



在开源情报(OSINT)领域,“数据过载”早已不是新问题,而是常态。每天,互联网产生海量信息,其中真正有价值的“信号”被淹没在无尽的“噪音”之中。分析师们疲于奔命,却常常陷入“看得见,找不到;找得到,看不完”的困境。

大模型的出现,无疑为这一困局带来了新的解题思路。然而,热潮之下,我们更需要冷静思考:大模型究竟该如何落地,才能真正为OSINT工作流带来质的提升?

在易海聚,我们的答案很明确:大模型不是替代分析师,而是给开源情报分析师提供强大的工具。在于将他们从繁重、低效的信息处理环节中解放出来,聚焦于更高阶的研判与决策。过去一年,我们将大模型能力深度融入到系统的采集、处理与分析全链条,积累了一些务实的经验,愿在此与同行分享。
一、源头减负:从“广撒网”到“精准捕捞”
解决数据过载,最有效的办法是从源头上减少无效数据的摄入。与其在海量垃圾信息中大海捞针,不如把精力聚焦在那些真正能产出高质量情报的“专业信源”上。
我们的实践路径是,将大模型的洞察力与专业的领域知识相结合,构建一个动态演进的高质量信源库,并辅以智能化的采集运维体系。
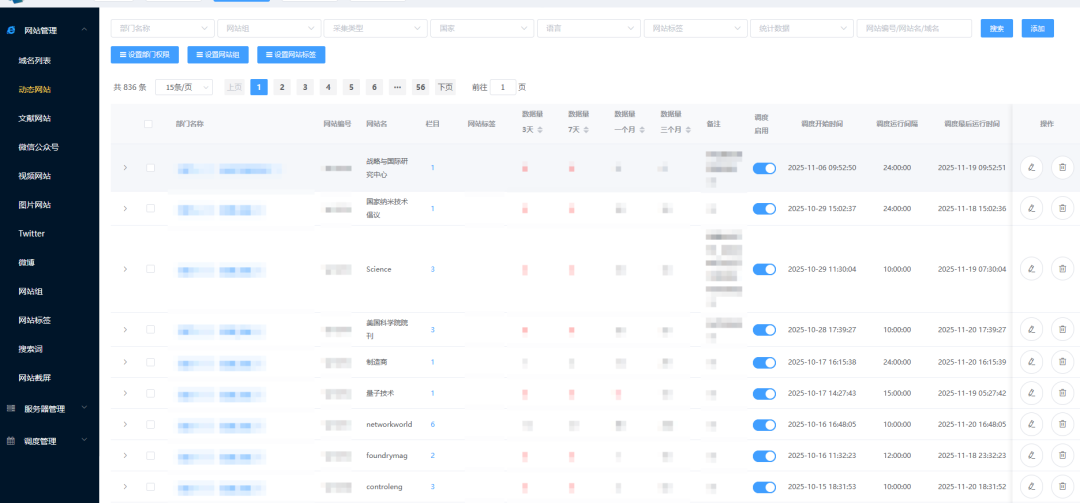
首先,我们并非简单地依赖关键词去全网搜索,而是通过领域专家知识图谱和历史情报回溯,系统性地梳理和发现全球范围内与客户业务高度相关的专业网站。 这包括特定行业的权威媒体、核心企业的投资者关系页面、顶尖研究机构的出版物平台、以及关键人物的个人博客等。这个信源库不是静态的,系统会持续监控网络动态,自动发现并推荐新的、有潜力的专业站点,经人工确认后纳入监控范围。
其次,针对每一个纳入监控的高质量网站,我们都进行精细化的采集配置。 这不仅仅是配置一个URL,而是深入分析其页面结构、内容发布规律、反爬策略等,定制专属的采集脚本。这种“一源一策”的模式,确保了数据抓取的完整性和准确性。
最后,也是最关键的,是智能化的采集运维。 互联网环境瞬息万变,网站改版、IP封锁是常态。我们的系统内置了智能调度与自适应能力:
智能调度:根据网站的更新频率和重要性,以及采集服务器的性能情况,动态调整采集任务的优先级和频次。
IP和账号自动切换:集成高可用的代理IP池和网站备用登录账号,当遭遇访问限制时,能自动切换IP地址或者账号,保障采集任务不中断。
网站健康监测:定期对目标网站进行截屏比对和内容校验,一旦发现页面结构重大变更或内容异常,立即告警,通知运维人员及时调整采集策略。
通过这套“精准锁定信源 + 精细配置策略 + 智能运维保障”的组合拳,我们实现了真正的“精准捕捞”。不仅大幅减少了无效数据的摄入,更从根本上保障了情报源头的稳定与可靠。
二、深度提纯:构建高质量的情报“净水厂”
即便经过了源头过滤,流入系统的信息依然良莠不齐。如何将这些原始数据快速、准确地转化为结构化的、可供分析的知识,是OSINT流程中的关键瓶颈。
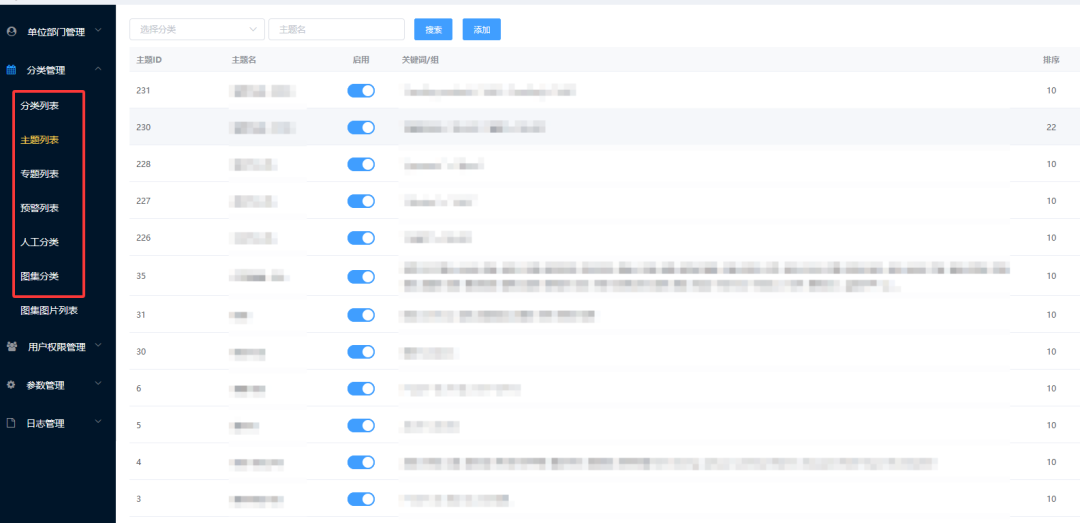
为此,我们在数据处理层构建了一套完整的“智能提纯”流水线,核心包含智能过滤、自动分类/打标、深度解析三大环节。
首先是智能过滤。 我们利用大模型对文本质量进行多维度评估,形成一套文章智能打分算法。该算法不仅考虑关键词的匹配度,还会综合判断文章的原创性、信息密度、逻辑连贯性以及来源可信度等多个因子。一篇由专业机构发布的深度分析报告,其得分会远高于一篇充斥着营销话术的软文。系统会根据预设的阈值,自动过滤掉低分内容,确保进入分析师视野的都是经过初步“提纯”的高质量信息。
其次是自动分类与打标。 这是将海量信息变得有序、可管理的关键一步。系统会根据预设的业务分类体系(如“市场动态”、“技术研发”、“供应链”、“政策法规”等),利用大模型对文章内容进行语义理解,自动将其归入最合适的类别。同时,系统会为每篇文章自动打上一系列精细化的标签,这些标签既包括通用的关键词,也包括从文本中抽取的专业实体(如公司名、产品名、技术术语、地理位置等)。通过自动分类和打标,原本杂乱无章的信息流被组织成一个结构化的知识库,为后续的快速检索、专题分析和知识图谱构建奠定了坚实基础。
最后是深度解析。 面对PDF财报、技术白皮书等非结构化文档,我们利用大模型强大的上下文理解能力,进行精细化的信息抽取。系统能像一位专业分析师那样去“阅读”文档,准确识别并提取出财务报表中的关键指标(如EBITDA、自由现金流)、项目文档中的里程碑节点等。抽取结果会被自动标准化,并关联到相应的分类和标签体系中。
通过这套“过滤-分类/打标-解析”的组合拳,我们成功地将原始数据流转化为了结构清晰、质量可靠的情报“净水”,极大地提升了整个OSINT工作流的效率与产出质量。
三、价值聚焦:让每一篇文章“开口说话”
解决了源头过滤和数据提纯的问题后,分析师面临的下一个挑战是:即便面对的都是高质量文章,数量依然庞大,阅读和消化的成本极高。如何让分析师在几秒钟内就抓住一篇文章的核心价值,是提升效率的关键。
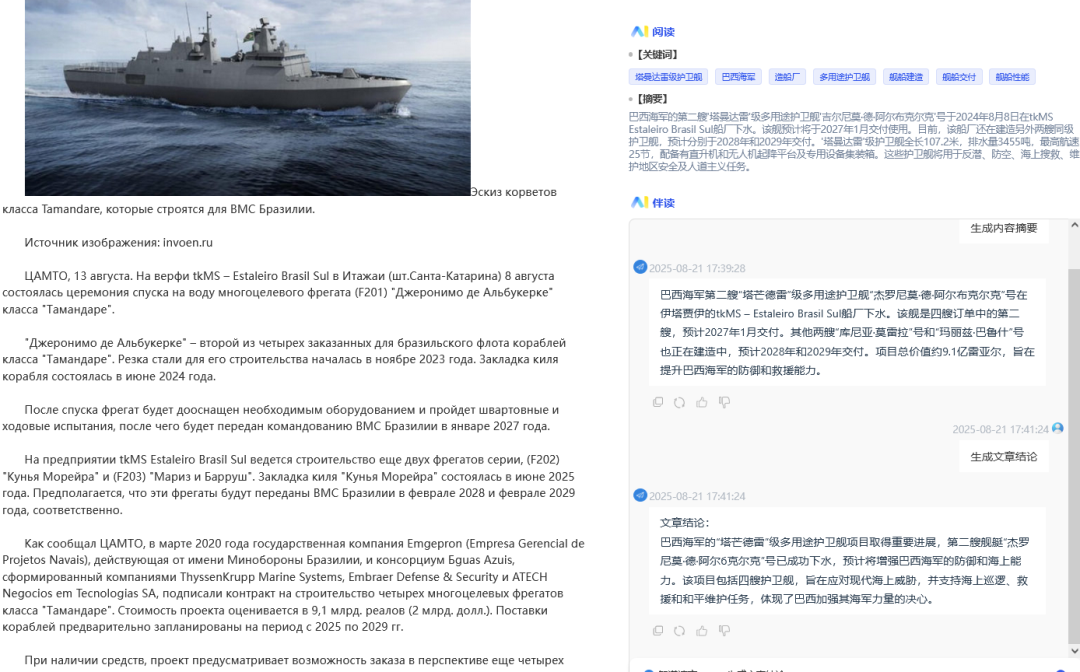
我们的解决方案是,利用大模型对每一篇入库的文章进行深度“解构”和“浓缩”,让文章自己“开口说话”,直接向分析师汇报其最核心的内容。
具体而言,我们为每篇文章自动生成四个关键智能产物:
智能摘要:生成一段简洁、准确的摘要,概括文章的核心事件或观点。
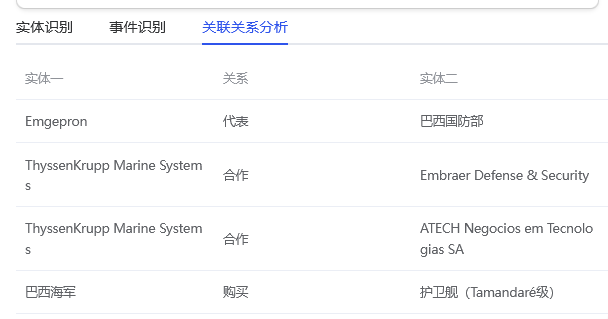
核心实体与关系:自动识别并高亮文章中涉及的关键实体(如公司、人物、技术),并描述它们之间的关系。
要点清单:将文章中的关键信息点,以清晰的条目式列表呈现。
智能问答:预先生成几个与文章内容最相关的问题及其答案。
通过这种方式,分析师在信息列表中,无需点开原文,就能对文章的核心价值做出快速判断。这极大地缩短了信息筛选和初步理解的时间。
四、主动服务:从“人找信息”到“信息找人”
在实现了对单篇文章的深度价值挖掘后,我们进一步思考:能否更进一步,让系统主动将最相关、最有价值的信息推送给最需要的人?
答案是肯定的。我们将上述的智能分析能力与用户的个性化订阅和操作习惯相结合,构建了一套主动推荐引擎。
系统不仅知道用户订阅了哪些关键词或主题,还通过学习用户的长期操作行为(如经常收藏哪类文章、对哪些实体感兴趣),构建了动态的用户兴趣画像。当一篇新文章入库,并被大模型解析出其核心价值点后,推荐引擎会实时计算该文章与各个用户画像的匹配度。

对于匹配度极高的文章,系统会主动推送,并在推送摘要中直接展示文章的核心要点、关键实体和预设问答。用户收到的不再是冰冷的标题列表,而是一份份已经过深度加工、直击要害的“情报简报”。
这种模式,彻底颠覆了传统的“人找信息”范式,实现了“信息找人”。它确保了分析师的时间被用在刀刃上——只关注那些与自己工作最相关、价值密度最高的信息,从而真正破解了“数据过载”的终极困局。
更多热门阅读
【开源情报系统介绍】开源情报搜集系统:科研创新的强大引擎
【情报系统应用案例】案例视角下的开源情报搜集系统应用实践
【大模型的应用】大模型在开源情报搜集系统中的应用汇总
【情报系统构建】不止于“爬”:如何构建真正可靠的情报采集系统
【易海聚系统介绍】易海聚科研开源情报系统介绍
—————————————————————
易海聚:信息搜集,信息整合,信息分析!

业务咨询、技术交流合作请联系:


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









