






Optimize GPT Training: Enabling Mixed Precision Training in JAX using ROCm on AMD GPUs — ROCm Blogs

这篇博客基于我们在 在 AMD GPU 上使用 JAX 实现和训练生成预训练变压器 (GPT) 的指南 中讨论的 nanoGPT 模型。在这里,我们将向您展示如何将混合精度训练纳入我们之前博客中讨论的 JAX 实现的 nanoGPT 模型中。
一般来说,混合精度训练通过混合半精度和全精度浮点表示来调整标准的全精度深度学习方法。这种灵活的混合方法允许混合精度训练在不牺牲模型整体性能的情况下,实现更高的计算效率,节省时间和内存。
在这篇博客文章中,我们将逐步向您展示如何使用 ROCm 在 AMD GPU 上将我们之前提供的 JAX 实现的 nanoGPT 模型修改为混合精度训练,以实现更快和更高效的训练。
注: 因为在 在 AMD GPU 上使用 JAX 实现和训练生成预训练变压器 (GPT) 的指南 中已经提供了创建 JAX 实现的 nanoGPT 模型的指南,这里将不再重复这些说明。
背景
标准的深度学习方法通过使用32位浮点精度(FP32)进行神经网络计算,以确保数值稳定性和准确性。然而,观察表明,诸如卷积和矩阵乘法等操作并不总是需要如此高的精度。此外,深度学习中一种重要的优化算法——随机梯度下降(SGD)已多次证明,尽管引入了梯度波动,模型依然能够有效收敛,并在实际操作中继续证明这一点。
基于这些见解,混合精度训练作为一种提高训练效率的策略应运而生。这种技术策略性地使用较低精度的格式,例如16位浮点(FP16),来处理计算量大的任务,如矩阵乘法。与FP32相比,FP16计算速度更快且消耗更少的内存。FP16的这种内存使用量减少可以加速训练吞吐量,并在GPU内存限制内处理更大的批量大小或更大的模型。
为了在混合精度训练期间保持数值稳定性,诸如梯度累积和权重更新等关键操作继续使用FP32精度。这种混合方法利用了FP16的速度优势,同时减少了潜在的精度问题,从而优化了深度学习应用中模型训练的整体效率。
由于FP16比FP32精度更低,非常小的梯度值在FP32精度下接近于零,而在FP16精度下会变为0。这可能导致模型训练过程无法收敛。为了确保数值稳定性,混合精度训练使用了一种称为梯度缩放的数值技术:它将损失放大,使得反向传播的梯度分布在FP16的精度范围内。然后它将放大的FP16梯度转换为FP32,再将其缩放回原来的大小,更新权重。这个技术有效地解决了训练过程中可能出现的下溢问题。
总结而言,混合精度训练流程包括以下步骤:
-
将模型权重从FP32转换为FP16,同时保留FP32格式的权重副本。
-
以FP16进行前向传递,然后将结果转换为FP32以计算损失。
-
放大损失,将其转换为FP16,进行反向传播,并生成FP16格式的梯度。
-
将梯度转换回FP32,缩放回原来的大小,并应用任何附加的梯度操作技术,如梯度截断。
-
使用FP32梯度更新FP32模型权重。
-
重复步骤1到5,直到达到终止条件。
请注意,放大损失有时会导致梯度溢出。为了处理这种情况,我们可以使用动态缩放方法。这种方法涉及在发生溢出时缩小缩放系数,并在若干次迭代无溢出时增大缩放系数。有关实施此技术的更多详细信息,可以参考JAX混合精度训练文档此处。
放大损失有时会导致梯度溢出。在这种情况下,使用动态缩放方法。动态缩放方法涉及在任何时候发生溢出时减小缩放系数,并在若干次迭代且无溢出后增加缩放系数。有关实施该技术的更多详细
信息,请参阅JAX中的混合精度训练。
环境配置
我们在配备了ROCm 6.1的AMD GPU上,在一个名为`jax-build`的容器中运行实现。或者,你可以使用带有最新版本JAX的docker镜像,因为较新的版本可能包含更多优化。尽管我们在博客中使用了AMD GPU,我们的代码并不包含任何特定于AMD的修改。这突显了ROCm对关键深度学习框架如JAX的适应性。
-
[可选] 检查支持的操作系统和AMD硬件的列表,以确保你的操作系统和硬件受支持。
-
在Linux shell中使用以下代码拉取并运行docker容器:
docker run -it --ipc=host --network=host --device=/dev/kfd --device=/dev/dri \ --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \ --name=nanogpt rocm/jax-build:rocm6.1.1-jax0.4.30-py3.10.14 /bin/bash -
安装Python包,使用以下代码:
python3 -m pip install --upgrade pip pip install optax==0.2.2 flax==0.8.2 transformers==4.38.2 tiktoken==0.6.0 datasets==2.17.1 pip install git+https://github.com/deepmind/jmp pip install numpy==1.26.4
-
克隆GitHub仓库。`nanoGPT-JAX`文件夹包含用于全精度训练模型的JAX代码。详细的创建JAX实现的nanoGPT模型的说明可以参见在AMD GPU上使用JAX实现和训练生成预训练转换器(GPT)的指南。
git clone https://github.com/ROCm/rocm-blogs.git cd rocm-blogs/blogs/artificial-intelligence/nanoGPT-JAX
-
用当前博客对应的*
src*文件夹中的文件替换`nanoGPT-JAX`文件夹中的`model.py`和`train.py`脚本。这些文件包含了混合精度训练的改动。你还需要下载`utils.py`文件并将其放在`nanoGPT-JAX`文件夹中。为了可视化我们对原始`model.py`和`train.py`文件所做的所有改动,我们建议使用代码差异可视化工具,如W3docs的在线代码差异工具)来对比原始版本和当前版本。
确保所有后续操作都在`nanoGPT-JAX`文件夹内进行。
代码更改说明
在本节中,我们将带您了解启用混合精度训练的主要代码更改。
以下代码块来自 jax-mixed-precision/src/train.py 文件,定义了每种类型操作使用的精度策略。该策略指示训练管道转换数据格式以实现混合精度训练的好处。
policy = Policy(
param_dtype=jnp.float32,
compute_dtype=jmp.half_dtype() if amp else jnp.float32,
output_dtype=jmp.half_dtype() if amp else jnp.float32,
reduce_ops_dtype=jnp.float32,
)
下一个代码块将 FP32 参数转换为 FP16,然后使用 gradient_fn 函数以 FP16 生成损失和梯度(带有缩放)。随后将梯度转换为 FP32 并取消缩放。如果所有梯度值都是有限的,则更新原始 FP32 参数。如果它们不是有限的,则调整缩放比例并开始下一次迭代。
# 将参数转换为 fp16
params = policy.cast_to_compute(state.params)
# 在 fp16 中获得缩放后的损失和梯度
loss, grads = gradient_fn(params, x, targets=y, rng=key0, train=True, loss_scale=loss_scale, policy=policy)
# 取消缩放损失
loss = loss_scale.unscale(loss)
# 将梯度转换为 fp32
grads = policy.cast_to_param(grads)
# 取消缩放梯度
grads = loss_scale.unscale(grads)
if skip_infinite:
#检查所有梯度值是否有限;如果一个梯度值在 fp16 中溢出(即 inf),在转换为 fp32 后它仍然会是 inf
grads_finite = jmp.all_finite(grads)
# 根据梯度是否有限来调整我们的损失缩放。如果梯度保持有限,损失缩放会定期增加;反之,则减少。
loss_scale = loss_scale.adjust(grads_finite)
# 只有在梯度有限时才应用优化;如果任何一个梯度的任何元素是非有限的,则整个更新将被丢弃。
state = jmp.select_tree(
grads_finite, state.apply_gradients(grads=grads), state
)
else:
# 使用静态或无损失缩放时,仅应用我们的优化器。
state = state.apply_gradients(grads=grads)
以下代码块来自 jax-mixed-precision/src/model.py 文件,计算 FP32 中的损失,将其缩放,然后将其转换回低精度(FP16)以进行反向传播。这就是 gradient_fn 如何在 FP16 中生成损失和缩放梯度:
# 将 logits 转换为 fp32 以获得 fp32 中的损失
loss = optax.softmax_cross_entropy_with_integer_labels(policy.cast_to_reduce_ops(logits), targets).mean()
if not train:
return logits, loss
# 缩放损失
loss = loss_scale.scale(loss)
# 将缩放后的损失转换为 fp16
loss = policy.cast_to_output(loss)
这些代码更改使 nanoGPT 在 JAX 中实现混合精度训练,从而优化 GPU 资源的使用并加快训练过程。
预训练nanoGPT模型
在本节中,我们将演示如何使用混合精度和全精度预训练一个nanoGPT模型。有关JAX nanoGPT模型的更多详细信息,请参阅在AMD GPU上实现和训练生成预训练变换器(GPT)指南。
要启动混合精度训练,请运行以下命令:
# 预处理字符级别的莎士比亚数据集 python data/shakespeare_char/prepare.py # 开始预训练 # 提供的配置文件设置了在AMD GPU上使用JAX训练一个小型字符级GPT模型。它指定了模型架构参数、训练设置、评估间隔、日志偏好、数据处理和检查点详细信息,确保了一个全面但灵活的实验和调试模型的设置。 python train.py config/train_shakespeare_char.py --amp=True
在训练过程中,输出将类似于以下部分输出:
...
Overriding: amp = True
found vocab_size = 65 (from data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
Data is on device: {rocm(id=0)}
Evaluating at iter_num == 0...
step 0: train loss 4.3772, val loss 4.3917; best val loss to now: 4.3917
iter 0: loss 4.4146, time 44309.10ms
iter 10: loss 3.4914, time 51.32ms
iter 20: loss 3.2811, time 52.18ms
iter 30: loss 3.0276, time 56.57ms
iter 40: loss 2.8481, time 55.09ms
iter 50: loss 2.6980, time 56.30ms
iter 60: loss 2.6223, time 53.13ms
iter 70: loss 2.6218, time 57.47ms
iter 80: loss 2.5859, time 51.95ms
iter 90: loss 2.5762, time 57.52ms
iter 100: loss 2.5696, time 55.93ms
...
在训练过程中,输出将类似于以下部分输出:
python train.py config/train_shakespeare_char.py --amp=False
全精度训练的输出将类似于以下部分输出:
...
Overriding: amp = False
found vocab_size = 65 (from data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
Data is on device: {rocm(id=0)}
Evaluating at iter_num == 0...
step 0: train loss 4.3818, val loss 4.3924; best val loss to now: 4.3924
iter 0: loss 4.4176, time 48566.02ms
iter 10: loss 3.4745, time 82.93ms
iter 20: loss 3.3307, time 83.27ms
iter 30: loss 3.0622, time 85.82ms
iter 40: loss 2.8195, time 82.55ms
iter 50: loss 2.6754, time 83.40ms
iter 60: loss 2.6421, time 83.90ms
iter 70: loss 2.6119, time 83.47ms
iter 80: loss 2.5826, time 84.24ms
iter 90: loss 2.5601, time 83.56ms
...
根据输出结果,混合精度训练相比全精度训练实现了每次迭代训练速度的大约35%提升(混合精度为约54毫秒(ms),全精度为约83毫秒(ms))。此初始迭代不包括长时间的编译时间。这些时间是示例性的,可能会根据Python包版本、GPU类型、批处理大小、优化器设置和系统配置等因素有所变化。
此外,通过观察损失曲线,混合精度和全精度训练在训练集和验证集上表现相似。这表明混合精度训练在加速训练速度的同时保持了模型性能。
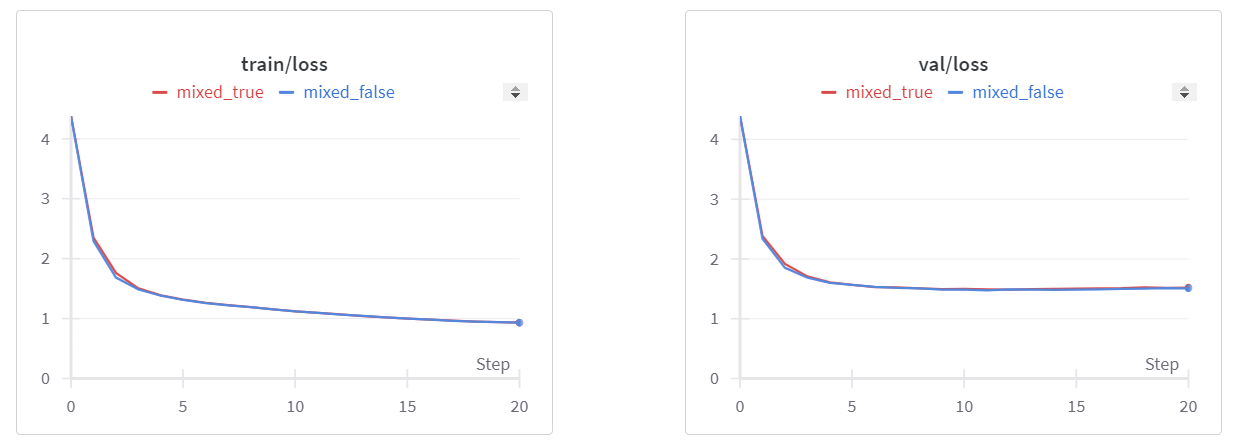
最后,我们鼓励您进一步探索使用BF16和FP8等其他低精度格式进行混合精度训练,比较其各自的性能优势。对于那些对混合精度感兴趣的人,请查看我们其他关于ROCm混合精度的博客,例如自动混合精度和AMP下的RoBERTa。
总结
在这篇博客中,我们进一步探讨了前面讨论的nanoGPT模型(详见在AMD GPU上使用JAX实现和训练生成型预训练变换器(GPT)的指南),提供了一个关于如何集成混合精度训练的指南,以实现基于ROCm和AMD GPU的JAX实现nanoGPT模型更快且更少内存消耗的实现。
致谢
我们要向Azzeddine Chenine表示感谢,他的flash-nanoGPT仓库为我们的工作提供了宝贵的参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











