







本博文内容主要是 :
- DStream与RDD关系彻底研究
Streaming中RDD的生成彻底研究
问题的提出 :
1、RDD是依靠谁产生的? 如何产生RDD?
2、执行时是否与Spark Core上的RDD执行有什么不同的
3、 运行之后对RDD要怎么处理
为什么有第三点 : 是因为Spark Streaming 中会随着相关触发条件,窗口Window滑动的时候都会不断的产生RDD ,从最基本的层次考虑,RDD也是基本对象,每秒会产生RDD ,内存能不能完全容纳,每个处理完成后怎么进行管理?
所以研究Spark Streaming的RDD,RDD产生的全生命周期,产生、运行、运行后的管理尤其重要。
一: DStream与RDD关系彻底研究
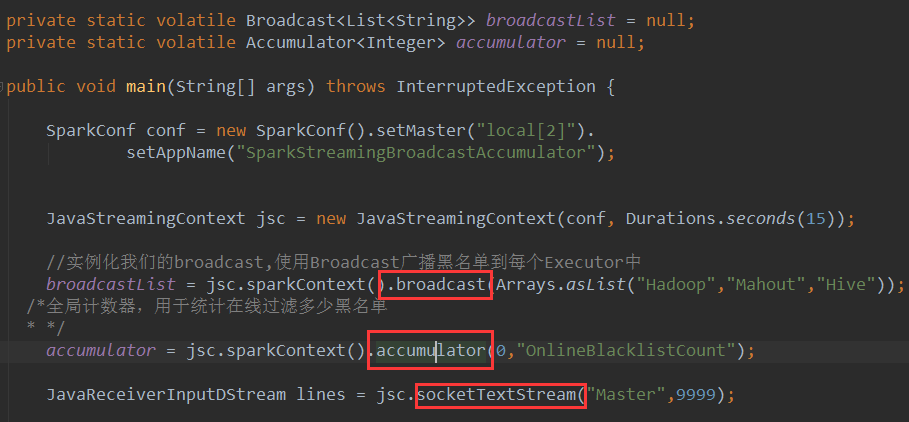
补充说明:广播和计数器并不像看上去简单,在实际的最佳实践中,通过广播和计数器可以实现非常复杂的算法(将更新的计数器数据转过来更新到数据库,HBase等)。
看代码逻辑,逻辑是一种想法,上述代码的socketTextStream,就可以想象数据的输入?数据处理?数据怎么来?
在获得数据后进行一系列的transformations、最后进行foreachRDD的操作。
1、直接用foreachRDD 在这里面直接定义了对action操作,可以直接写对RDD处理的操作函数,如图:
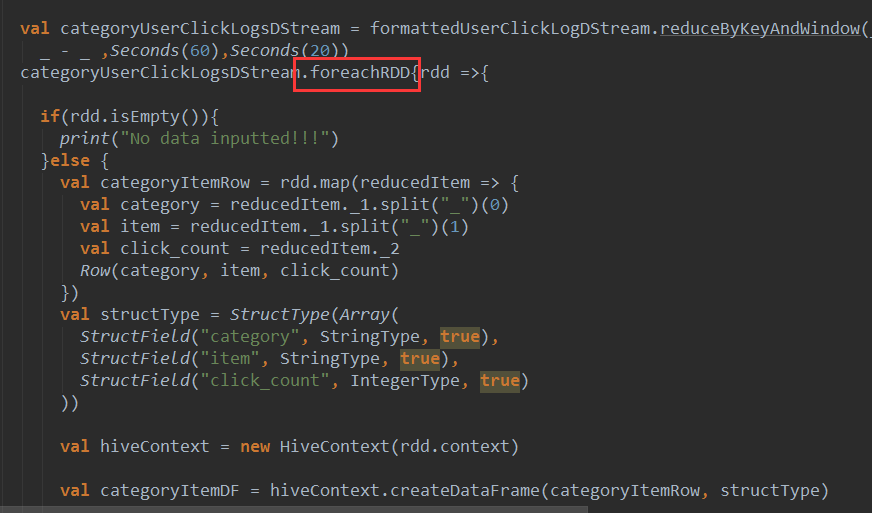
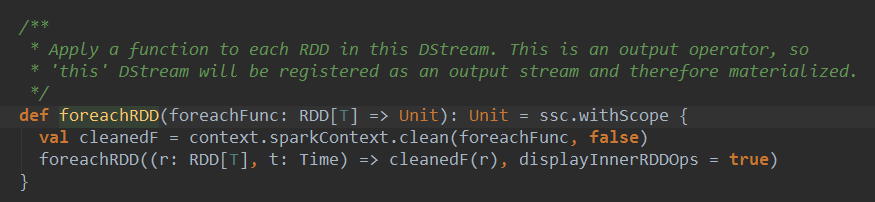
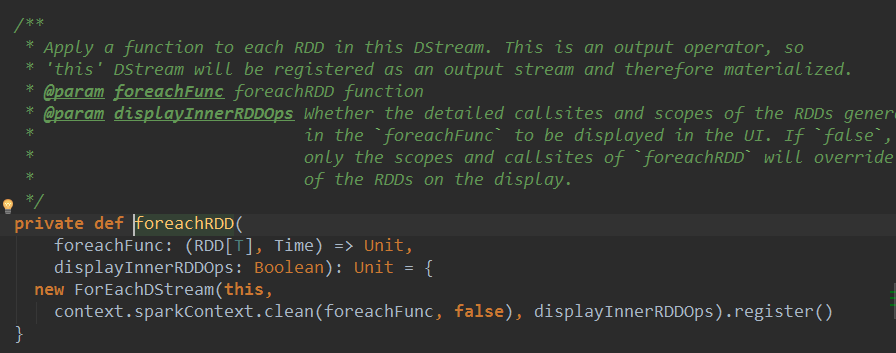
在RDD中操作action不会产生新的RDD,DStream和它完全对应,在DStream中操作action不会产生新的DStream。foreachDStream是transformation操作,在整个Spark Streaming的操作中,foreachDStream不一定会触发job的执行,但会触发Job的产生。
foreachRDD直接调用action不产生RDD,产生了DStream,说明foreachDStream是Transformation操作,得出**在整个SparkStreaming操作中,foreachRDD是Transformation级别的。**foreachDStream中封装的函数没有action不会触发作业,foreachDStream不一定会触发Job的执行,一定会触发Job的产生(Job产生由timer产生,根据业务逻辑代码产生,和foreachDStream没什么关系。)
2、从RDD的角度讲,操作DStream 的print函数,其实是转过来操作foreachDStream的print:
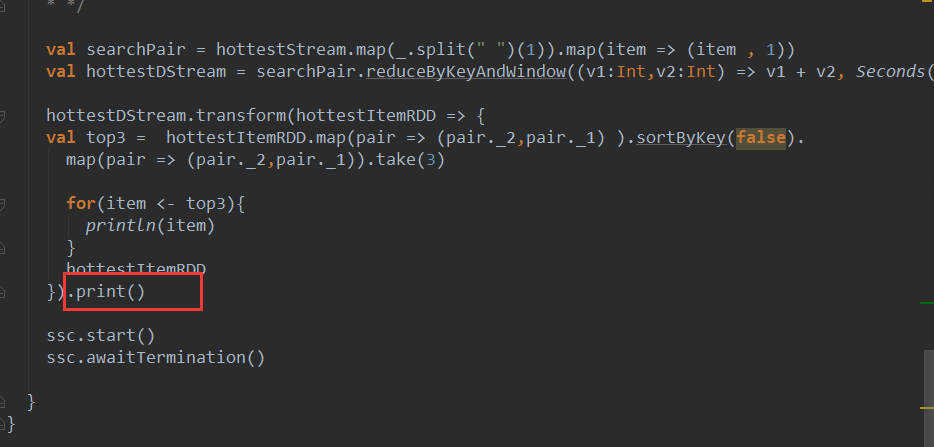
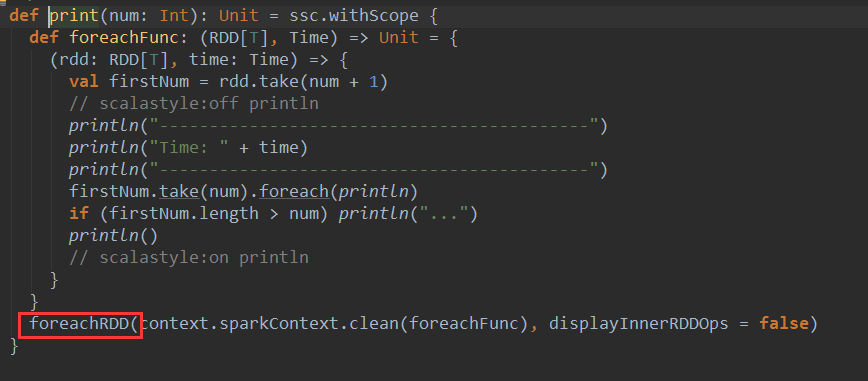
.print()与foreachRDD直接使用RDD不同,foreachRDD里面直接定义RDD action操作,foreachFunc触发真正的action。
1、foreachDStream和Job的执行没有关系,不会触发Job执行。
2、有foreachDStream执行会产生Job是不对的,只根据框架来调度Job的执行。
foreachRDD的代码中对RDD的操作,如果没有action操作则不会执行action的操作。
总结:
1、foreachDStream的产生有两种方式:
(1)DStream的action,此时真正导致作业产生,且作业执行
(2)DStream的foreachRDD也会产生Job,如果里面没有action不会执行作业
foreachRDD是Spark Streaming的后门,直接对rdd的操作,背后封装成foreachRDD的操作。
2、在Spark Streaming的所有逻辑操作都是对DStream的操作,对DStream的操作其实就是对RDD的操作,DStream是RDD的模板。
后面的DStream对前面的DStream有依赖:

对map操作产生map的DStream:
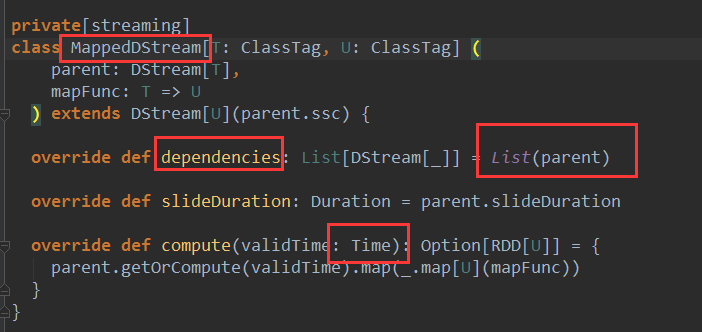
基于DStream怎么产生rdd?通过batchInterval。研究DStream是怎么生成,看DStream的操作触发RDD的生成。
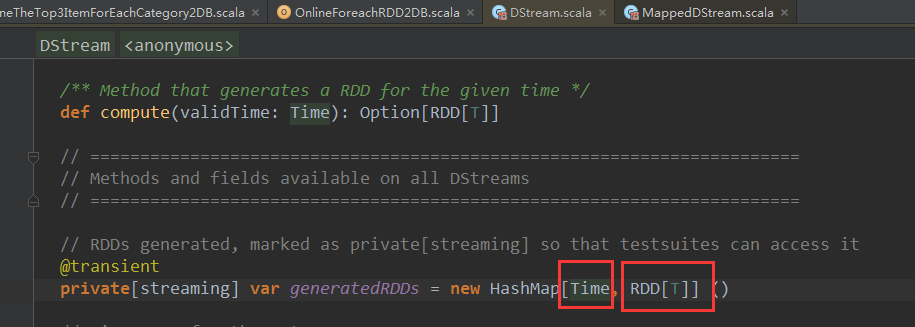
根据时间实例产生RDD,和batchDuration对齐的,如:timer实例就是1秒,1秒生成一个RDD,每个RDD对应一个Job,因为RDD就是DStream操作的时间间隔的最后一个RDD,后面的RDD对前面的RDD有依赖关系,后面对前面有依赖可以推到出整个依赖链条。
官网说明如下:
计算从后往前推,计算只需要获取最后一个的RDD的句柄。根据时间从后往前找出RDD的依赖关系,从而找出对应的空间关系。
generatedRDDs在哪里被实例化的?搞清楚了这里的HashMap在哪里被实例化的话,就知道RDD是怎么产生的。
1、 DStream中的getOrCompute会根据时间生成RDD。
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
//compute根据时间计算产生RDD
compute(time)
}
}
//rddOption里面有RDD生成的逻辑,然后生成的RDD,会put到generatedRDDs中
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}后面的rdd和batchDuration对应的rdd,DStream有个getOrComputer方法,根据batchDuration生成rdd的,可以是缓存或计算级别算出来。
/** Checks whether the 'time' is valid wrt slideDuration for generating RDD */
private[streaming] def isTimeValid(time: Time): Boolean = {
if (!isInitialized) {
throw new SparkException (this + " has not been initialized")
} else if (time <= zeroTime || ! (time - zeroTime).isMultipleOf(slideDuration)) {
logInfo("Time " + time + " is invalid as zeroTime is " + zeroTime +
" and slideDuration is " + slideDuration + " and difference is " + (time - zeroTime))
false
} else {
logDebug("Time " + time + " is valid")
true
}
}到此处,RDD变量生成了,但是并没有执行,只是在逻辑级别的代码,可以在框架级别进行优化管理。
注意:SparkStreaming实际上在没有输入数据的时候仍然会产生RDD,可以在此处修改源码,提升性能。
2、 在ReceiverInputDStream中compute源码如下:ReceiverInputDStream会生成计算链条中的首个RDD。后面的RDD就会依赖此RDD。
//如果没有输入数据会产生一系列空的RDD
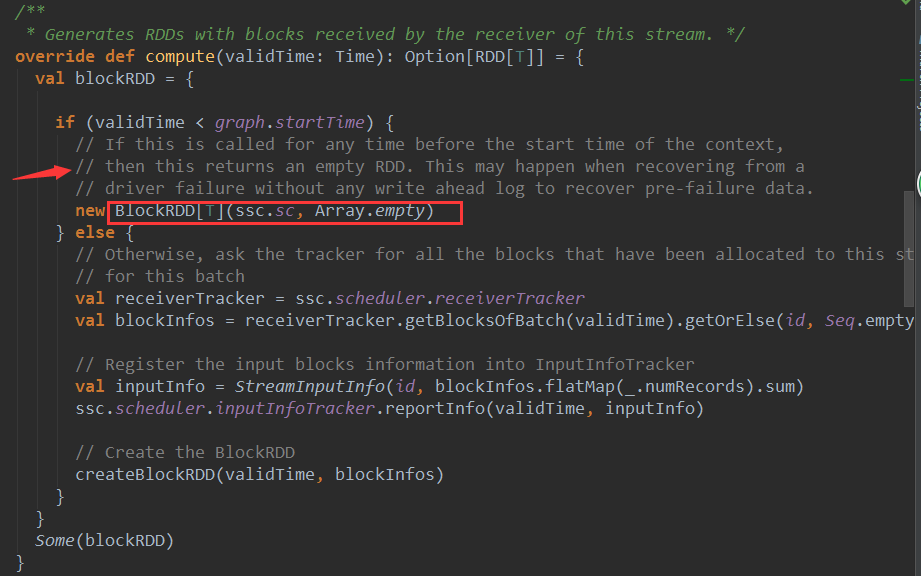
3、 createBlockRDD源码如下:
private[streaming] def createBlockRDD(time: Time, blockInfos: Seq[ReceivedBlockInfo]): RDD[T] = {
if (blockInfos.nonEmpty) {
val blockIds = blockInfos.map { _.blockId.asInstanceOf[BlockId] }.toArray
// Are WAL record handles present with all the blocks
val areWALRecordHandlesPresent = blockInfos.forall { _.walRecordHandleOption.nonEmpty }
if (areWALRecordHandlesPresent) {
// If all the blocks have WAL record handle, then create a WALBackedBlockRDD
val isBlockIdValid = blockInfos.map { _.isBlockIdValid() }.toArray
val walRecordHandles = blockInfos.map { _.walRecordHandleOption.get }.toArray
new WriteAheadLogBackedBlockRDD[T](
ssc.sparkContext, blockIds, walRecordHandles, isBlockIdValid)
} else {
// Else, create a BlockRDD. However, if there are some blocks with WAL info but not
// others then that is unexpected and log a warning accordingly.
if (blockInfos.find(_.walRecordHandleOption.nonEmpty).nonEmpty) {
if (WriteAheadLogUtils.enableReceiverLog(ssc.conf)) {
logError("Some blocks do not have Write Ahead Log information; " +
"this is unexpected and data may not be recoverable after driver failures")
} else {
logWarning("Some blocks have Write Ahead Log information; this is unexpected")
}
}
//校验数据是否还存在,不存在就过滤掉,此时的master是BlockManager
val validBlockIds = blockIds.filter { id =>
ssc.sparkContext.env.blockManager.master.contains(id)
}
if (validBlockIds.size != blockIds.size) {
logWarning("Some blocks could not be recovered as they were not found in memory. " +
"To prevent such data loss, enabled Write Ahead Log (see programming guide " +
"for more details.")
}
new BlockRDD[T](ssc.sc, validBlockIds)
}
} else {
// If no block is ready now, creating WriteAheadLogBackedBlockRDD or BlockRDD
// according to the configuration
if (WriteAheadLogUtils.enableReceiverLog(ssc.conf)) {
new WriteAheadLogBackedBlockRDD[T](
ssc.sparkContext, Array.empty, Array.empty, Array.empty)
} else {
new BlockRDD[T](ssc.sc, Array.empty)
}
}
}上述都是从逻辑方面把RDD的生成流程走了一遍,下面我们就看正在开始是在哪里触发的。
在JobGenerator中generateJobs源码如下:
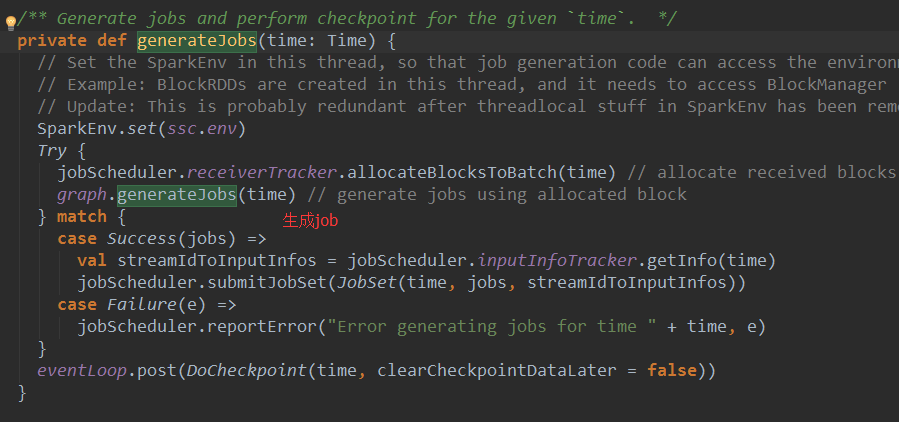
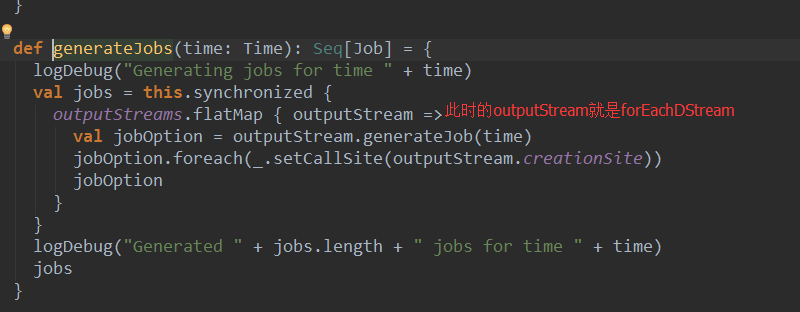
2、 在DStreamGraph中我们前面分析的RDD的产生的动作正在被触发了。















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









