







本地部署 fish-speech
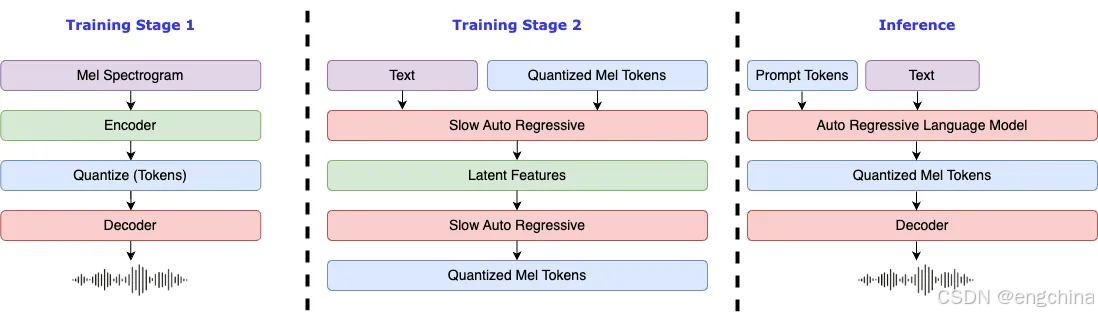
0. fish-speech 特性
- 零样本 & 小样本 TTS:输入 10 到 30 秒的声音样本即可生成高质量的 TTS 输出。详见 语音克隆最佳实践指南。
- 多语言 & 跨语言支持:只需复制并粘贴多语言文本到输入框中,无需担心语言问题。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
- 无音素依赖:模型具备强大的泛化能力,不依赖音素进行 TTS,能够处理任何文字表示的语言。
- 高准确率:在 5 分钟的英文文本上,达到了约 2% 的 CER(字符错误率)和 WER(词错误率)。
- 快速:通过 fish-tech 加速,在 Nvidia RTX 4060 笔记本上的实时因子约为 1:5,在 Nvidia RTX 4090 上约为 1:15。
- WebUI 推理:提供易于使用的基于 Gradio 的网页用户界面,兼容 Chrome、Firefox、Edge 等浏览器。
- GUI 推理:提供 PyQt6 图形界面,与 API 服务器无缝协作。支持 Linux、Windows 和 macOS。查看 GUI。
- 易于部署:轻松设置推理服务器,原生支持 Linux、Windows 和 macOS,最大程度减少速度损失。
1. 本地部署 fish-speech
克隆代码,
git clone https://github.com/fishaudio/fish-speech
修改 tools/download_models.py,将"gitattributes"改为".gitattributes"。(估计后期代码库会修复,如果代码库已修复,这步就不用做了。)
# "gitattributes"
".gitattributes"
下面是基于windows环境进行部署,进入到fish-speech目录,双击 install_env.bat安装虚拟环境。
2. 运行 fish-speech
下面是想使用 WebUI 界面进行推理,编辑项目根目录下的 API_FLAGS.txt, 前三行修改成如下格式:
--infer
# --api
# --listen ...
...
双击 start.bat 运行 fish-speech。第一次运行时,会从网上自动下载模型。
然后使用浏览器,打开 http://127.0.0.1:7860/进行访问。
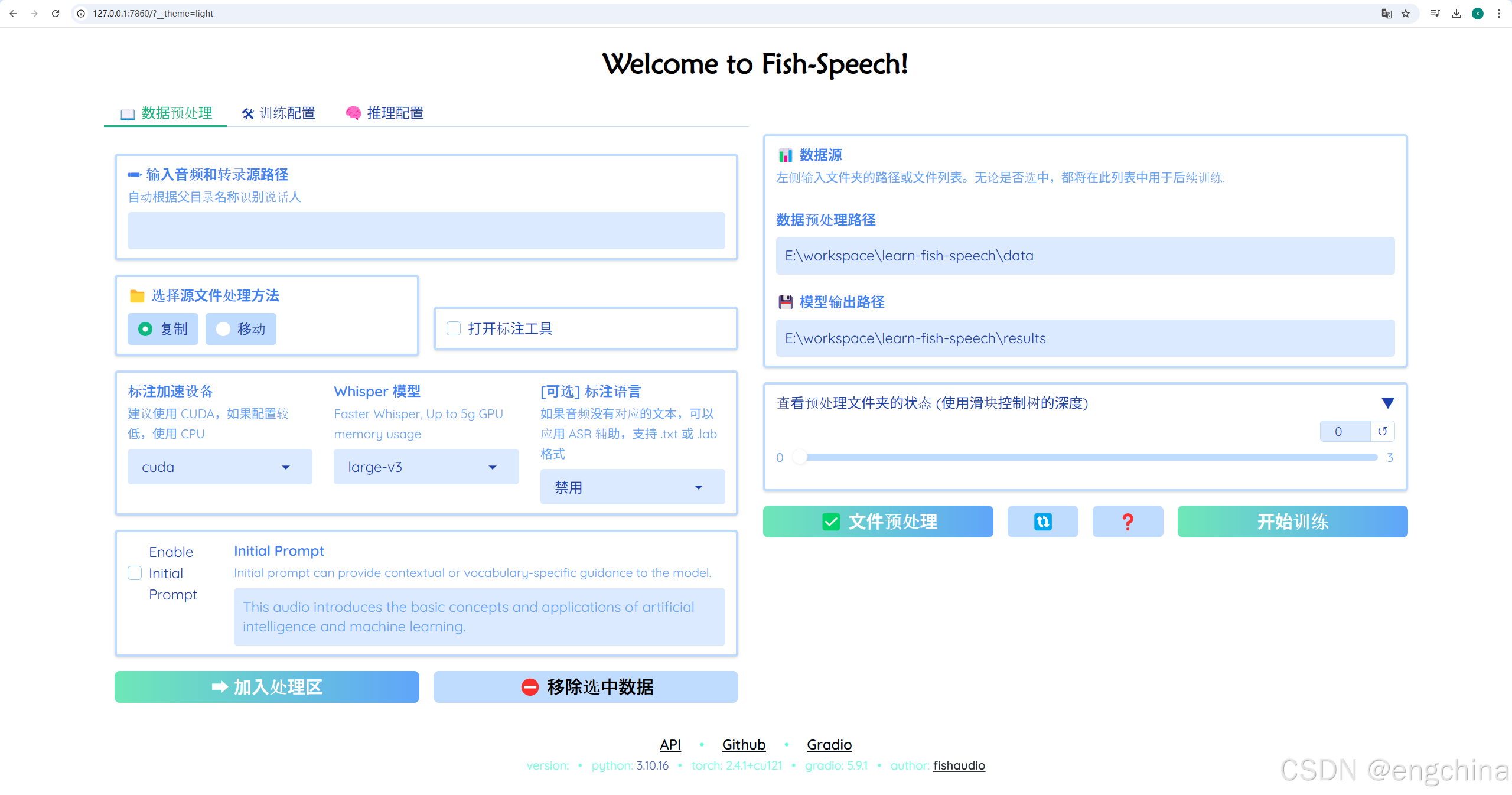
然后单击 “推理配置”,按照截图进行配置,
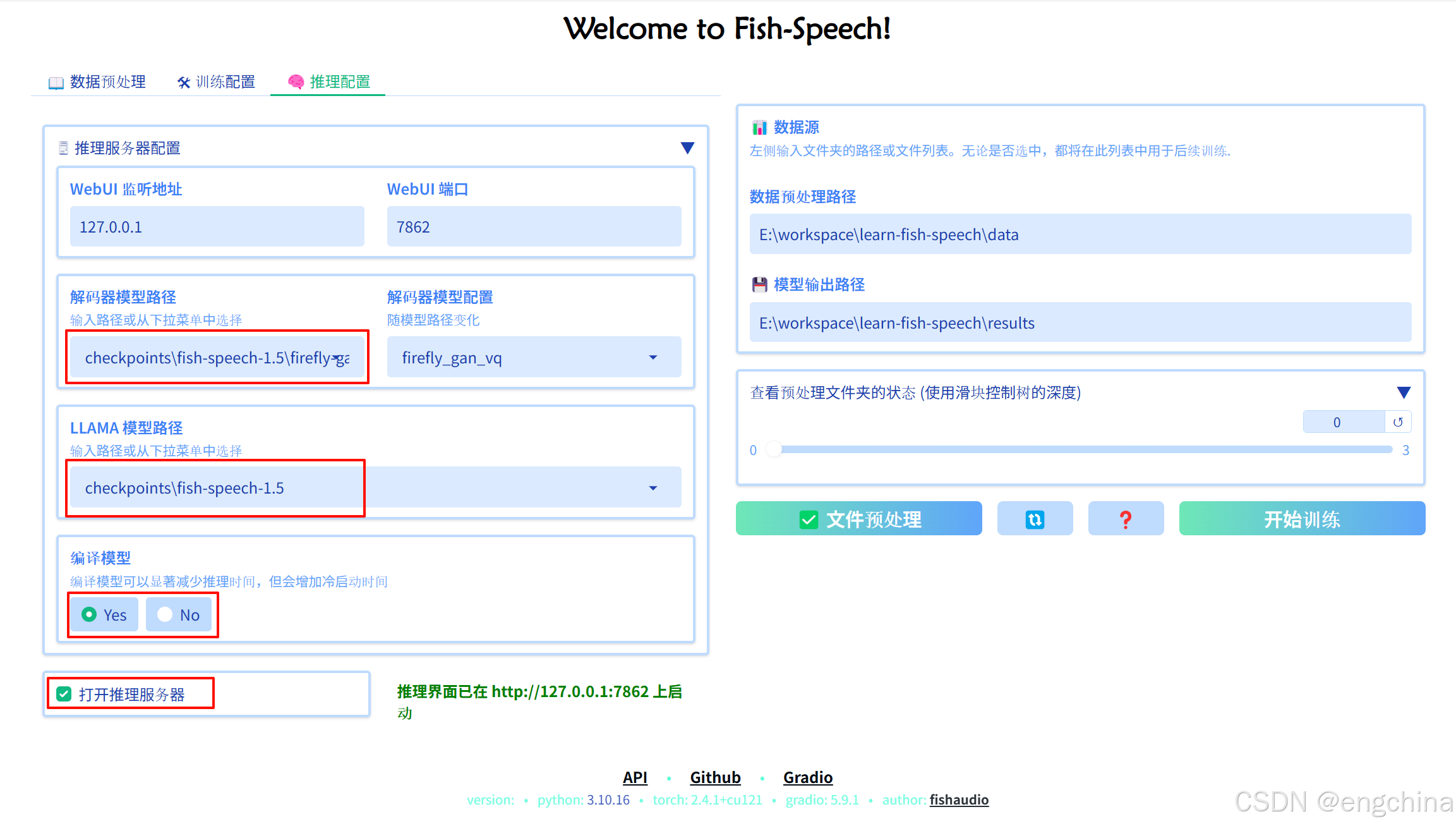
我本地环境,设置编译模型为"Yes"会报错,实际使用的时"No"这个选项。
然后使用浏览器,打开 http://127.0.0.1:7862/进行访问。
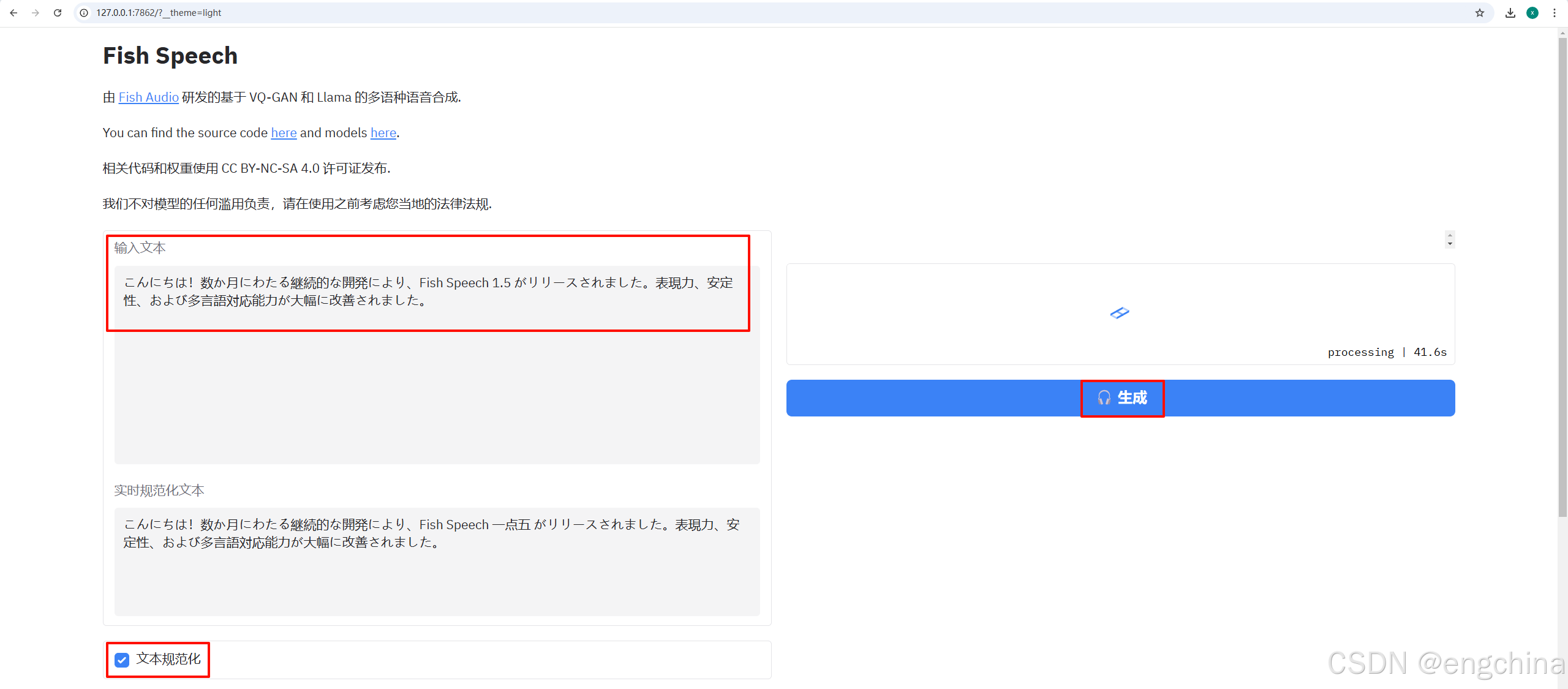
之后,输入要推理的文本,上传参考音频,单击 “生成” 就可以进行推理了。

参考资料:


















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









