







 LoRA是一种低秩自适应方法,通过在Transformer架构中引入可训练的低秩矩阵分解,减少预训练模型的下游任务参数数量,提高训练效率,同时保持模型性能。这种方法不会增加推理延迟,且在GPT-3和GPT-2等大模型上表现与微调相当或更好。
LoRA是一种低秩自适应方法,通过在Transformer架构中引入可训练的低秩矩阵分解,减少预训练模型的下游任务参数数量,提高训练效率,同时保持模型性能。这种方法不会增加推理延迟,且在GPT-3和GPT-2等大模型上表现与微调相当或更好。
-
低秩自适应(LoRA),它将预训练模型权重冻结,并将可训练的秩分解矩阵注入Transformer架构的每一层,大大减少了下游任务的可训练参数数量。具体来说,它将原始矩阵分解为两个矩阵的乘积,其中一个矩阵的秩比另一个矩阵的秩低。这时只需要运用低秩矩阵来进行运算,这样,可以减少模型参数数量,提高训练吞吐量,并且在模型质量上表现出色,且不会增加推理延迟。
-
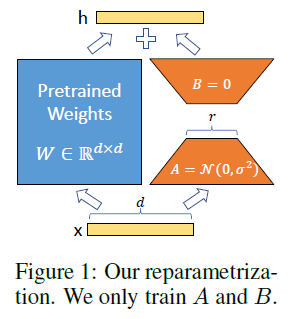
LoRA的思想也很简单,在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
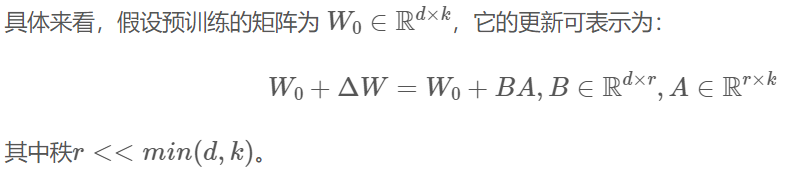
-
这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full finetuning的过程。并且,full finetuning可以被看做是LoRA的特例(当r等于k时):
This means that when applying LoRA to all weight matrices and training all biases, we roughly recover the expressiveness of full fine-tuning by setting the LoRA rank r to the rank of the pre-trained weight matrices.
In other words, as we increase the number of trainable parameters, training LoRA roughly converges to training the original model, while adapter-based methods converges to an MLP and prefix-based methods to a model that cannot take long input sequences.
-
LoRA也几乎未引入额外的inference latency,只需要计算
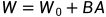 即可。
即可。
-
LoRA与Transformer的结合也很简单,仅在QKV attention的计算中增加一个旁路,而不动MLP模块:
We limit our study to only adapting the attention weights for downstream tasks and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity and parameter-efficiency.
-
为了获得更好的直觉,想象你有一个权重矩阵
W,它的维度为768 x 768。现在我们可以将矩阵分解为两个矩阵W_A和W_B,使得W_A (768 x r)和W_B (r x 768)。现在我们可以将我们的矩阵W定义为W = W_A @ W_B(其中@是矩阵乘法)。因此,最初W的可训练参数的数量是768 * 768 = 589824,而现在作为W_A和W_B的分解的W的可训练参数的总数变为768 × 8)+(8 × 768)= 12288,这是参数减少了97%。这里有一个伪代码来更好的理解这一点 -
import torch import torch.nn as nn # 定义神经网络的输入和输出维度 # 定义权重矩阵的大小 # 让假设权重矩阵的大小变成维度的W(768 X 768) # W中的参数总数为768*768=589824 input_dim = 768 output_dim = 768 W = ... # weight of my neural network # 等级‘r’用于低等级适配 # 可以将权重W表示为两个矩阵W_A和W_B的乘积,使得 # W(768 X 768)=W_A(768 X R)@(R X 768) # 现在的参数总数是(768×8)+(8×768)=12288 # 因此我们将W_A和W_B定义为r=8 rank = 8 W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA weight A W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA weight B # 加权为W的常规前向神经网络模型 def regular_forward_matmul(x, W): h = x @ W return h # LoRA前向神经网络 def lora_forward_matmul(x, W, W_A, W_B): # 常规矩阵乘法 # where W is NOT trainable (froozen weights) h = x @ W h += x @ (W_A @ W_B) * alpha # use scaled LoRA weights return h -
Hugging Face的PEFT库可以对LoRA进行调用,代码如下:
from peft import get_peft_model, LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 设置任务类型
inference_mode=False, # 设置推理模式为 False
r=8, # 设置 PEFT 模型的秩为 8
lora_alpha=32, # 设置 LORA 的 alpha 参数为 32
lora_dropout=0.1, # 设置 LORA 的 dropout 参数为 0.1
target_modules=['query_key_value'] # 设置 PEFT 模型的目标模块为 ['query_key_value']
)
# 加载模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
# 打印模型参数
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
# 然后就可以愉快地使用模型来训练了-
与完全微调相比,LoRA可以将GPT-3的可训练参数数量减少1万倍,计算硬件要求减少3倍。
-
LoRA在GPT-3和GPT-2上的模型质量表现与微调相当或更好,尽管可训练参数较少,训练吞吐量更高,推理延迟没有增加。
-
总结,基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的。它的应用自不必提,可以将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。
-
此外,考虑OpenAI对GPT模型的认知,GPT的本质是对训练数据的有效压缩,从而发现数据内部的逻辑与联系,LoRA的思想与之有相通之处,原模型虽大,但起核心作用的参数是低秩的,通过增加旁路,达到四两拨千斤的效果。
https://towardsdatascience.com/lora-intuitively-and-exhaustively-explained-e944a6bff46b

















 2056
2056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









