







hadoop spark 安装步骤不再赘述
版本
hadoop版本 : hadoop-2.6.0-cdh5.14.0
spark版本 : spark-2.1.3-bin-2.6.0-cdh5.14.0
hadoop 相关配置
yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!--Autogenerated by Cloudera Manager-->
<configuration>
<!-- 设置管理ACL用户和用户组 -->
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<!--所有人都可以管理Resource Manager -->
<property>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<!--开启ResourceManager HA功能-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--自动故障转移-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--自动故障转移时是否使用内嵌的Leader选举策略选举 Active RM -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<!--ResourceManager重启后,会向已提交但尚未开始运行的应用程序发送RECOVER事件-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--zookeeper 地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk01:2181,zk02:2181,zk03:2181</value>
</property>
<!-- RM状态持久化存储的方式 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 用于计算故障转移的休眠基准(单位是毫秒) -->
<property>
<name>yarn.client.failover-sleep-base-ms</name>
<value>100</value>
</property>
<!-- 故障转移休眠最长时间(单位是毫秒)-->
<property>
<name>yarn.client.failover-sleep-max-ms</name>
<value>2000</value>
</property>
<!-- 集群标志,用于保证RM不会成为另一个集群的Active节点-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarnRM</value>
</property>
<!-- RM逻辑id列表,以逗号分割,比如:rm1,rm2。 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 对于每个rm-id,指定host:port地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop01:8032</value>
</property>
<!--指定ApplicationMasters申请资源的Scheduler的host:port地址-->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop01:8030</value>
</property>
<!--指定NodeManager连接的host:port地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop01:8031</value>
</property>
<!--指定管理命令操作的host:port地址-->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop01:8033</value>
</property>
<!--指定RM的web应用host:port地址,如果设置yarn.http.policy是HTTPS_ONLY,就没必要设置该参数-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>hadoop01:8090</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop02:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>hadoop02:8090</value>
</property>
<!-- 应用程序管理器请求的线程数 -->
<property>
<name>yarn.resourcemanager.client.thread-count</name>
<value>50</value>
</property>
<!--默认50,处理来自ApplicationMaster的RPC请求的Handler数目,比较重要 -->
<property>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>50</value>
</property>
<!--默认1,用于处理RM管理接口的线程数 -->
<property>
<name>yarn.resourcemanager.admin.client.thread-count</name>
<value>1</value>
</property>
<!-- 每个容器请求被分配的最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器内存增量 -->
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>512</value>
</property>
<!--每个容器请求被分配的最大内存 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<!--每个容器请求被分配的最小核数 -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<!--容器核数增量 -->
<property>
<name>yarn.scheduler.increment-allocation-vcores</name>
<value>1</value>
</property>
<!--每个容器请求被分配的最大核数 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>16</value>
</property>
<!--cpu设置为服务器2~3倍 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<!--内存设置为服务器80% 单位 k-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>25600</value>
</property>
<!-- RM应该多久检查一次AM是否还活着-->
<property>
<name>yarn.resourcemanager.amliveliness-monitor.interval-ms</name>
<value>1000</value>
</property>
<!--应用程序主报告的到期间隔 -->
<property>
<name>yarn.am.liveness-monitor.expiry-interval-ms</name>
<value>600000</value>
</property>
<!-- 应用程序尝试的最大次数 -->
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>2</value>
</property>
<!--多长时间检查一次容器是否仍然存活 -->
<property>
<name>yarn.resourcemanager.container.liveness-monitor.interval-ms</name>
<value>600000</value>
</property>
<!--多久检查一次节点管理器是否仍然存活 -->
<property>
<name>yarn.resourcemanager.nm.liveness-monitor.interval-ms</name>
<value>1000</value>
</property>
<!--等待多长时间,直到节点管理器被认为已死。 -->
<property>
<name>yarn.nm.liveness-monitor.expiry-interval-ms</name>
<value>600000</value>
</property>
<!-- 处理资源跟踪器调用的线程数。 -->
<property>
<name>yarn.resourcemanager.resource-tracker.client.thread-count</name>
<value>50</value>
</property>
<!--调度器类型 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${HADOOP_HOME}/etc/hadoop/fair-scheduler.xml</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>false</value>
<description>default is True</description>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>default is True</description>
</property>
<!--RM保留的已完成应用程序的最大数量 -->
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>10000</value>
</property>
<!-- 日志聚合地址 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<!-- 远程日志目录子目录名称(启用日志聚集功能时有效) -->
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<!--后加 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--启用日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--聚合后的日志在HDFS上保存多长时间,单位为s 设置为3天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>259200</value>
</property>
<!--删除任务在HDFS上执行的间隔 3天 -->
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>259200</value>
</property>
<!--当不启用日志聚合此参数生效,日志文件保存在本地的时间,单位为s 默认3分钟 -->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<!-- -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!--指定运行mapreduce的环境是yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MapReduce JobHistory Server IPC host:port -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MapReduce JobHistory Server Web UI host:port -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<!-- The directory where MapReduce stores control files.默认 ${hadoop.tmp.dir}/mapred/system -->
<property>
<name>mapreduce.jobtracker.system.dir</name>
<value>${HADOOP_HOME}/data/system/jobtracker</value>
</property>
<!-- The amount of memory to request from the scheduler for each map task. 默认 1024-->
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<!-- The amount of memory to request from the scheduler for each reduce task. 默认 1024-->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
<!-- 用于存储文件的缓存内存的总数量,以兆字节为单位。默认情况下,分配给每个合并流1MB,给个合并流应该寻求最小化。默认值100-->
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
<!-- 整理文件时用于合并的流的数量。这决定了打开的文件句柄的数量。默认值10-->
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>10</value>
</property>
<!-- 默认的并行传输量由reduce在copy(shuffle)阶段。默认值5-->
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>25</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx1024m</value>
</property>
<!-- MR AppMaster所需的内存总量。默认值1536-->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1536</value>
</property>
<!-- MapReduce存储中间数据文件的本地目录。目录不存在则被忽略。默认值${hadoop.tmp.dir}/mapred/local-->
<property>
<name>mapreduce.cluster.local.dir</name>
<value>${HADOOP_HOME}/data/system/local</value>
</property>
</configuration>
fair-scheduler.xml
在 yarn-site.xml 配置中yarn调度类型使用fair 如果是此类型 可参考以下配置
yarn-site.xml 中配置 yarn.scheduler.fair.allocation.file 文件路径 创建文件
<?xml version="1.0"?>
<allocations>
<!-- users max running apps -->
<userMaxAppsDefault>30</userMaxAppsDefault>
<!-- 定义队列 -->
<queue name="root">
<!-- 最小使用资源:1%内存,1%处理器核心 -->
<minResources>1% memory,1% cpu</minResources>
<!-- 最大使用资源:95%G内存,95%处理器核心 -->
<maxResources>95% memory,95% cpu</maxResources>
<!-- 最大可同时运行的app数量:50-->
<maxRunningApps>50</maxRunningApps>
<!-- weight:资源池权重 -->
<weight>1.0</weight>
<!-- 调度模式:fair-scheduler -->
<schedulingMode>fair</schedulingMode>
<!-- 允许提交任务的用户名和组,格式为:用户名 用户组 -->
<!-- 当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组 -->
<aclSubmitApps> </aclSubmitApps>
<!-- 允许管理任务的用户名和组,格式同上 -->
<aclAdministerApps> </aclAdministerApps>
<!-- default队列配置资源 -->
<queue name="default">
<minResources>1% memory,1% cpu</minResources>
<maxResources>30% memory,30% cpu</maxResources>
<maxRunningApps>10</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<!-- 所有的任务如果不指定任务队列,都提交到default队列里面来 -->
<aclSubmitApps>*</aclSubmitApps>
</queue>
<!-- hadoop队列配置资源 -->
<queue name="hadoop">
<minResources>1% memory,1% cpu</minResources>
<maxResources>95% memory,95% cpu</maxResources>
<maxRunningApps>50</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
<!-- 备用队列配置资源 -->
<queue name="default-01">
<minResources>1% memory,1% cpu</minResources>
<maxResources>50% memory,50% cpu</maxResources>
<maxRunningApps>20</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
</queue>
</allocations>
spark 相关配置
spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:8020/spark/history
spark.history.fs.cleaner.enabled true
spark.history.fs.cleaner.interval 1d
spark.history.fs.cleaner.maxAge 2d
spark.yarn.historyServer.address=http://hadoop01:18080
spark.yarn.jars hdfs://hadoop01:8020/spark/jars/*
spark.network.timeout 10000000
spark.executor.heartbeatInterval 10000000
spark-env.sh
#配置java环境变量
export JAVA_HOME=/data/jdk1.8
#指定spark Master的IP
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk01:2181,zk02:2181,zk03:2181 -Dspark.deploy.zookeeper.dir=/spark"
#spark history server
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/spark/history -Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=1"
#指定spark Master的端口
export SPARK_MASTER_PORT=7077
#yarn环境不指定master
#export SPARK_MASTER_HOST=hadoop01
#spark执行时临时目录
export SPARK_LOCAL_DIRS=${SPARK_HOME}/tmp
#hadoop环境变量
export HADOOP_HOME=${HADOOP_HOME}
#hadoop的配置文件目录
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
运行测试
集群启动
hadoop启动
cd ${HADOOP_HOME}/sbin
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver #启动yarn 历史服务器
spark his 服务器启动
cd ${SPARK_HONE}/sbin
./start-history-server.sh
页面验证
yarn web
hadoop01:8088
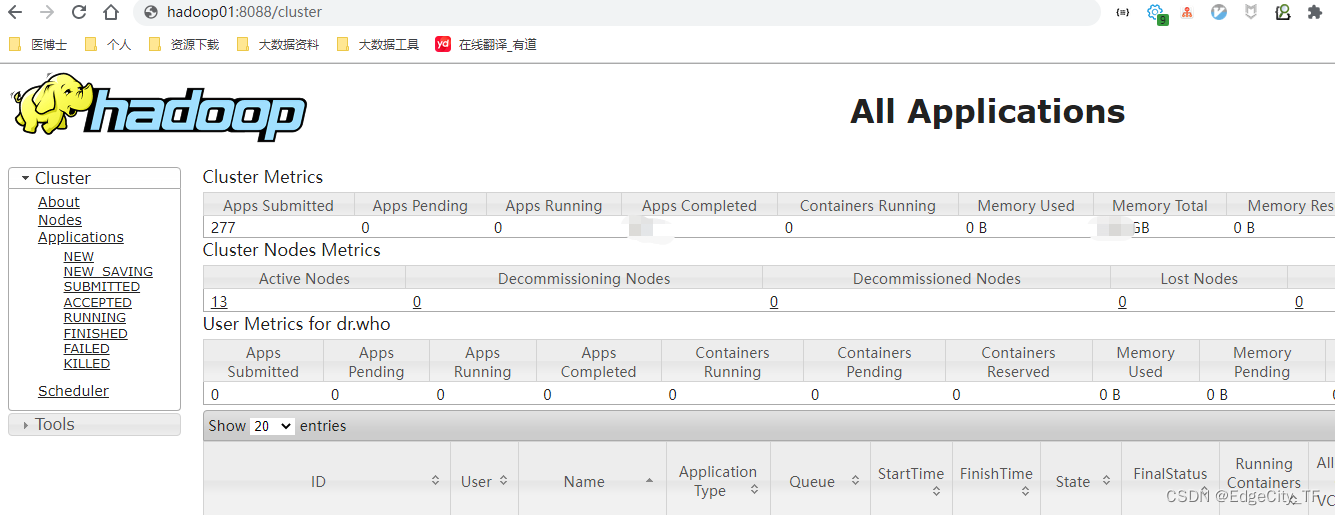
yarn his web
hadoop01:19888
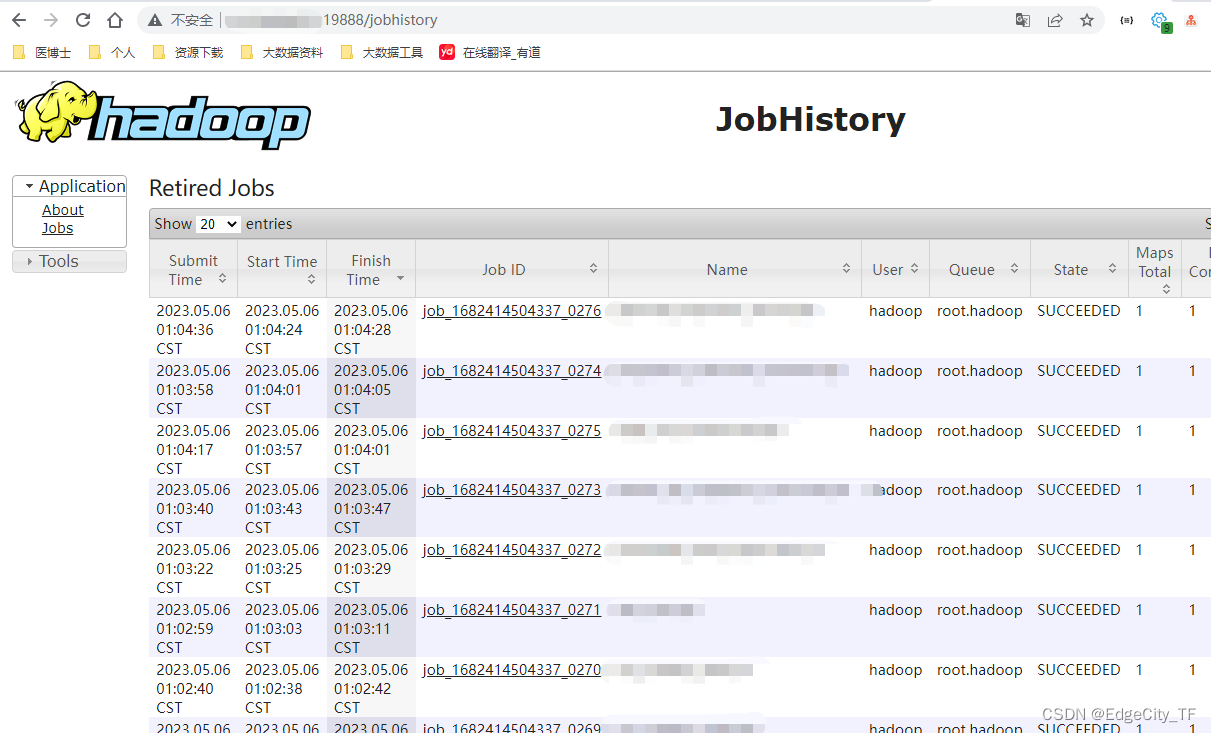
spark on yarn 测试
spark on yarn 不用启动集群
提交脚本
注意:行尾不能有空格
${SPARK_HOME}/bin/spark-submit \
--queue hadoop \ #使用hadoop队列
--class com.xxx.sparkdemo \
--master yarn-client \ # 或者 yarn-cluster
--num-executors 3 \
--executor-cores 2 \
--driver-memory 1g \
--executor-memory 2g \
--total-executor-cores 6 \
--conf spark.sql.shuffle.partitions=320 \
--conf spark.yarn.executor.memoryOverhead=1024 \
--conf spark.core.connection.ack.wait.timeout=700 \
--conf spark.sql.autoBroadcastJoinThreshold=-1 \
--conf spark.scheduler.mode=FAIR \
/data/spark.jar
**spark 运行时点击Tracking URL 自动跳转至spark运行页面
spark 结束点击Tracking URL 自动跳转至spark 历史web **
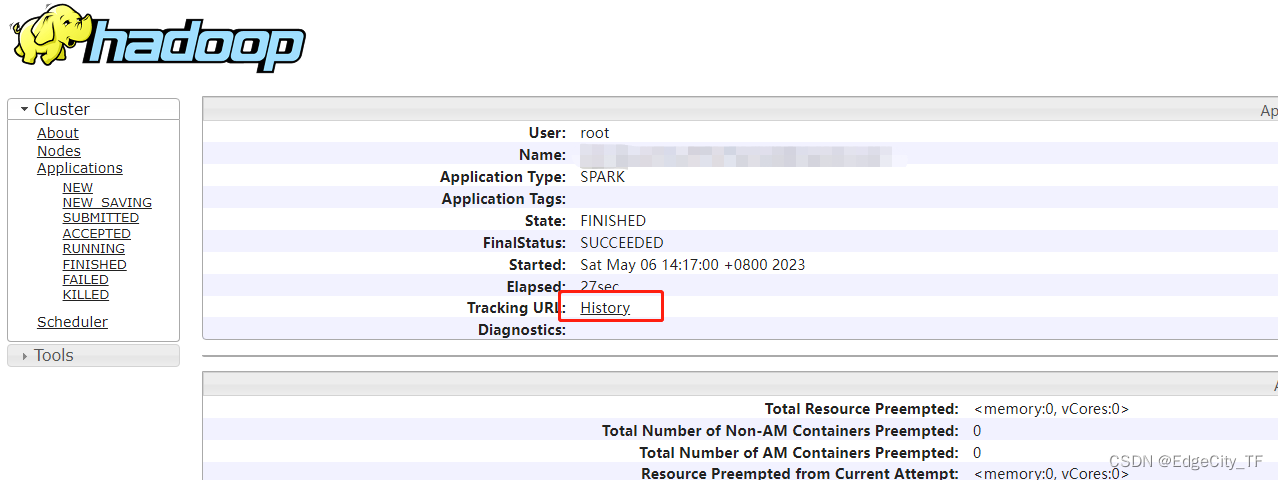
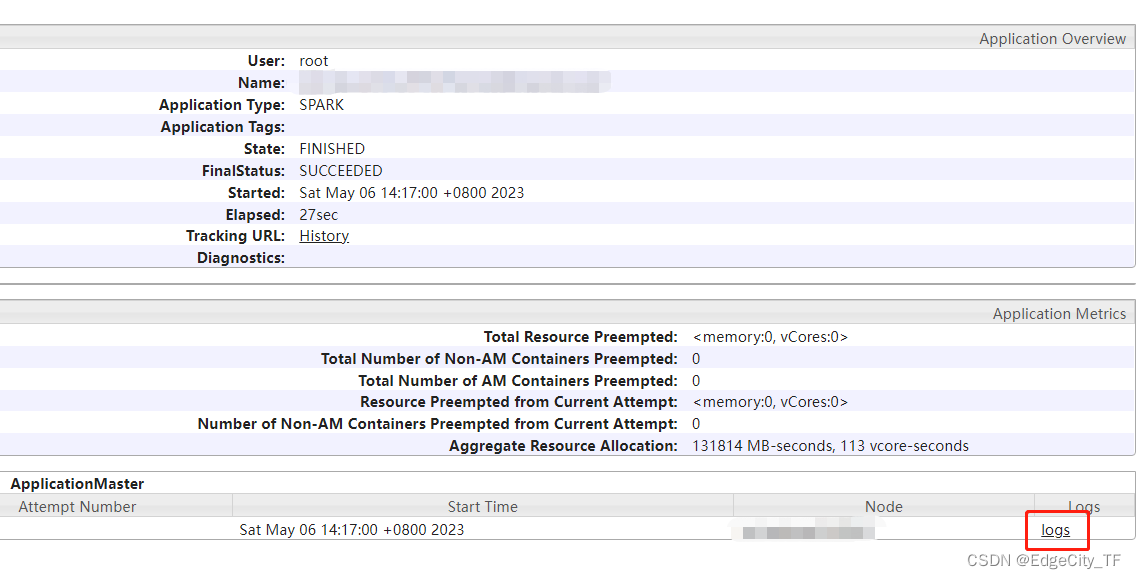
可以点击 logs 查看运行日志

附带spark-streaming 启停脚本
因spark实时任务长时间运行会造成单个日志体积过大,卡顿
#!/bin/bash
ApplicationName=StreamingDemo
usage(){
echo "Usage: sh restart.sh [start|stop|restart]"
exit 1
}
pid_is_exist(){
#获取指定名称的 application id
PID=$(yarn application -list | grep ${ApplicationName} | grep -v grep | awk '{ print $1 }')
echo "PID:${PID}"
if [ -z "${PID}" ]
then
return 1
else
return 0
fi
}
start(){
pid_is_exist
if [ $? -eq 0 ]
then
echo "ParseLog76 is already running. pid=${PID}"
else
${SPARK_HOME}/bin/spark-submit \
--class com.XXX.XXX.StreamingDemo \
--queue hadoop \
--master yarn-cluster \
--num-executors 2 \
--executor-cores 2 \
--driver-memory 1g \
--executor-memory 1g \
--conf spark.sql.shuffle.partitions=4 \
--conf spark.yarn.executor.memoryOverhead=1024 \
--conf spark.core.connection.ack.wait.timeout=700 \
--conf spark.sql.autoBroadcastJoinThreshold=-1 \
--conf spark.scheduler.mode=FAIR \
/data/streaming_demo.jar
fi
}
stop(){
pid_is_exist
if [ $? -eq 0 ]
then
yarn application -kill ${PID}
while true
do
pid_is_exist
if [ $? -eq 0 ]; then
echo sleep 1s, waiting for application:${PID} to stop
sleep 1
else
echo the process ${PID} has already stopped
break
fi
done
else
echo Application has already stopped
fi
}
restart(){
stop
start
}
case "$1" in
"start")
start
;;
"stop")
stop
;;
"restart")
restart
;;
*)
usage
;;
esac















 1234
1234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











