







Image classification using Vision Transformer with AMD GPUs — ROCm Blogs

2024年4月4日 发布 作者:Eliot Li.
Vision Transformer (ViT) 模型最早在论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中被提出。由于在计算机视觉领域中具有出色的可扩展性和适应性,ViT 成为传统卷积神经网络(CNN)模型的有吸引力的替代方案。然而,对于较大输入图像,ViT 由于其计算复杂度与输入尺寸的二次关系,可能比 CNN 更加昂贵。
本文演示了如何在运行 AMD GPU 和 ROCm 软件的环境中使用 ViT 模型。
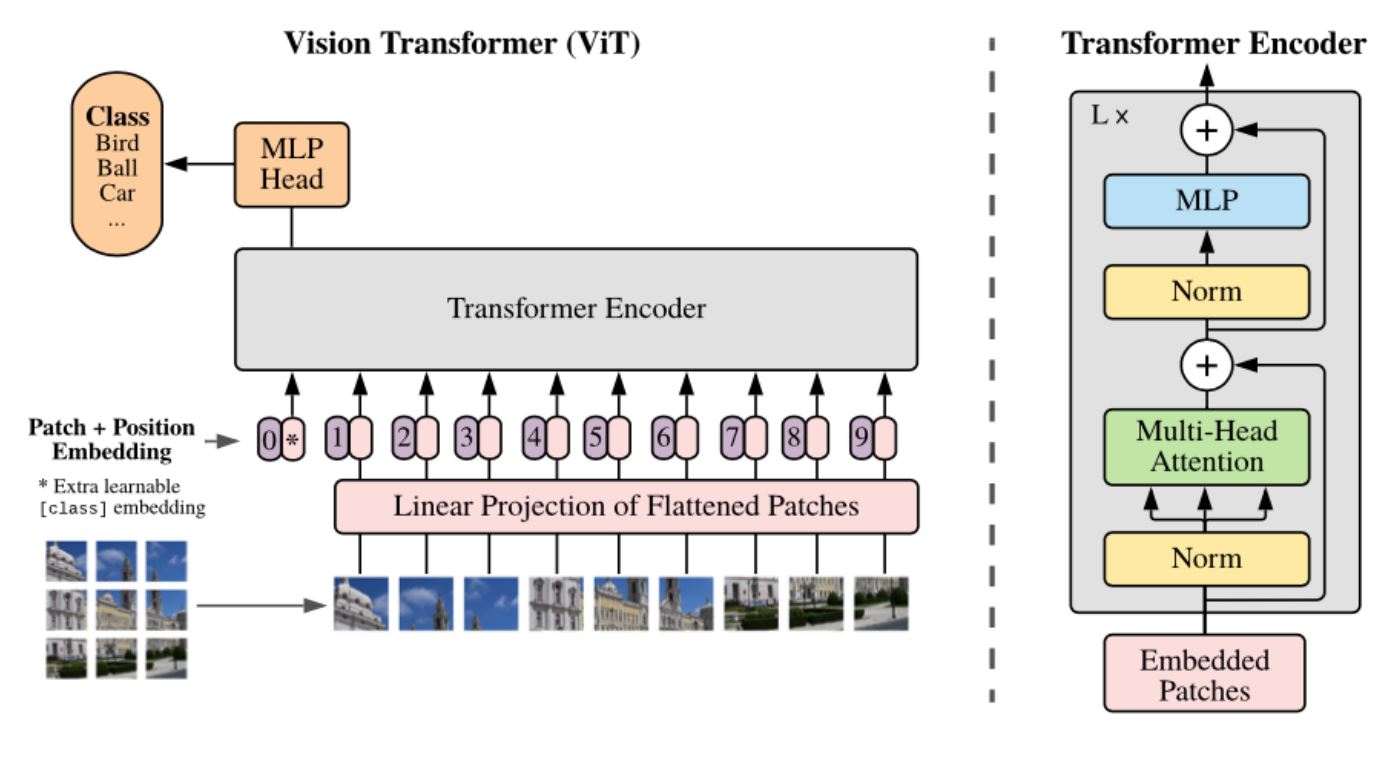
上图取自原始论文,展示了 ViT 的架构。
部分代码来自 Niels Rogge 的博客:Quick demo: Vision Transformer (ViT) by Google Brain
设置
本文中的代码已在单个 AMD MI210 GPU 上测试,使用的是安装了 ROCm 6.0 和 PyTorch 2.2 的 Docker 镜像。它同样可以在任何 ROCm 支持的 GPU 上运行。
软件
你可以在 Docker Hub 上找到本次演示中使用的 Docker 镜像,使用以下命令:
docker run -it --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \ --device=/dev/kfd --device=/dev/dri --group-add video \ --ipc=host --shm-size 8G rocm/pytorch:latest
有关如何安装 ROCm 和 PyTorch 的详细信息,请访问:
检查是否安装了正确版本的 ROCm,使用以下命令:
apt show rocm-libs -a
Package: rocm-libs Version: 6.0.0.60000-91~20.04 Priority: optional Section: devel Maintainer: ROCm Dev Support <rocm-dev.support@amd.com> Installed-Size: 13.3 kB Depends: hipblas (= 2.0.0.60000-91~20.04), hipblaslt (= 0.6.0.60000-91~20.04), hipfft (= 1.0.12.60000-91~20.04), hipsolver (= 2.0.0.60000-91~20.04), hipsparse (= 3.0.0.60000-91~20.04), hiptensor (= 1.1.0.60000-91~20.04), miopen-hip (= 3.00.0.60000-91~20.04), half (= 1.12.0.60000-91~20.04), rccl (= 2.18.3.60000-91~20.04), rocalution (= 3.0.3.60000-91~20.04), rocblas (= 4.0.0.60000-91~20.04), rocfft (= 1.0.23.60000-91~20.04), rocrand (= 2.10.17.60000-91~20.04), hiprand (= 2.10.16.60000-91~20.04), rocsolver (= 3.24.0.60000-91~20.04), rocsparse (= 3.0.2.60000-91~20.04), rocm-core (= 6.0.0.60000-91~20.04), composablekernel-dev (= 1.1.0.60000-91~20.04), hipblas-dev (= 2.0.0.60000-91~20.04), hipblaslt-dev (= 0.6.0.60000-91~20.04), hipcub-dev (= 3.0.0.60000-91~20.04), hipfft-dev (= 1.0.12.60000-91~20.04), hipsolver-dev (= 2.0.0.60000-91~20.04), hipsparse-dev (= 3.0.0.60000-91~20.04), hiptensor-dev (= 1.1.0.60000-91~20.04), miopen-hip-dev (= 3.00.0.60000-91~20.04), rccl-dev (= 2.18.3.60000-91~20.04), rocalution-dev (= 3.0.3.60000-91~20.04), rocblas-dev (= 4.0.0.60000-91~20.04), rocfft-dev (= 1.0.23.60000-91~20.04), rocprim-dev (= 3.0.0.60000-91~20.04), rocrand-dev (= 2.10.17.60000-91~20.04), hiprand-dev (= 2.10.16.60000-91~20.04), rocsolver-dev (= 3.24.0.60000-91~20.04), rocsparse-dev (= 3.0.2.60000-91~20.04), rocthrust-dev (= 3.0.0.60000-91~20.04), rocwmma-dev (= 1.3.0.60000-91~20.04) Homepage: https://github.com/RadeonOpenCompute/ROCm Download-Size: 1046 B APT-Manual-Installed: yes APT-Sources: http://repo.radeon.com/rocm/apt/6.0 focal/main amd64 Packages Description: Radeon Open Compute (ROCm) Runtime software stack
你还需要从 Hugging Face 安装 transformers 软件包。
pip install -q transformers
硬件
支持的硬件列表,请访问ROCm 系统要求页面.
检查你的硬件,确保系统识别 AMD GPU。
rocm-smi --showproductname
============================ ROCm System Management Interface ============================ ====================================== Product Info ====================================== GPU[0] : Card series: 0x740f GPU[0] : Card model: 0x0c34 GPU[0] : Card vendor: Advanced Micro Devices, Inc. [AMD/ATI] GPU[0] : Card SKU: D67301V ========================================================================================== ================================== End of ROCm SMI Log ===================================
确保 PyTorch 也能识别 GPU。
import torch
print(f"number of GPUs: {torch.cuda.device_count()}")
print([torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())])
number of GPUs: 1 ['AMD Instinct MI210']
加载 ViT 模型
从 Hugging Face 加载预训练的 ViT 模型 vit-base-patch16-224。
from transformers import ViTForImageClassification
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
model.to(device)
图像分类
加载一个未授权的 图片 供模型分类。
from PIL import Image import requests url = 'https://images.pexels.com/photos/19448090/pexels-photo-19448090.png' image = Image.open(requests.get(url, stream=True).raw) image

ViT 模型接受 224x224 分辨率的输入图像。你可以使用 ViTImageProcessor 进行标准化和调整图像大小,使其适合于模型。
from transformers import ViTImageProcessor
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
检查图像是否具有正确的大小。`pixel_values` 张量的形状表示 [batch, channel, height, width]。
print(pixel_values.shape)
torch.Size([1, 3, 224, 224])
处理过的图像显示了正确的大小。要查看输出图像,请使用:
import torchvision from torchvision.io import read_image import torchvision.transforms as T T.ToPILImage()(pixel_values[0])

正如预期的,处理过的图像是原始图像的标准化和调整大小的版本。
该模型已被训练用来将图像分类到 1,000 个类别中的一个。以下是该模型支持的一些示例类别。
import random
random.seed(1002)
i = 0
while i < 10:
print(model.config.id2label[random.randint(0, 999)])
i = i+1
dishrag, dishcloth jeep, landrover bassinet traffic light, traffic signal, stoplight briard grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus bittern Siamese cat, Siamese china cabinet, china closet flamingo
现在你已经准备好使用 ViT 模型对图像进行分类了。ViT 模型由一个类似 BERT 的编码器和一个顶层的线性分类头部组成,该头部基于最后隐藏状态的 [CLS](分类)标记。模型的输出是图像属于模型已训练的 1,000 个类别中的每一个的 logit(对数几率)。分类结果就是 logit 值最高的类别。
with torch.no_grad():
outputs = model(pixel_values)
logits = outputs.logits
print("Total number of classes:", logits.shape[1])
prediction = logits.argmax(-1)
print("Predicted class:", model.config.id2label[prediction.item()])
Total number of classes: 1000 Predicted class: leopard, Panthera pardus
模型识别正确了!你可以尝试用其他图像来测试一下这个模型在你的 AMD GPU 上的表现。
要了解更多关于 Vision Transformer 的内容,请访问: 来自 Google Research 的官方 Vision Transformer 仓库.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











