







 超级会员免费看
超级会员免费看
Orange3 是一款以 可视化编程 为核心的数据挖掘和机器学习工具,其界面设计直观且模块化,用户通过拖放组件(Widgets)构建数据分析流程。以下是其界面菜单功能的详细分类与说明:
一、主菜单栏
位于界面顶部,提供全局操作和设置功能:
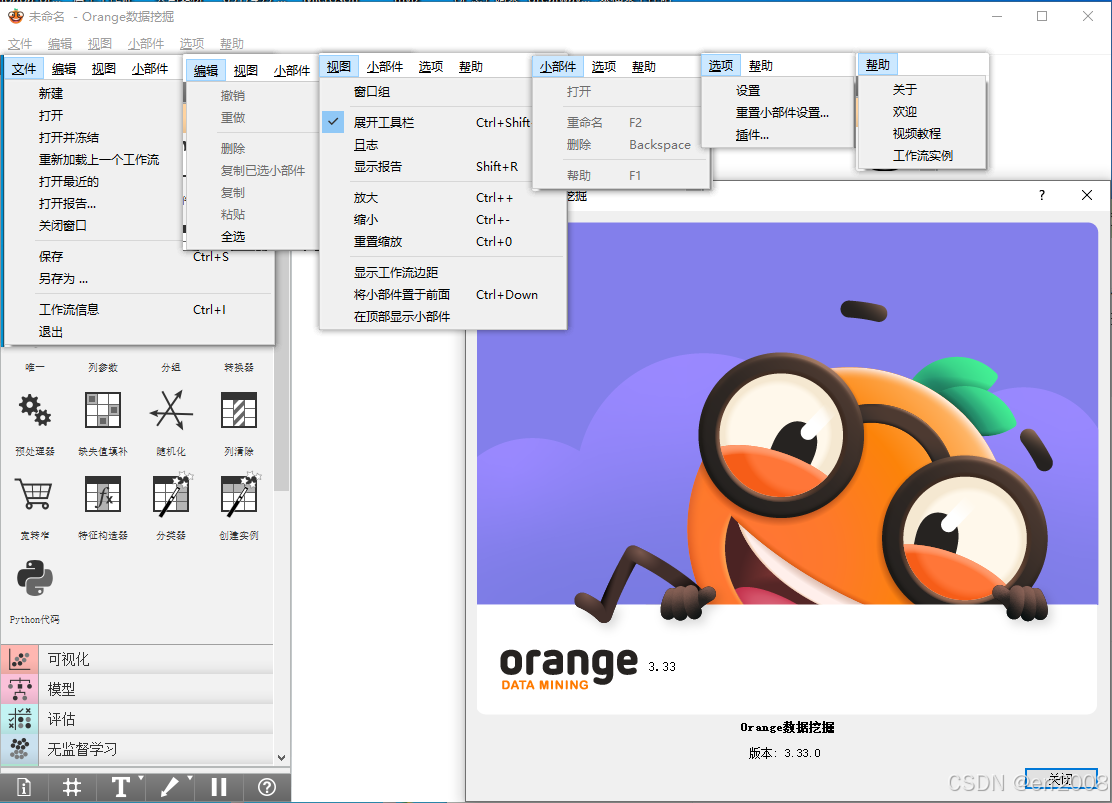
文件(File)
新建/打开/保存工作流:创建或加载 .ows 格式的工作流文件 。
导入/导出数据:支持 CSV、Excel、SQL 数据库等多种数据格式。
退出程序:关闭 Orange3 应用。
编辑(Edit)
撤销/重做:回退或恢复操作步骤。
复制/粘贴组件:快速复用已配置的 Widgets。
删除连接线:调整组件间的数据传递关系。
视图(View)
调整画布布局:扩展画布区域(如隐藏左侧工具栏),优化工作空间 。
切换语言:支持多语言界面(需安装语言包) 。
主题设置:切换浅色/深色主题。
工具(Tools)
安装扩展插件:加载自然语言处理、网络分析等附加功能模块 。
Python 脚本编辑器:直接编写或调试 Python 代码,增强数据处理能力。
帮助(Help)
官方文档:访问用户手册和 API 文档 。
示例工作流:提供 Iris 数据集、房价预测等经典案例参考。
二、小部件分类面板
位于界面左侧,按功能模块分类,支持拖放至画布构建流程:
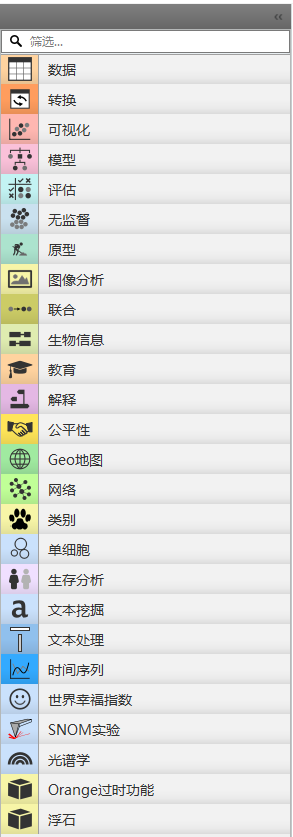
数据(Data)
文件(File):加载本地或在线数据源。
数据表(Data Table):以表格形式查看原始数据 。
预处理(Preprocess):包含数据过滤(Select Rows)、缺失值处理、离散化等工具。
可视化(Visualize)
散点图(Scatter Plot):探索变量间关系,支持交互式选择数据子集 。
箱线图(Box Plot):分析数据分布和异常值。
直方图(Histogram):查看单变量分布情况。
树图/热力图:用于模型解释(如决策树)或聚类结果展示。
模型(Model)
分类算法:如决策树(Tree)、支持向量机(SVM)、随机森林等。
回归算法:如线性回归、岭回归。
聚类算法:如 K-Means、层次聚类 。
评估(Evaluate)
交叉验证(Cross Validation):验证模型泛化能力。
混淆矩阵(Confusion Matrix):评估分类模型性能 。
ROC 曲线:分析分类器阈值效果。
非监督学习(Unsupervised)
PCA:降维分析。
关联规则(Association Rules):挖掘频繁项集
扩展模块(Add-ons)
文本挖掘(Text Mining):词云、TF-IDF 分析。
时间序列(Time Series):趋势预测与周期性分析 。
三、画布操作与右键菜单
组件连接与配置
拖放组件后,通过连接线传递数据流(如 File → Scatter Plot → Data Table)。
双击组件进入参数设置界面(如调整散点图的坐标轴、颜色分组)
右键快捷菜单
添加组件:通过搜索框快速定位所需 Widgets 。
编辑连接:调整数据流向或删除连接 。
复制/删除组件:管理画布上的元素。
四、高级功能与技巧
Python 集成
通过 Python Script 组件调用自定义脚本,处理复杂数据或集成第三方库(如 Pandas、Scikit-learn)。
工作流复用
保存常用流程模板(如数据清洗+模型训练),提升效率 。
交互式探索
在可视化图中选择数据子集,联动其他组件实时更新分析结果(如选择散点图中的异常点,查看其在数据表中的记录)。
五、适用场景示例
教育领域:教师通过可视化界面演示线性回归拟合过程,增强学生理解
商业分析:结合关联规则挖掘客户购买行为,优化商品推荐策略
科研实验:利用扩展插件处理基因表达数据或医学影像
通过以上功能模块的灵活组合,Orange3 能够覆盖从数据预处理到模型部署的全流程,适合不同层次用户的需求


















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











