






也是为了复现最原始的 Attention is all you need 实验过程;
1. cuda10.0
一, 安装cuda10.0 和 对应的 cudnn7.6.5
下载cuda 10.0 for ubuntu18.04
CUDA Toolkit 10.0 Download | NVIDIA Developer
安装cuda:
预备工作
创建blacklist***.conf具体如下,加入两行内容
sudo vim /etc/modprobe.d/blacklist-nouveau.conf
内容:
blacklist nouveau
options nouveau modeset=0
sudo update-initramfs -u
安装cuda 10.0:
1. 手动下载 cuda 10.0 for ubuntu18.04,并安装:
sudo apt-get install linux-headers-$(uname -r) \
&& sudo apt-key del 7fa2af80 \
&& sudo dpkg -i cuda-repo-ubuntu1804-10-0-local-10.0.130-410.48_1.0-1_amd64.deb \
&& sudo apt-key add /var/cuda-repo-10-0-local-10.0.130-410.48/7fa2af80.pub \
&& sudo apt-get update \
&& sudo apt-get -y install cuda
注册nvidia开发者,并下载对应 ***cudnn***.deb,安装命令:
#注意安装顺序:
sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.0_amd64.deb && \
sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.0_amd64.deb && \
sudo dpkg -i libcudnn7-doc_7.6.5.32-1+cuda10.0_amd64.deb
二,安装python3 环境
预先安装合适版本的python3 module:
sudo apt install python3.7*
sudo rm /usr/bin/python3
sudo ln /usr/bin/python3.7 /usr/bin/python3
sudo apt install python3-pip
sudo pip3 install ipython
sudo pip3 install Cython
sudo apt-get install -y glibc-doc manpages-posix-dev
sudo pip3 install numpy==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
sudo pip3 install pkgconfig==1.4.0
cd /usr/lib/python3/dist-packages
sudo ln -s apt_pkg.cpython-36m-x86_64-linux-gnu.so apt_pkg.so
# install HDF5:具体方法在文末
sudo pip3 install h5py==2.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
sudo pip3 install setuptools==57.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
三,安装tensorflow 1.14.0
sudo pip3 install tensorflow-gpu==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
四,下载,编译,安装hdf5
sudo apt-get update
sudo apt-get install build-essential
sudo apt-get build-dep hdf5
mkdir ~/Software
cd ~/Software
wget https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.10/hdf5-1.10.10/src/hdf5-1.10.10.tar.gz
tar -xf hdf5-1.8.10.tar.gz
cd hdf5-1.8.10/
./configure
make -j9
sudo make install五,测试tensorflow的安装效果
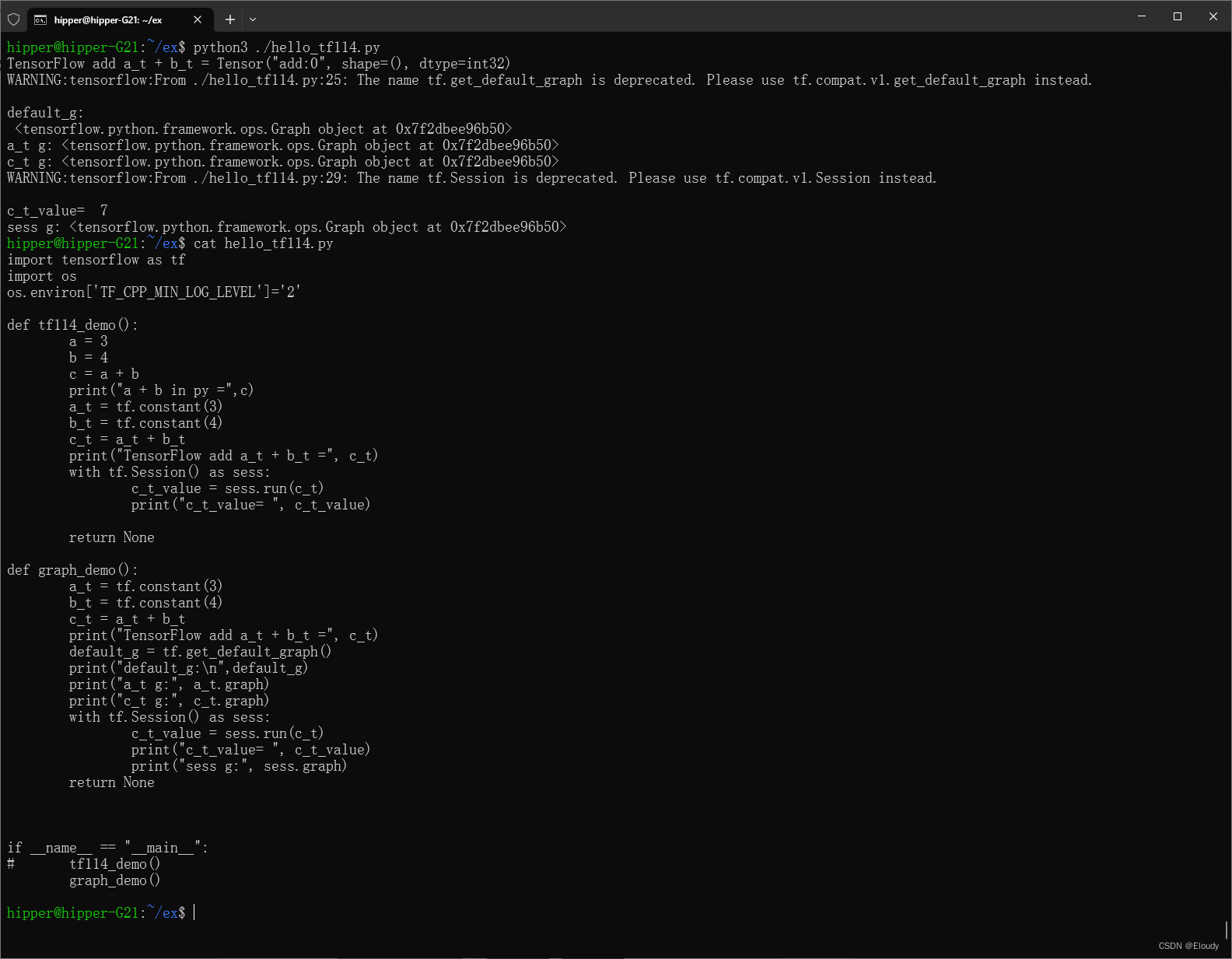
demo 测试源码 hello_tf114.py
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def tf114_demo():
a = 3
b = 4
c = a + b
print("a + b in py =",c)
a_t = tf.constant(3)
b_t = tf.constant(4)
c_t = a_t + b_t
print("TensorFlow add a_t + b_t =", c_t)
with tf.Session() as sess:
c_t_value = sess.run(c_t)
print("c_t_value= ", c_t_value)
return None
if __name__ == "__main__":
tf114_demo()运行结果:
2. cuda10.2 + rtx2080ti
一,尝试使用cuda10.2来支持tensorflow1.14.0
rtx 2080ti 是2018年5月发布,cuda 10.2 首版是2019年发布的,故可以推断,cuda 10.2也支持2080ti,并可以在 2080ti上 运行 tensorflow 1.14.0;待更深入的网络训练的测试
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
实测发现,在ubuntu18.04中,使用cuda10.2并不能直接支持tensorflow 1.14.0,因为tensorflow 1.14.0会默认 load cuda相关lib的10.0版本,例如 libcudart.so.10.0 libcublas.so.10.0 等;
如果安装cuda10.2后不做任何改动,将出现如下错误:

所以,要尝试用10.2的so充当 10.0 的 so文件:
cd /usr/lib/x86_64-linux-gnu \
&& sudo ln -s libcublas.so.10.2.2.89 libcublas.so.10.0 \
&& sudo ln -s libcublasLt.so.10.2.2.89 libcublasLt.so.10.0
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.2/targets/x86_64-linux/lib/
cd /usr/local/cuda-10.2/targets/x86_64-linux/lib/ \
&& sudo ln -s libcufft.so.10.1.2.89 libcufft.so.10.0 \
&& sudo ln -s libcufftw.so.10.1.2.89 libcufftw.so.10.0 \
&& sudo ln -s libcurand.so.10.1.2.89 libcurand.so.10.0 \
&& sudo ln -s libcusolverMg.so.10.3.0.89 libcusolverMg.so.10.0 \
&& sudo ln -s libcusolver.so.10.3.0.89 libcusolver.so.10.0 \
&& sudo ln -s libcusparse.so.10.3.1.89 libcusparse.so.10.0 \
&& sudo ln -s libnppc.so.10.2.1.89 libnppc.so.10.0 \
&& sudo ln -s libnppial.so.10.2.1.89 libnppial.so.10.0 \
&& sudo ln -s libnppicc.so.10.2.1.89 libnppicc.so.10.0 \
&& sudo ln -s libnppicom.so.10.2.1.89 libnppicom.so.10.0 \
&& sudo ln -s libnppidei.so.10.2.1.89 libnppidei.so.10.0 \
&& sudo ln -s libnppif.so.10.2.1.89 libnppif.so.10.0 \
&& sudo ln -s libnppig.so.10.2.1.89 libnppig.so.10.0 \
&& sudo ln -s libnppim.so.10.2.1.89 libnppim.so.10.0 \
&& sudo ln -s libnppist.so.10.2.1.89 libnppist.so.10.0 \
&& sudo ln -s libnppisu.so.10.2.1.89 libnppisu.so.10.0 \
&& sudo ln -s libnppitc.so.10.2.1.89 libnppitc.so.10.0 \
&& sudo ln -s libnpps.so.10.2.1.89 libnpps.so.10.0 \
&& sudo ln -s libnvgraph.so.10.2.89 libnvgraph.so.10.0 \
&& sudo ln -s libnvjpeg.so.10.3.1.89 libnvjpeg.so.10.0 \
&& sudo ln -s libcudart.so.10.2.89 libcudart.so.10.0 \
&& sudo ln -s libaccinj64.so.10.2.89 libaccinj64.so.10.0 \
&& sudo ln -s libcuinj64.so.10.2.89 libcuinj64.so.10.0 \
&& sudo ln -s libcupti.so.10.2.75 libcupti.so.10.0 \
&& sudo ln -s libnvrtc-builtins.so.10.2.89 libnvrtc-builtins.so.10.0 \
&& sudo ln -s libnvrtc.so.10.2.89 libnvrtc.so.10.0
#别忘了这个:
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/targets/x86_64-linux/lib/export LD_LIBRARY_PATH=/usr/local/cuda-10.2/targets/x86_64-linux/lib/
浅测可以:

cuda10.0 应该是调用不动2080TI卡,因为发布时间的先后;而 cuda10.2发布的时间晚于2080ti的发布时间,所以是可以支持到的;
二,深入的测试 demo_01
bidirectional_rnn.py
""" Bi-directional Recurrent Neural Network.
A Bi-directional Recurrent Neural Network (LSTM) implementation example using
TensorFlow library. This example is using the MNIST database of handwritten
digits (http://yann.lecun.com/exdb/mnist/)
Links:
[Long Short Term Memory](http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf)
[MNIST Dataset](http://yann.lecun.com/exdb/mnist/).
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
"""
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
import numpy as np
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
'''
To classify images using a bidirectional recurrent neural network, we consider
every image row as a sequence of pixels. Because MNIST image shape is 28*28px,
we will then handle 28 sequences of 28 steps for every sample.
'''
# Training Parameters
learning_rate = 0.001
training_steps = 10000
batch_size = 128
display_step = 200
# Network Parameters
num_input = 28 # MNIST data input (img shape: 28*28)
timesteps = 28 # timesteps
num_hidden = 128 # hidden layer num of features
num_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
X = tf.placeholder("float", [None, timesteps, num_input])
Y = tf.placeholder("float", [None, num_classes])
# Define weights
weights = {
# Hidden layer weights => 2*n_hidden because of forward + backward cells
'out': tf.Variable(tf.random_normal([2*num_hidden, num_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([num_classes]))
}
def BiRNN(x, weights, biases):
# Prepare data shape to match `rnn` function requirements
# Current data input shape: (batch_size, timesteps, n_input)
# Required shape: 'timesteps' tensors list of shape (batch_size, num_input)
# Unstack to get a list of 'timesteps' tensors of shape (batch_size, num_input)
x = tf.unstack(x, timesteps, 1)
# Define lstm cells with tensorflow
# Forward direction cell
lstm_fw_cell = rnn.BasicLSTMCell(num_hidden, forget_bias=1.0)
# Backward direction cell
lstm_bw_cell = rnn.BasicLSTMCell(num_hidden, forget_bias=1.0)
# Get lstm cell output
try:
outputs, _, _ = rnn.static_bidirectional_rnn(lstm_fw_cell, lstm_bw_cell, x,
dtype=tf.float32)
except Exception: # Old TensorFlow version only returns outputs not states
outputs = rnn.static_bidirectional_rnn(lstm_fw_cell, lstm_bw_cell, x,
dtype=tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
logits = BiRNN(X, weights, biases)
prediction = tf.nn.softmax(logits)
# Define loss and optimizer
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model (with test logits, for dropout to be disabled)
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, training_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
batch_x = batch_x.reshape((batch_size, timesteps, num_input))
# Run optimization op (backprop)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
loss, acc = sess.run([loss_op, accuracy], feed_dict={X: batch_x,
Y: batch_y})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
# Calculate accuracy for 128 mnist test images
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, timesteps, num_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
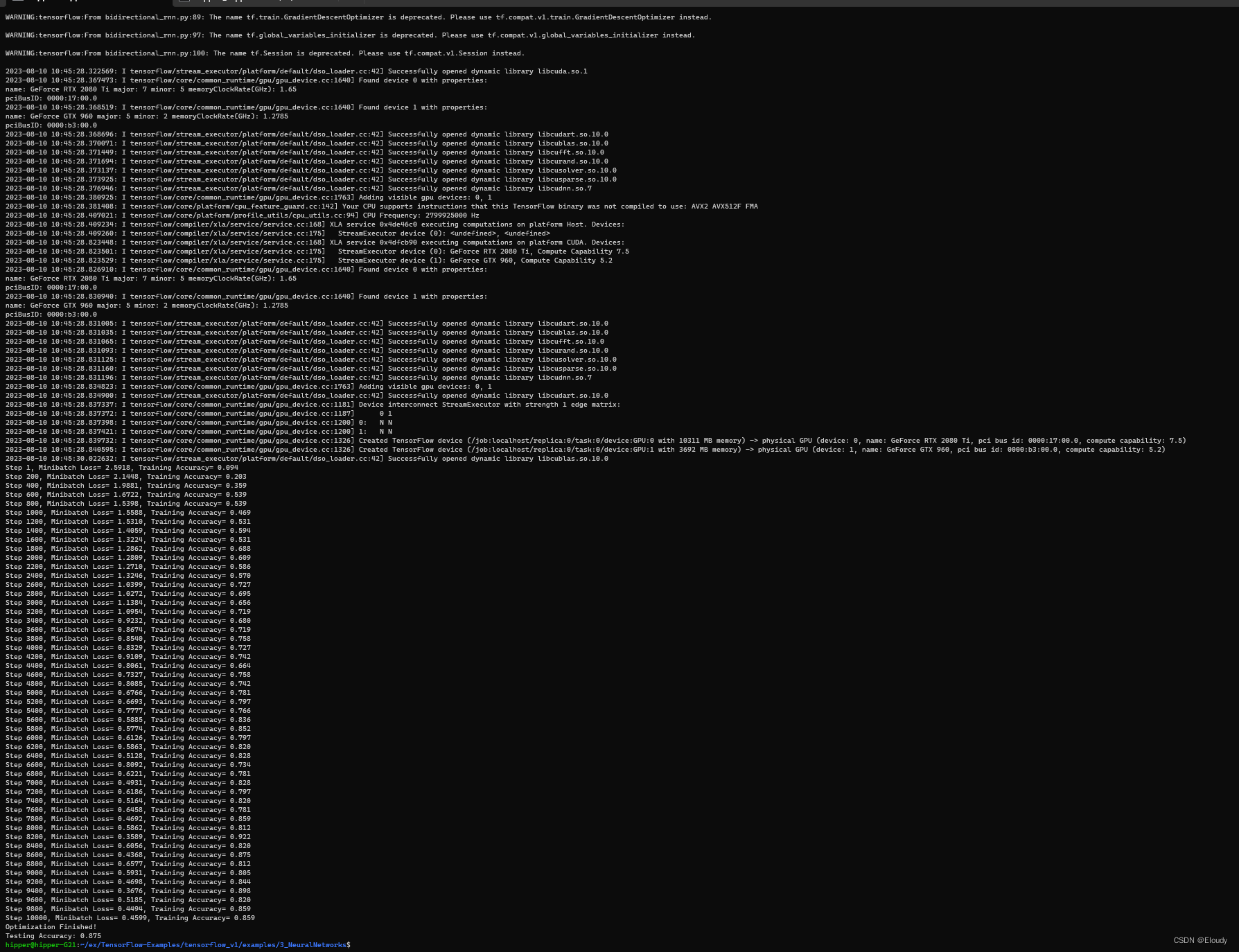
sess.run(accuracy, feed_dict={X: test_data, Y: test_label}))$ python3 bidirectional_rnn.py
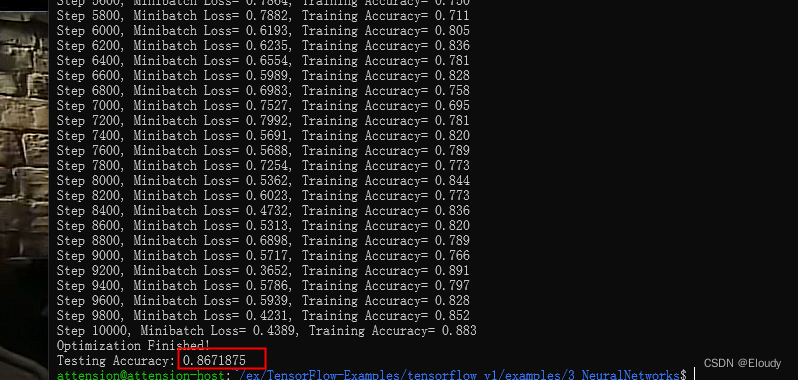
训练效果:
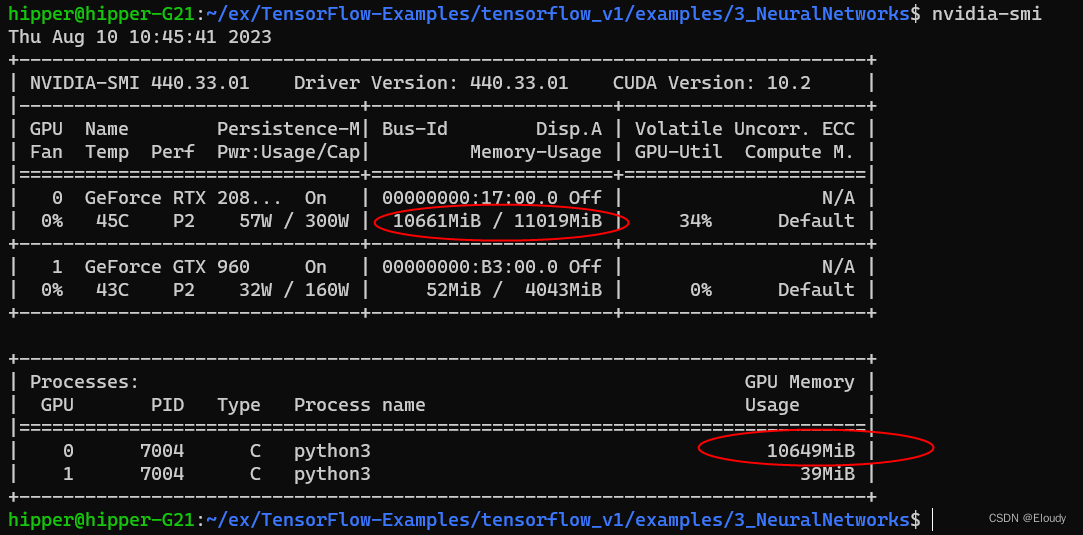
nvidia-smi gpu 使用效果:
三,深入的测试 demo_02
convolutional_network_raw_deviceInfo.py
""" Convolutional Neural Network.
Build and train a convolutional neural network with TensorFlow.
This example is using the MNIST database of handwritten digits
(http://yann.lecun.com/exdb/mnist/)
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
"""
from __future__ import division, print_function, absolute_import
import tensorflow as tf
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# Training Parameters
learning_rate = 0.001
num_steps = 200
batch_size = 128
display_step = 10
# Network Parameters
num_input = 784 # MNIST data input (img shape: 28*28)
num_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units
# tf Graph input
X = tf.placeholder(tf.float32, [None, num_input])
Y = tf.placeholder(tf.float32, [None, num_classes])
keep_prob = tf.placeholder(tf.float32) # dropout (keep probability)
# Create some wrappers for simplicity
def conv2d(x, W, b, strides=1):
# Conv2D wrapper, with bias and relu activation
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def maxpool2d(x, k=2):
# MaxPool2D wrapper
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME')
# Create model
def conv_net(x, weights, biases, dropout):
# MNIST data input is a 1-D vector of 784 features (28*28 pixels)
# Reshape to match picture format [Height x Width x Channel]
# Tensor input become 4-D: [Batch Size, Height, Width, Channel]
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# Convolution Layer
conv1 = conv2d(x, weights['wc1'], biases['bc1'])
# Max Pooling (down-sampling)
conv1 = maxpool2d(conv1, k=2)
# Convolution Layer
conv2 = conv2d(conv1, weights['wc2'], biases['bc2'])
# Max Pooling (down-sampling)
conv2 = maxpool2d(conv2, k=2)
# Fully connected layer
# Reshape conv2 output to fit fully connected layer input
fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
# Apply Dropout
fc1 = tf.nn.dropout(fc1, dropout)
# Output, class prediction
out = tf.add(tf.matmul(fc1, weights['out']), biases['out'])
return out
# Store layers weight & bias
weights = {
# 5x5 conv, 1 input, 32 outputs
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
# 5x5 conv, 32 inputs, 64 outputs
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
# fully connected, 7*7*64 inputs, 1024 outputs
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
# 1024 inputs, 10 outputs (class prediction)
'out': tf.Variable(tf.random_normal([1024, num_classes]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([num_classes]))
}
# Construct model
logits = conv_net(X, weights, biases, keep_prob)
prediction = tf.nn.softmax(logits)
# Define loss and optimizer
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
# Run the initializer
sess.run(init)
for step in range(1, num_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.8})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
loss, acc = sess.run([loss_op, accuracy], feed_dict={X: batch_x,
Y: batch_y,
keep_prob: 1.0})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
# Calculate accuracy for 256 MNIST test images
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: mnist.test.images[:256],
Y: mnist.test.labels[:256],
keep_prob: 1.0}))$ python3 convolutional_network_raw_deviceInfo.py
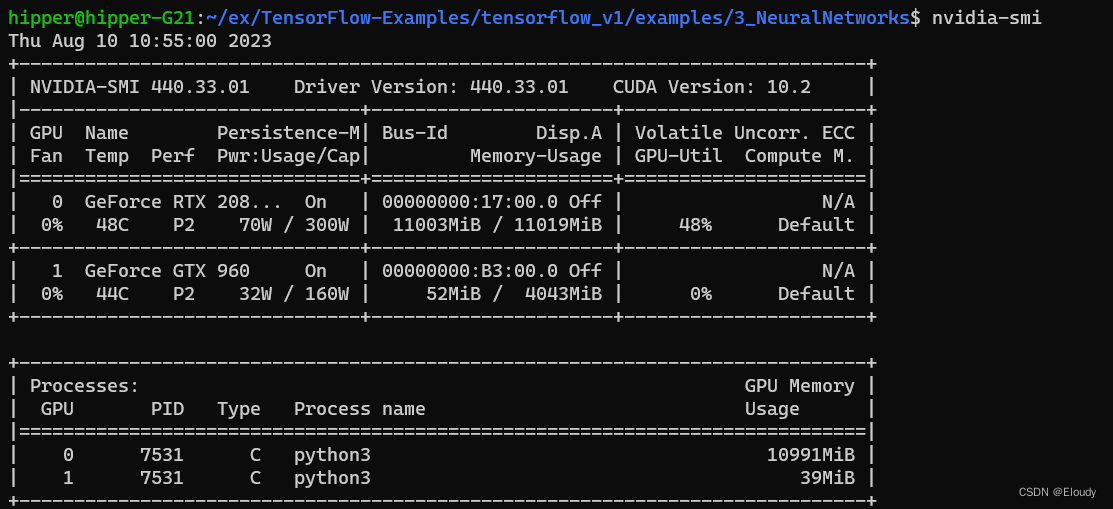
训练效果:

$nvidia-smi
————————————————————————————————————————
sudo apt install python3-pip \
&& sudo pip3 install Cython \
&& sudo pip3 install ipython \
&& sudo apt-get install -y glibc-doc manpages-posix-dev \
&& sudo pip3 install numpy==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/ \
&& sudo pip3 install pkgconfig==1.4.0 \
&& cd /usr/lib/python3/dist-packages \
&& sudo ln -s apt_pkg.cpython-36m-x86_64-linux-gnu.so apt_pkg.so
sudo apt-get update \
&& sudo apt-get install build-essential \
&& sudo apt-get build-dep hdf5 \
&& mkdir ~/Software \
&& cd ~/Software \
&& wget https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.10/hdf5-1.10.10/src/hdf5-1.10.10.tar.gz \
&& tar -xf hdf5-1.10.10.tar.gz \
&& cd hdf5-1.10.10/ \
&& ./configure \
&& make -j9 \
&& sudo make install
sudo pip3 install h5py==2.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/ \
&& sudo pip3 install setuptools==57.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
cd /usr/lib/x86_64-linux-gnu \
&& sudo ln -s libcublas.so.10.2.2.89 libcublas.so.10.0 \
&& sudo ln -s libcublasLt.so.10.2.2.89 libcublasLt.so.10.0
cd /usr/local/cuda-10.2/targets/x86_64-linux/lib/ \
&& sudo ln -s libcufft.so.10.1.2.89 libcufft.so.10.0 \
&& sudo ln -s libcufftw.so.10.1.2.89 libcufftw.so.10.0 \
&& sudo ln -s libcurand.so.10.1.2.89 libcurand.so.10.0 \
&& sudo ln -s libcusolverMg.so.10.3.0.89 libcusolverMg.so.10.0 \
&& sudo ln -s libcusolver.so.10.3.0.89 libcusolver.so.10.0 \
&& sudo ln -s libcusparse.so.10.3.1.89 libcusparse.so.10.0 \
&& sudo ln -s libnppc.so.10.2.1.89 libnppc.so.10.0 \
&& sudo ln -s libnppial.so.10.2.1.89 libnppial.so.10.0 \
&& sudo ln -s libnppicc.so.10.2.1.89 libnppicc.so.10.0 \
&& sudo ln -s libnppicom.so.10.2.1.89 libnppicom.so.10.0 \
&& sudo ln -s libnppidei.so.10.2.1.89 libnppidei.so.10.0 \
&& sudo ln -s libnppif.so.10.2.1.89 libnppif.so.10.0 \
&& sudo ln -s libnppig.so.10.2.1.89 libnppig.so.10.0 \
&& sudo ln -s libnppim.so.10.2.1.89 libnppim.so.10.0 \
&& sudo ln -s libnppist.so.10.2.1.89 libnppist.so.10.0 \
&& sudo ln -s libnppisu.so.10.2.1.89 libnppisu.so.10.0 \
&& sudo ln -s libnppitc.so.10.2.1.89 libnppitc.so.10.0 \
&& sudo ln -s libnpps.so.10.2.1.89 libnpps.so.10.0 \
&& sudo ln -s libnvgraph.so.10.2.89 libnvgraph.so.10.0 \
&& sudo ln -s libnvjpeg.so.10.3.1.89 libnvjpeg.so.10.0 \
&& sudo ln -s libcudart.so.10.2.89 libcudart.so.10.0 \
&& sudo ln -s libaccinj64.so.10.2.89 libaccinj64.so.10.0 \
&& sudo ln -s libcuinj64.so.10.2.89 libcuinj64.so.10.0 \
&& sudo ln -s libcupti.so.10.2.75 libcupti.so.10.0 \
&& sudo ln -s libnvrtc-builtins.so.10.2.89 libnvrtc-builtins.so.10.0 \
&& sudo ln -s libnvrtc.so.10.2.89 libnvrtc.so.10.0
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.2/targets/x86_64-linux/lib/测试Quadro P600 4GB显卡也可以, cuda 10.2 + cudnn 7.6.5 + tensorflow 1.14.0
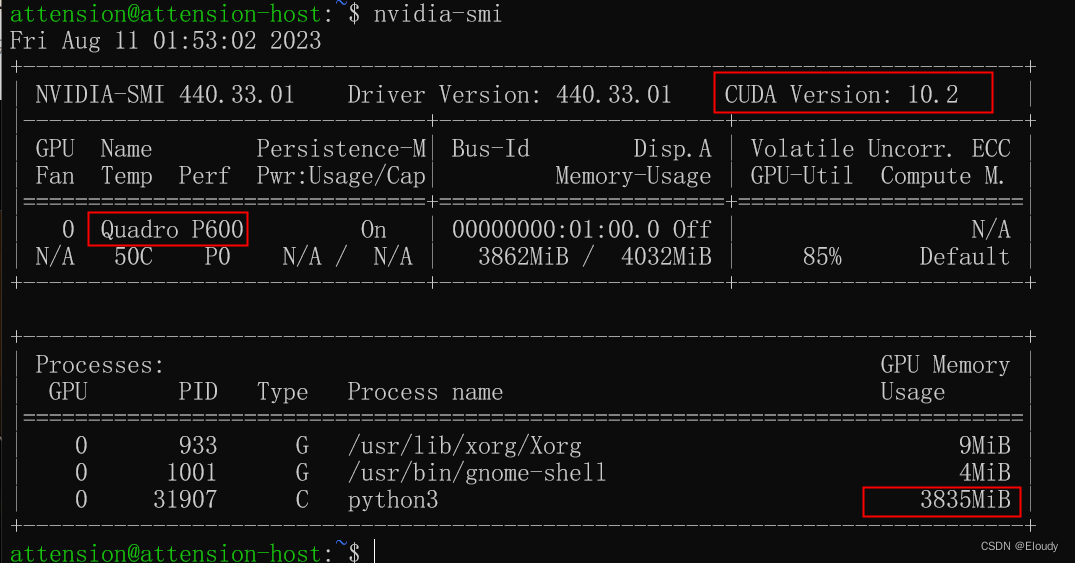
成功训练:















 9077
9077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









