







1、概述
自然语言处理:也称为NLP (Natural Language Processing),是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。

2、准备数据集
2.1数据处理方法
2.1.1 tensor转换
把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W]其中(H,W,C)意思为(高,宽,通道数),黑白图片的通道数只有1,其中每个像素点的取值为[0,255],彩色图片的通道数为(R,G,B),每个通道的每个像素点的取值为[0,255],三个通道的颜色相互叠加,形成了各种颜色
from torchvision import transforms
import numpy as np
data = np.random.randint(0, 255, size=12)
img = data.reshape(2,2,3)
print(img.shape)
img_tensor = transforms.ToTensor()(img) # 转换成tensor
print(img_tensor)
print(img_tensor.shape)注意:transforms.ToTensor对象中有__call__方法,所以可以对其示例能够传入数据获取结果。
2.1.2 规范化处理
给定均值:mean,shape和图片的通道数相同(指的是每个通道的均值),方差:std,和图片的通道数相同(指的是每个通道的方差),将会把Tensor规范化处理。即:
Normalized_image=(image-mean)/std
from torchvision import transforms
import numpy as np
import torchvision
data = np.random.randint(0, 255, size=12)
img = data.reshape(2,2,3)
img = transforms.ToTensor()(img) # 转换成tensor
img = img.float()
print(img)
print("*"*100)
norm_img = transforms.Normalize((10,10,10), (1,1,1))(img) #进行规范化处理
print(norm_img)2.1.3 tensor组合
transforms.Compose([
torchvision.transforms.ToTensor(), #先转化为Tensor
torchvision.transforms.Normalize(mean,std) #在进行正则化
])2.2数据集加载
准备训练集只需将train等于True,测试集改为False。
import torchvision
#准备数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
#因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
dataset = torchvision.datasets.MNIST('/data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
#准备数据迭代器
train_dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=True)3、构建模型
3.1激活函数
常用的激活函数为Relu激活函数,他的使用非常简单Relu激活函数由import torch.nn.functional as F提供,F.relu(x)即可对x进行处理:
import torch.nn.functional as F
F.relu(b)3.2数据形状
原始输入数据为的形状:[batch_size,1,28,28]
进行形状修改:[batch_size,28*28],(全连接层是在进行矩阵的乘法操作)
第一个全连接层的输出形状:[batch_size,28],28是个人设定的,激活函数不会修改数据的形状
第二个全连接层的输出形状:[batch_size,10],因为手写数字有10个类别
构建模型的代码如下:
import torch
from torch import nn
import torch.nn.functional as F
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet,self).__init__()
self.fc1 = nn.Linear(28*28*1,28) #定义Linear的输入和输出的形状
self.fc2 = nn.Linear(28,10) #定义Linear的输入和输出的形状
def forward(self,x):
x = x.view(-1,28*28*1) #对数据形状变形,-1表示该位置根据后面的形状自动调整
x = self.fc1(x) #[batch_size,28]
x = F.relu(x) #[batch_size,28]
x = self.fc2(x) #[batch_size,10]3.3损失函数
softmax和sigmoid的区别在于我们需要去计算样本属于每个类别的概率,需要计算多次,而sigmoid只需要计算一次。softmax的公式如下:
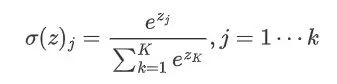
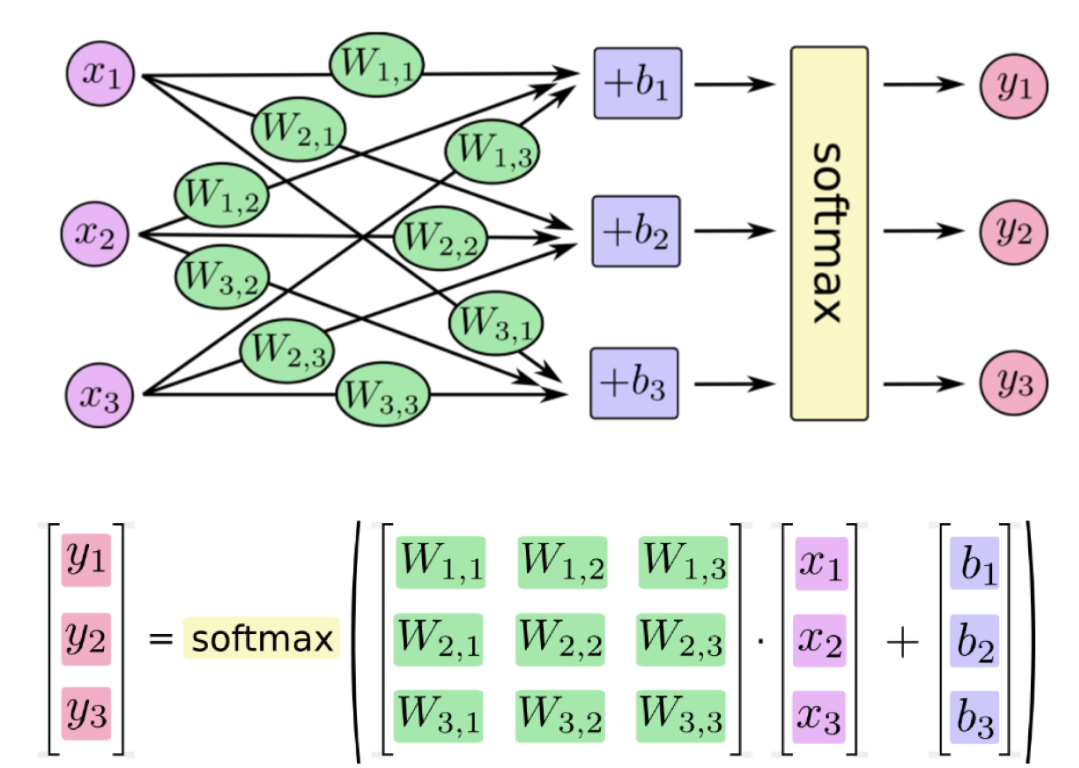
在pytorch中有两种方法实现交叉熵损失:
# 调用pytorch
criterion = nn.CrossEntropyLoss()
loss = criterion(input,target)
# 对输出值计算softmax和取对数
output = F.log_softmax(x,dim=-1)
loss = F.nll_loss(output,target)4、模型训练
训练的流程:实例化模型,设置模型为训练模式→实例化优化器类,实例化损失函数→获取,遍历dataloader→梯度置为0→进行向前计算→计算损失→反向传播→更新参数
mnist_net = MnistNet()
optimizer = optim.Adam(mnist_net.parameters(),lr= 0.001)
def train(epoch):
mode = True
mnist_net.train(mode=mode) #模型设置为训练模型
train_dataloader = get_dataloader(train=mode) #获取训练数据集
for idx,(data,target) in enumerate(train_dataloader):
optimizer.zero_grad() #梯度置为0
output = mnist_net(data) #进行向前计算
loss = F.nll_loss(output,target) #带权损失
loss.backward() #进行反向传播,计算梯度
optimizer.step() #参数更新
if idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, idx * len(data), len(train_dataloader.dataset),
100. * idx / len(train_dataloader), loss.item()))5、模型保存和加载
# 模型保存
torch.save(mnist_net.state_dict(),"model/mnist_net.pt") #保存模型参数
torch.save(optimizer.state_dict(), 'results/mnist_optimizer.pt') #保存优化器参数
# 模型加载
mnist_net.load_state_dict(torch.load("model/mnist_net.pt"))
optimizer.load_state_dict(torch.load("results/mnist_optimizer.pt"))6、模型的评估
评估的过程和训练的过程相似,但是不需要计算梯度。需要收集损失和准确率,用来计算平均损失和平均准确率,损失的计算和训练时候损失的计算方法相同。
准确率的计算:
- 模型的输出为[batch_size,10]的形状
- 其中最大值的位置就是其预测的目标值(预测值进行过sotfmax后为概率,sotfmax中分母都是相同的,分子越大,概率越大)
- 最大值的位置获取的方法可以使用`torch.max`,返回最大值和最大值的位置
- 返回最大值的位置后,和真实值(`[batch_size]`)进行对比,相同表示预测成功
def test():
test_loss = 0
correct = 0
mnist_net.eval() #设置模型为评估模式
test_dataloader = get_dataloader(train=False) #获取评估数据集
with torch.no_grad(): #不计算其梯度
for data, target in test_dataloader:
output = mnist_net(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1] #获取最大值的位置,[batch_size,1]
correct += pred.eq(target.data.view_as(pred)).sum() #预测准备样本数累加
test_loss /= len(test_dataloader.dataset) #计算平均损失
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(test_dataloader.dataset),
100. * correct / len(test_dataloader.dataset)))7、完整代码
from torch import optim
from tqdm import tqdm
import numpy as np
import torch
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import os
train_batch_size = 128
test_batch_size = 1000
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def mnist_dataset(train): #准备minist的dataset
func = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=(0.1307,),
std=(0.3081,)
)]
)
# 1. 准备Mnist数据集
return MNIST(root="./data", train=train, download=True, transform=func)
def get_dataloader(train=True):
mnist = mnist_dataset(train)
return DataLoader(mnist,batch_size=train_batch_size,shuffle=True)
class MnistModel(nn.Module):
def __init__(self):
super(MnistModel,self).__init__()
self.fc1 = nn.Linear(1*28*28,100)
self.fc2 = nn.Linear(100,10)
def forward(self, image):
image_viwed = image.view(-1,1*28*28) #[batch_size,1*28*28]
fc1_out = self.fc1(image_viwed) #[batch_size,100]
fc1_out_relu = F.relu(fc1_out) #[batch_siz3,100]
out = self.fc2(fc1_out_relu) #[batch_size,10]
return F.log_softmax(out,dim=-1)
#1. 实例化模型,优化器,损失函数
model = MnistModel().to(device)
optimizer = optim.Adam(model.parameters(),lr=1e-3)
#2. 进行循环,进行训练
def train(epoch):
train_dataloader = get_dataloader(train=True)
bar = tqdm(enumerate(train_dataloader),total=len(train_dataloader))
total_loss = []
for idx,(input,target) in bar:
input = input.to(device)
target = target.to(device)
#梯度置为0
optimizer.zero_grad()
#计算得到预测值
output = model(input)
#得到损失
loss = F.nll_loss(output,target)
#反向传播,计算损失
loss.backward()
total_loss.append(loss.item())
#参数的更新
optimizer.step()
#打印数据
if idx%10 ==0 :
bar.set_description("epcoh:{} idx:{},loss:{:.6f}".format(epoch,idx,np.mean(total_loss)))
torch.save(model.state_dict(),"model.pkl")
torch.save(optimizer.state_dict(),"optimizer.pkl")
def eval():
# 1. 实例化模型,优化器,损失函数
model = MnistModel().to(device)
if os.path.exists("model.pkl"):
model.load_state_dict(torch.load("model.pkl"))
test_dataloader = get_dataloader(train=False)
total_loss = []
total_acc = []
with torch.no_grad():
for input,target in test_dataloader: #2. 进行循环,进行训练
input = input.to(device)
target = target.to(device)
#计算得到预测值
output = model(input)
#得到损失
loss = F.nll_loss(output,target)
#反向传播,计算损失
total_loss.append(loss.item())
#计算准确率
###计算预测值
pred = output.max(dim=-1)[-1]
total_acc.append(pred.eq(target).float().mean().item())
print("test loss:{},test acc:{}".format(np.mean(total_loss),np.mean(total_acc)))
if __name__ == '__main__':
for i in range(10):
train(i)
eval()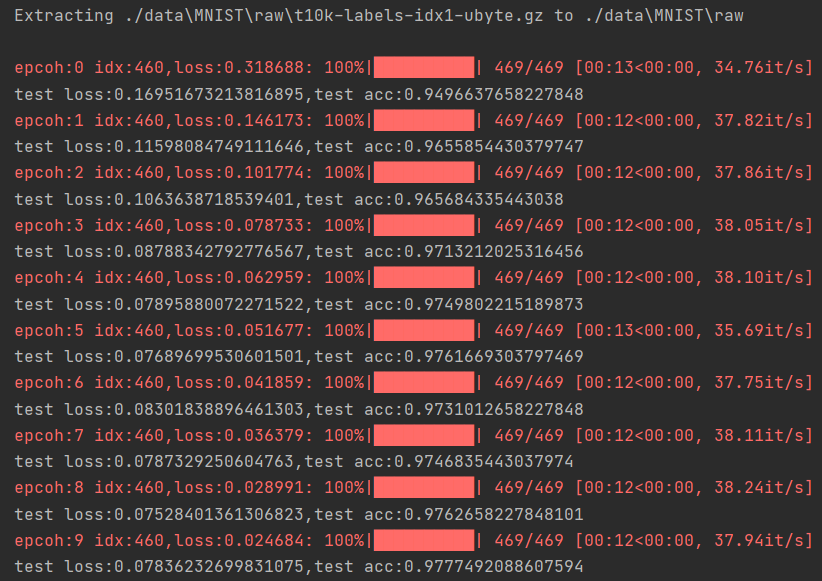
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!

















 2192
2192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











