这些需要准备DataLoader
- 构建模型,这里可以使用torch构造一个深层的神经网络
- 模型的训练
- 模型的保存,保存模型,后续持续使用
- 模型的评估,使用测试集,观察模型的好坏
2. 数据预处理及加载
准备数据集的方法前面已经讲过,但是通过前面的内容可知,调用MNIST返回的结果中图形数据是一个Image对象
(<PIL.Image.Image image mode=L size=28x28 at 0x1E5D17747C0>, 5),需要对其进行处理
为了进行数据的处理,接下来学习图形数据处理的api方法:torchvision.transfroms.xxx
2.1 图形数据加载预处理方法API之torchvision.transforms
2.1.1 torchvision.transforms.ToTensor
把一个取值范围是
[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W]
其中(H,W,C)意思为(高,宽,通道数),黑白图片的通道数只有1,其中每个像素点的取值为[0,255],彩色图片的通道数为(R,G,B),每个通道的每个像素点的取值为[0,255],三个通道的颜色相互叠加,形成了各种颜色
模拟生成图片处理示例如下:
import torch import torchvision import numpy as np np.random.seed(0) data = np.random.randint(0,256,size=12) # 模拟生成所有12个像素点 img = data.reshape(2,2,3) # 模拟高宽为2*2,通道数为3的彩色图片 print(img,'\n') img_transform1 = torchvision.transforms.ToTensor()(img) # ToTensor是一个对象实例化后传入参数,将img转化为tensor类型,再用transform转换 print(img_transform1,'\n') print(img_transform1.shape)输出如下:
[[[172 47 117] [192 67 251]] [[195 103 9] [211 21 242]]] tensor([[[172, 192], [195, 211]], [[ 47, 67], [103, 21]], [[117, 251], [ 9, 242]]], dtype=torch.int32) torch.Size([3, 2, 2])注意:
transforms.ToTensor对象中有__call__方法,所以可以对其示例能够传入数据获取结果# 模仿上面torchvision.transforms.ToTensor()(img)实际步骤 img_tensor = torch.tensor(img) print(img_tensor, '\n') img_transform2 = img_tensor.permute(2,0,1) print(img_transform2,'\n') print(img_transform2.shape)输出如下:
tensor([[[172, 47, 117], [192, 67, 251]], [[195, 103, 9], [211, 21, 242]]], dtype=torch.int32) tensor([[[172, 192], [195, 211]], [[ 47, 67], [103, 21]], [[117, 251], [ 9, 242]]], dtype=torch.int32) torch.Size([3, 2, 2])mnist数据集处理示例如下:
mnist_data = torchvision.datasets.MNIST(root='./data/',download=False,train=True,transform=None) print(mnist_data,'\n') print(mnist_data[0],'\n') mnist_transform = torchvision.transforms.ToTensor()(mnist_data[0][0]) print(mnist_transform.shape)输出如下:
Dataset MNIST Number of datapoints: 60000 Root location: ./data/ Split: Train (<PIL.Image.Image image mode=L size=28x28 at 0x1E5D06DE970>, 5) torch.Size([1, 28, 28])
2.1.2 torchvision.transforms.Normalize(mean, std)
给定均值:mean【shape和图片的通道数相同(指的是每个通道的均值)】,方差:std,【shape形状和图片的通道数相同(指的是每个通道的方差)】,将会把
Tensor规范化处理。
即:Normalized_image=(image-mean)/std。每个通道内:(通道内每张图片-通道内均值)/通道内方差
例如:
np.random.seed(0)
data = np.random.randint(0,256,size=12)
img = data.reshape(2,2,3).astype(np.float32)
img_tensor = torchvision.transforms.ToTensor()(img) # 转化为所需图形形状的tensor
img_norm = torchvision.transforms.Normalize((10,20,5),(1,2,1))(img_tensor) # 进行规范化处理,如第二个通道:(通道内每张图片-通道内均值20)/通道内方差2
print(img_tensor,'\n')
print(img_norm)
输出如下:
tensor([[[172., 192.],
[195., 211.]],
[[ 47., 67.],
[103., 21.]],
[[117., 251.],
[ 9., 242.]]])
tensor([[[162.0000, 182.0000],
[185.0000, 201.0000]],
[[ 13.5000, 23.5000],
[ 41.5000, 0.5000]],
[[112.0000, 246.0000],
[ 4.0000, 237.0000]]])
注意:在sklearn中,默认上式中的std和mean为数据每列的std和mean,sklearn会在标准化之前算出每一列的std和mean。
但是在api:Normalize中并没有帮我们计算,所以我们需要手动计算
- 当mean为全部数据的均值,std为全部数据的std的时候,才是进行了标准化。
- 如果mean(x)不是全部数据的mean的时候,std(y)也不是的时候,Normalize后的数据分布满足下面的关系
n e w _ m e a n = m e a n − x y , m e a n 为 原 数 据 的 均 值 , x 为 传 入 的 均 值 x n e w _ s t d = s t d y , y 为 传 入 的 标 准 差 y \begin{aligned} &new\_mean = \frac{mean-x}{y}&, mean为原数据的均值,x为传入的均值x \\ &new\_std = \frac{std}{y} &,y为传入的标准差y\\ \end{aligned} new_mean=ymean−xnew_std=ystd,mean为原数据的均值,x为传入的均值x,y为传入的标准差y
2.1.3 torchvision.transforms.Compose(transforms)
传入一个列表,将多个
transform组合起来使用,类似于管道pipline,组合多个预处理方法传给数据使用,例如mnist_data = torchvision.datasets.MNIST(transform=transform)中的transform = torchvision.transforms.Compose([xxx,xxx])参数赋值。
例如:
transform_fn = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), #先转化为Tensor
torchvision.transforms.Normalize(mean=0,std=1) #在进行正则化
])
mnist_data = torchvision.datasets.MNIST(root='./data/', download=False, train=True, transform=transform_fn)
2.2 准备MNIST数据集的Dataset和DataLoader
准备训练集
#准备数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
#因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
# 准备训练数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
# 因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
train_dataset = torchvision.datasets.MNIST(root='./data/', download=True, train=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 先转化为Tensor
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)) # 在进行正则化
]))
# 准备训练数据迭代器
train_dataloader = torch.utils.data.DataLoader(train_dataset,batch_size=128,shuffle=True)
for idx in enumerate(train_dataloader):
print(idx)
break
"""
(0, [tensor([[[[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
...,
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242]]],
...,
[[[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
...,
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242]]]]), tensor([1, 1, 4, 8, 8, 6, 2, 1, 0, 9, 0, 8, 1, 2, 1, 1, 8, 8, 4, 6, 0, 1, 4, 3,
2, 1, 1, 8, 4, 0, 3, 7, 6, 8, 7, 6, 7, 8, 7, 5, 9, 9, 0, 9, 0, 2, 1, 4,
2, 9, 1, 0, 7, 8, 9, 0, 0, 8, 0, 7, 7, 1, 2, 2, 7, 7, 1, 4, 6, 0, 1, 8,
9, 6, 4, 9, 6, 2, 5, 1, 6, 4, 4, 9, 5, 3, 1, 2, 4, 3, 2, 2, 3, 9, 7, 7,
7, 5, 6, 8, 7, 2, 6, 3, 5, 6, 9, 5, 8, 2, 1, 5, 6, 8, 8, 7, 9, 9, 4, 0,
1, 9, 4, 4, 7, 1, 8, 5])])
"""
准备测试集
# 准备测试数据集
test_dataset = torchvision.datasets.MNIST(root='./data/', download=True, train=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 先转化为Tensor
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)) # 在进行正则化
]))
# 准备测试数据迭代器
test_dataloader = torch.utils.data.DataLoader(test_dataset,batch_size=2,shuffle=True)
for idx in enumerate(test_dataloader):
print(idx)
break
"""
(0, [tensor([[[[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
...,
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242]]],
...,
[[[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
...,
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242],
[-0.4242, -0.4242, -0.4242, ..., -0.4242, -0.4242, -0.4242]]]]), tensor([8, 8, 5, 1, 3, 6, 4, 1, 1, 0, 6, 4, 6, 5, 0, 1, 7, 3, 0, 5, 9, 6, 7, 9,
9, 6, 1, 8, 1, 5, 5, 4, 2, 1, 4, 9, 9, 1, 6, 5, 1, 0, 6, 4, 9, 0, 6, 3,
9, 8, 1, 9, 6, 4, 6, 4, 1, 7, 2, 4, 7, 1, 5, 1, 2, 4, 1, 8, 0, 8, 4, 1,
6, 3, 2, 6, 6, 5, 1, 0, 1, 4, 5, 6, 3, 9, 9, 6, 3, 2, 6, 7, 8, 0, 1, 9,
6, 5, 8, 1, 3, 9, 2, 0, 6, 8, 7, 7, 8, 4, 7, 0, 2, 5, 3, 9, 8, 2, 8, 2,
9, 6, 6, 7, 0, 0, 2, 2, 7, 5, 4, 2, 6, 4, 1, 3, 3, 7, 8, 4, 6, 8, 3, 8,
1, 2, 7, 2, 2, 1, 3, 9, 0, 0, 5, 5, 5, 2, 0, 6, 7, 6, 4, 1, 3, 8, 1, 7,
3, 6, 4, 4, 3, 6, 8, 3, 7, 2, 2, 6, 7, 0, 8, 5, 2, 8, 4, 6, 8, 9, 7, 3,
2, 1, 8, 5, 6, 8, 7, 9])])
"""
将加载的dataset和处理的dataloader写成一个获取数据加载类函数get_dataloader:
TRAIN_BATCH_SIZE = 128
TEST_BATCH_SIZE=1000
def get_dataloader(train=True):
transform_fn = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 先转化为Tensor
torchvision.transforms.Normalize(
mean=(0.1307,), std=(0.3081,)) # 在进行正则化
])
batch_size = TRAIN_BATCH_SIZE if train else TEST_BATCH_SIZE
mnist_data = torchvision.datasets.MNIST(
root='./data/', train=train, transform=transform_fn)
data_loader = torch.utils.data.DataLoader(mnist_data,batch_size=batch_size,shuffle=True)
return data_loader
3. 构建模型
补充:全连接层:当前一层的神经元和前一层的神经元相互链接,其核心操作就是 y = w x y = wx y=wx,即矩阵的乘法,实现对前一层的数据的变换
模型的构建使用了一个三层的神经网络,其中包括两个全连接层和一个输出层,第一个全连接层会经过激活函数的处理,将处理后的结果交给下一个全连接层,进行变换后输出结果
那么在这个模型中有两个地方需要注意:
- 激活函数如何使用
- 每一层数据的形状
- 模型的损失函数
3.1 激活函数api使用之torch.nn.functional
前面介绍了激活函数的作用,常用的激活函数为Relu激活函数,它的使用非常简单:
Relu激活函数由import torch.nn.functional as F提供,F.relu(x)即可对x进行处理
例如:
import torch.nn.functional as F
a = torch.tensor([-2,-1,0,1,2],dtype=torch.float32)
print(a)
print(F.relu(a))
print(F.softmax(a,dim=-1))
"""
tensor([-2., -1., 0., 1., 2.])
tensor([0., 0., 0., 1., 2.])
tensor([0.0117, 0.0317, 0.0861, 0.2341, 0.6364])
"""
3.2 模型的构建及数据形状设置
- 原始输入数据为的形状:
[batch_size,1,28,28]- 进行形状的修改:
[batch_size,28*28],(全连接层是在进行矩阵的乘法操作)- 第一个全连接层的输出形状:
[batch_size,28],这里的28是个人设定的,你也可以设置为别的,即第一个隐藏层输出神经元为28个- 激活函数不会修改数据的形状
- 第二个全连接层的输出形状:
[batch_size,10],因为手写数字有10个类别,即第一个隐藏层输出神经元为10个
构建模型的代码如下:
import torch
import torch.nn.functional as F
import torch.nn as nn
class MnistModule(nn.Module):
def __init__(self):
super(MnistModule,self).__init__() # 继承父类的方法
self.fc1 = nn.Linear(28*28*1,28) # 第一个全连接层
self.fc2 = nn.Linear(28,10) # 第二个全连接层
def forward(self,input):
"""
param: input [batch_size,1,28,28]
return: out [10,1]
"""
# 1、修改形状(-1表示该位置根据后面的形状自动调整)
x = input.view([-1,28*28*1]) # 或x = input.view(input.size[0],28*28*1)
# 2、进行全连接操作(送入第一个全连接层的输入,得到第一个全连接层的中间输出)
x = self.fc1(x)
# 3、进行激活函数的处理(得到第一个全连接层的输出)
x = F.relu(x)
# 4、再进行一个全连接层的操作(输出层)
out = self.fc2(x)
return out
可以发现:pytorch在构建模型的时候
形状上并不会考虑batch_size
3.3 模型损失函数softmax的使用
首先,我们需要明确,当前我们手写字体识别的问题是一个多分类的问题,所谓多分类对比的是之前学习的二分类
回顾之前的课程,我们在逻辑回归中,我们使用sigmoid进行计算对数似然损失,来定义我们的二分类的损失。
- 在2分类中我们有正类和负类,正类的概率为 P ( x ) = 1 1 + e − x = e x 1 + e x P(x) = \frac{1}{1+e^{-x}} = \frac{e^x}{1+e^x} P(x)=1+e−x1=1+exex,那么负类的概率为 1 − P ( x ) 1-P(x) 1−P(x)
- 将这个结果进行计算对数似然损失 − ∑ y l o g ( P ( x ) ) -\sum y log(P(x)) −∑ylog(P(x))就可以得到最终的损失
那么在多分类的过程中我们应该怎么做呢?
- 多分类和二分类中唯一的区别是我们不能够再使用sigmoid函数来计算当前样本属于某个类别的概率,而应该使用softmax函数。
- softmax和sigmoid的区别在而分类中,在于softmax我们需要去计算样本属于每个类别的概率,需要计算多次,而sigmoid只需要计算一次
softmax的公式如下:
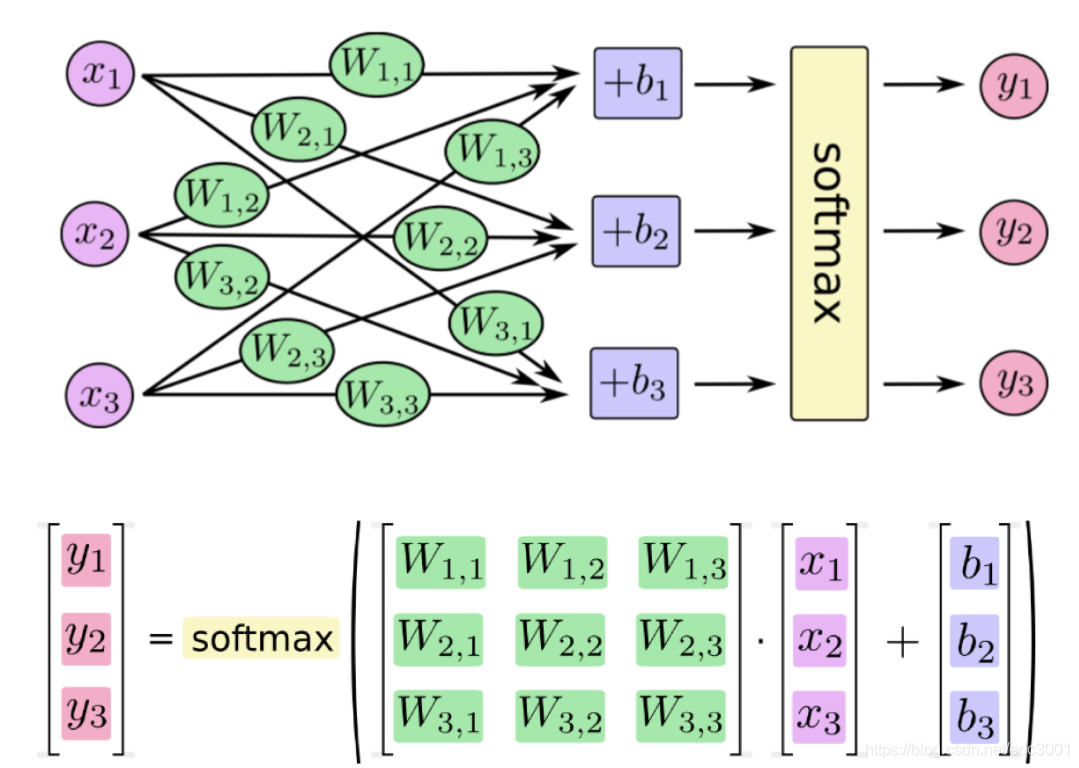
σ ( z ) j = e z j ∑ k = 1 K e z K , j = 1 ⋯ k \sigma(z)_j = \frac{e^{z_j}}{\sum^K_{k=1}e^{z_K}} ,j=1 \cdots k σ(z)j=∑k=1KezKezj,j=1⋯k例如下图:
假如softmax之前的输出结果是
2.3, 4.1, 5.6,那么经过softmax之后的结果是多少呢?Y 1 = e 2.3 e 2.3 + e 4.1 + e 5.6 Y 2 = e 4.1 e 2.3 + e 4.1 + e 5.6 Y 3 = e 5.6 e 2.3 + e 4.1 + e 5.6 Y1 = \frac{e^{2.3}}{e^{2.3}+e^{4.1}+e^{5.6}} \\ Y2 = \frac{e^{4.1}}{e^{2.3}+e^{4.1}+e^{5.6}} \\ Y3 = \frac{e^{5.6}}{e^{2.3}+e^{4.1}+e^{5.6}} \\ Y1=e2.3+e4.1+e5.6e2.3Y2=e2.3+e4.1+e5.6e4.1Y3=e2.3+e4.1+e5.6e5.6
对于这个softmax输出的结果,是在[0,1]区间,我们可以把它当做概率和前面二分类的损失一样,多分类的损失只需要再把这个结果进行对数似然损失的计算即可,即:
J = − ∑ Y l o g ( P ) , 其 中 P = e z j ∑ k = 1 K e z K , Y 表 示 真 实 值 \begin{aligned} & J = -\sum Y log(P) &, 其中 P = \frac{e^{z_j}}{\sum^K_{k=1}e^{z_K}} ,Y表示真实值 \end{aligned} J=−∑Ylog(P),其中P=∑k=1KezKezj,Y表示真实值
最后,会计算每个样本的损失,即上式的平均值我们把softmax概率传入对数似然损失得到的损失函数称为交叉熵损失
在pytorch中有两种方法实现交叉熵损失
criterion = nn.CrossEntropyLoss() loss = criterion(input,target)#1. 对输出值计算softmax和取对数 output = F.log_softmax(x,dim=-1) #2. 使用torch中带权损失 loss = F.nll_loss(output,target)带权损失定义为: l n = − ∑ w i x i l_n = -\sum w_{i} x_{i} ln=−∑wixi,其实就是把 l o g ( P ) log(P) log(P)作为 x i x_i xi,把真实值Y作为权重(交叉熵损失就是一个特殊的带权损失)
示例代码:
import torch.nn as nn
import torch.nn.functional as F
y_predict = torch.tensor([[0.1,0.05,0.6,0.0,0.05,0.1,0.0,0.1,0.0,0.0],
[0.9,0.05,0.05,0.0,0.0,0.0,0.0,0.0,0.0,0.0],
[0.0,0.05,0.2,0.0,0.05,0.0,0.0,0.0,0.0,0.7]])
y_true = torch.tensor([2,0,9])
# 交叉熵损失实现方法一:(内置交叉熵函数实现)
criterion = nn.CrossEntropyLoss()
loss = criterion(y_predict,y_true)
print(loss)
# 交叉熵损失实现方法二:(带权损失即交叉熵损失分步实现)
output = F.log_softmax(y_predict,dim=-1) # 1.对预测值计算softmax和取对数
loss = F.nll_loss(output,y_true) # 2. 使用torch中带权损失计算交叉熵
print(loss)
"""
tensor(1.6985)
tensor(1.6985)
"""
4. 模型的训练
训练的流程:
- 实例化模型,设置模型为训练模式,(实例化损失函数)
- 实例化优化器类
- 循环训练多轮
- 获取dataloader
- 遍历dataloader
- 调用模型进行向前计算,得到预测值
- 利用损失函数计算损失
- 梯度置为0
- 反向传播
- 更新梯度参数
mnist_model = MnistModule() # 实例化模型
optimizer = torch.optim.Adam(mnist_model.parameters(),lr=1e-3) # 实例化优化器类
def train(epoch): # 定义模型训练函数
data_loader = get_dataloader() # 获取dataloader
for idx,(input,y_true) in enumerate(data_loader): # 遍历dataloader
output = mnist_model(input) # 调用模型进行向前计算,得到预测值
loss = F.nll_loss(output,y_true) # 利用损失函数计算交叉熵损失
optimizer.zero_grad() # 梯度置为0
loss.backward() # 反向传播
optimizer.step() # 更新梯度参数
if not(idx%100): # 打印当前轮数及损失
print('Train epoch:{} \t idx:{:>3} \t loss:{}'.format(epoch,idx,loss.item()))
if __name__ == '__main__': # 文件作为脚本直接执行,若import到其他脚本中是不会被执行的
for i in range(3): # 循环训练多轮
train(i)
"""
Train epoch:0 idx: 0 loss:2.3230159282684326
Train epoch:0 idx:100 loss:0.5013977885246277
Train epoch:0 idx:200 loss:0.2599087357521057
Train epoch:0 idx:300 loss:0.19933709502220154
Train epoch:0 idx:400 loss:0.32249605655670166
Train epoch:1 idx: 0 loss:0.15655970573425293
Train epoch:1 idx:100 loss:0.20336264371871948
Train epoch:1 idx:200 loss:0.22325065732002258
Train epoch:1 idx:300 loss:0.2693881690502167
Train epoch:1 idx:400 loss:0.16877175867557526
Train epoch:2 idx: 0 loss:0.15177054703235626
Train epoch:2 idx:100 loss:0.21718598902225494
Train epoch:2 idx:200 loss:0.25959932804107666
Train epoch:2 idx:300 loss:0.12851223349571228
Train epoch:2 idx:400 loss:0.17836645245552063
"""
5. 模型的保存和加载
5.1 模型的保存
torch.save(mnist_model.state_dict(),'./model/mnist_model.pkl')
torch.save(optimizer.state_dict(),'./model/mnist_optimizer.pkl')
5.2 模型的加载
if os.path.exists('./model/mnist_model.pkl'): # 判断当前路径模型是否存在,不是的话则加载模型和优化器
mnist_model.load_state_dict(torch.load('./model/mnist_model.pkl'))
optimizer.load_state_dict(torch.load('./model/mnist_optimizer.pkl'))
5.3 应用模型的加载和保存
import os
mnist_model = MnistModule() # 实例化模型
optimizer = torch.optim.Adam(mnist_model.parameters(),lr=1e-3) # 实例化优化器类
if os.path.exists('./model/mnist_model.pkl'): # 判断当前路径模型是否存在,不是的话则加载模型和优化器
mnist_model.load_state_dict(torch.load('./model/mnist_model.pkl'))
optimizer.load_state_dict(torch.load('./model/mnist_optimizer.pkl'))
def train(epoch): # 定义模型训练函数
data_loader = get_dataloader() # 获取dataloader
for idx,(input,y_true) in enumerate(data_loader): # 遍历dataloader
output = mnist_model(input) # 调用模型进行向前计算,得到预测值
loss = F.nll_loss(output,y_true) # 利用损失函数计算交叉熵损失
optimizer.zero_grad() # 梯度置为0
loss.backward() # 反向传播
optimizer.step() # 更新梯度参数
if not(idx%100): # 打印当前轮数及损失
print('Train epoch:{} \t idx:{:>3} \t loss:{}'.format(epoch,idx,loss.item()))
if not(idx%100): # 每隔100个batch保存一下模型和优化器
torch.save(mnist_model.state_dict(),'./model/mnist_model.pkl')
torch.save(optimizer.state_dict(),'./model/mnist_optimizer.pkl')
if __name__ == '__main__': # 文件作为脚本直接执行,若import到其他脚本中是不会被执行的
for i in range(3): # 循环训练多轮
train(i)
模型训练过一次后,再次运行结果如下:(用加载的模型再训练,可以发现在上次训练的模型下继续训练损失降得更低)
Train epoch:0 idx: 0 loss:0.1853410005569458
Train epoch:0 idx:100 loss:0.16155260801315308
Train epoch:0 idx:200 loss:0.09997643530368805
Train epoch:0 idx:300 loss:0.05048561841249466
Train epoch:0 idx:400 loss:0.08020254224538803
Train epoch:1 idx: 0 loss:0.07419444620609283
Train epoch:1 idx:100 loss:0.06372445076704025
Train epoch:1 idx:200 loss:0.05437915399670601
Train epoch:1 idx:300 loss:0.07008694857358932
Train epoch:1 idx:400 loss:0.08965955674648285
Train epoch:2 idx: 0 loss:0.045663390308618546
Train epoch:2 idx:100 loss:0.045866288244724274
Train epoch:2 idx:200 loss:0.06470013409852982
Train epoch:2 idx:300 loss:0.1140526533126831
Train epoch:2 idx:400 loss:0.1919308304786682
6. 模型的评估
评估的过程和训练的过程相似,但是:
- 1、不需要计算梯度
- 2、需要收集损失和准确率,用来计算平均损失和平均准确率
- 3、损失的计算和训练时候损失的计算方法相同
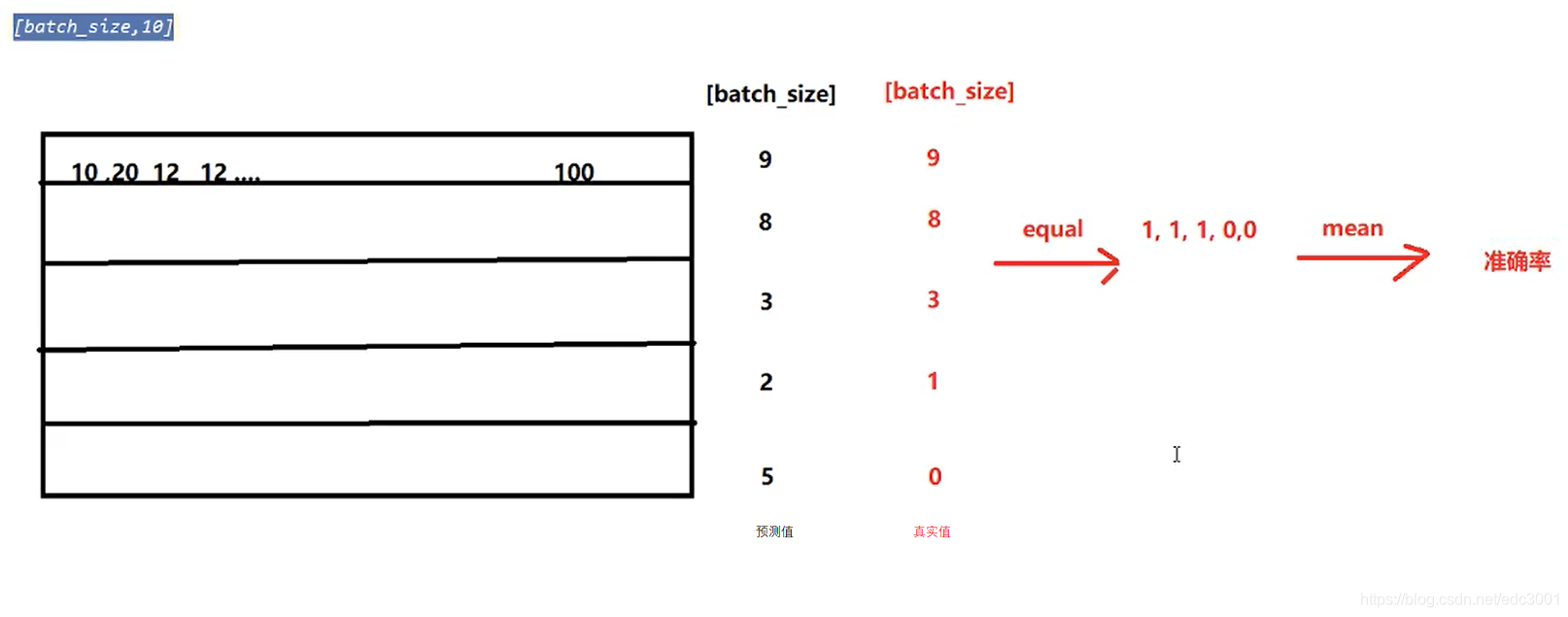
- 4、准确率的计算:
- 模型的输出为[batch_size,10]的形状
- 其中最大值的位置就是其预测的目标值(预测值进行过sotfmax后为概率,sotfmax中分母都是相同的,分子越大,概率越大)
- 最大值的位置获取的方法可以使用
torch.max,返回最大值和最大值的位置- 返回最大值的位置后,和真实值(
[batch_size])进行对比,相同表示预测成功计算方式(准确率为例)如下:
def test():
loss_list = []
acc_list = []
mnist_model.eval() # 设置模型为评估模式
test_data_loader = get_dataloader(train=False) # 获取测试数据集
for idx,(input,y_true) in enumerate(test_data_loader):
with torch.no_grad(): # 不计算其梯度
output = mnist_model(input)
cur_loss = F.nll_loss(output,y_true)
pred = output.max(dim=-1)[-1]
cur_acc = pred.eq(y_true).float().mean()
loss_list.append(cur_loss)
acc_list.append(cur_acc)
print(np.mean(acc_list),np.mean(loss_list))
test()
"""
0.9627 0.12913477
"""
7. 完整的代码
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
TRAIN_BATCH_SIZE = 128
TEST_BATCH_SIZE = 1000
# 1、数据预处理及加载
def get_dataloader(train=True):
transform_fn = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 先转化为Tensor
torchvision.transforms.Normalize(
mean=(0.1307), std=(0.3081)) # 再进行正则化
])
batch_size = TRAIN_BATCH_SIZE if train else TEST_BATCH_SIZE
mnist_data = torchvision.datasets.MNIST(
root='./data', train=train, transform=transform_fn)
data_loader = torch.utils.data.DataLoader(
mnist_data, batch_size=batch_size, shuffle=True)
return data_loader
# 2、构建模型
class MnistModule(nn.Module):
def __init__(self):
super(MnistModule, self).__init__()
self.fc1 = nn.Linear(28*28*1, 28)
self.fc2 = nn.Linear(28, 10)
def forward(self, input):
x = input.view([-1, 28*28*1])
x = self.fc1(x)
x = F.relu(x)
output = self.fc2(x)
# return F.log_softmax(output, dim=-1)
return output
# 3、模型的训练
mnist_model = MnistModule()
optimizer = optim.Adam(mnist_model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
if os.path.exists('./model/mnist_model.pkl'):
mnist_model.load_state_dict(torch.load('./model/mnist_model.pkl'))
optimizer.load_state_dict(torch.load('./model/mnist_optimizer.pkl'))
def train(epoch):
train_data_loader = get_dataloader()
for idx, (input, y_true) in enumerate(train_data_loader):
y_predict = mnist_model(input)
# loss = F.nll_loss(y_predict, y_true)
loss = criterion(y_predict,y_true)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if not(idx % 100):
print('Train epoch:{} \t idx:{:>3} \t loss:{}'.format(
epoch, idx, loss.item()))
# 4、模型的保存
if not(idx % 100):
torch.save(mnist_model.state_dict(), './model/mnist_model.pkl')
torch.save(optimizer.state_dict(), './model/mnist_optimizer.pkl')
# 5、模型的评估
def test():
loss_list = []
acc_list = []
mnist_model.eval()
test_data_loader = get_dataloader(train=False)
for idx, (input, y_true) in enumerate(test_data_loader ):
with torch.no_grad():
y_predict = mnist_model(input)
# cur_loss = F.nll_loss(y_predict, y_true)
cur_loss = criterion(y_predict,y_true)
pred = y_predict.max(dim=-1)[-1]
cur_acc = pred.eq(y_true).float().mean()
loss_list.append(cur_loss)
acc_list.append(cur_acc)
print(np.mean(acc_list), np.mean(loss_list))
# 6、测试及运行整个模型
if __name__ == '__main__':
test()
for i in range(3):
train(i)
test()
输出结果如下:(可以看见模型训练效果越来越好)
0.9092 0.311901
Train epoch:0 idx: 0 loss:0.2643173038959503
Train epoch:0 idx:100 loss:0.1484750360250473
Train epoch:0 idx:200 loss:0.26451829075813293
Train epoch:0 idx:300 loss:0.10198957473039627
Train epoch:0 idx:400 loss:0.19125567376613617
0.9375 0.21044251
Train epoch:1 idx: 0 loss:0.23188889026641846
Train epoch:1 idx:100 loss:0.22428396344184875
Train epoch:1 idx:200 loss:0.21237938106060028
Train epoch:1 idx:300 loss:0.2942246198654175
Train epoch:1 idx:400 loss:0.14572983980178833
0.9483 0.17821316
Train epoch:2 idx: 0 loss:0.2117220014333725
Train epoch:2 idx:100 loss:0.09646641463041306
Train epoch:2 idx:200 loss:0.20385105907917023
Train epoch:2 idx:300 loss:0.20211562514305115
Train epoch:2 idx:400 loss:0.18042239546775818
0.9511 0.1648187














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









