







到网上下载ik analyzer包
download
解压后得如下目录:
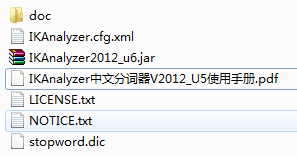
我们先在solr_home(我的solo_home是F:\solr-4.6.0\solr\example\solr)下新建一个lib文件夹,把上述解压后的IKAnalyzer2012FF_u1.jar文件拷贝到刚刚新建的lib文件夹中。然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到F:\solr-4.6.0\solr\example\solr\collection1\conf目录下(也就是跟schema.xml同一个目录下),最后在schema.xml中增加一段配置:
1、 将IKAnalyzer-2012-4x.jar或者IKAnalyzer2012FF_u1.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下;

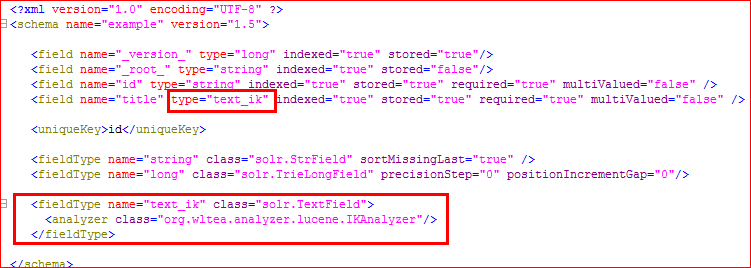
2、 然后在example\solr\collection1\conf\schema.xml 中添加fieldType :
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>如果哪一个字段的类型是“text_ik”,该字段将进行中文分词,比如(如图),title字段就可以进行中文分词,其他的字段不能使用中文分词:
启动solr测试java -jar start.jar:
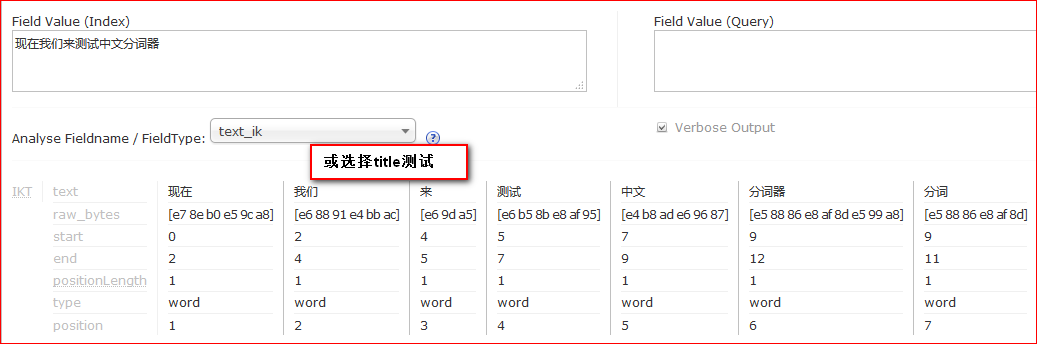
最后测试中文的时候可以选择用text_ik(就是上述配置中fieldType name=”text_ik”定义的)测试;也可以选择 title (上述配置字段 field name="title" type="text_ik"的)测试。效果如下:















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









