1. 信息论基础(熵 联合熵 条件熵 信息增益 基尼不纯度) 联合熵:联合熵就是度量一个联合分布的随机系统的不确定度,下面给出两个随机变量的联合熵的定义: 信息增益:信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差(这里只的是经验熵或经验条件熵,由于真正的熵并不知道,是根据样本计算出来的),公式如下: 基尼不纯度:将来自集合中的某种结果随机应用于集合中某一数据项的预期误差率。 2.决策树 决策树生成的过程就是将数据集不断划分成为纯度更高,不确定更小的子集的过程。 ID3算法&#x










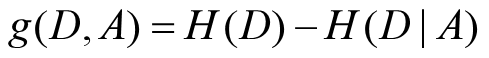
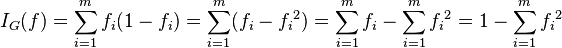
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1822
1822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






