







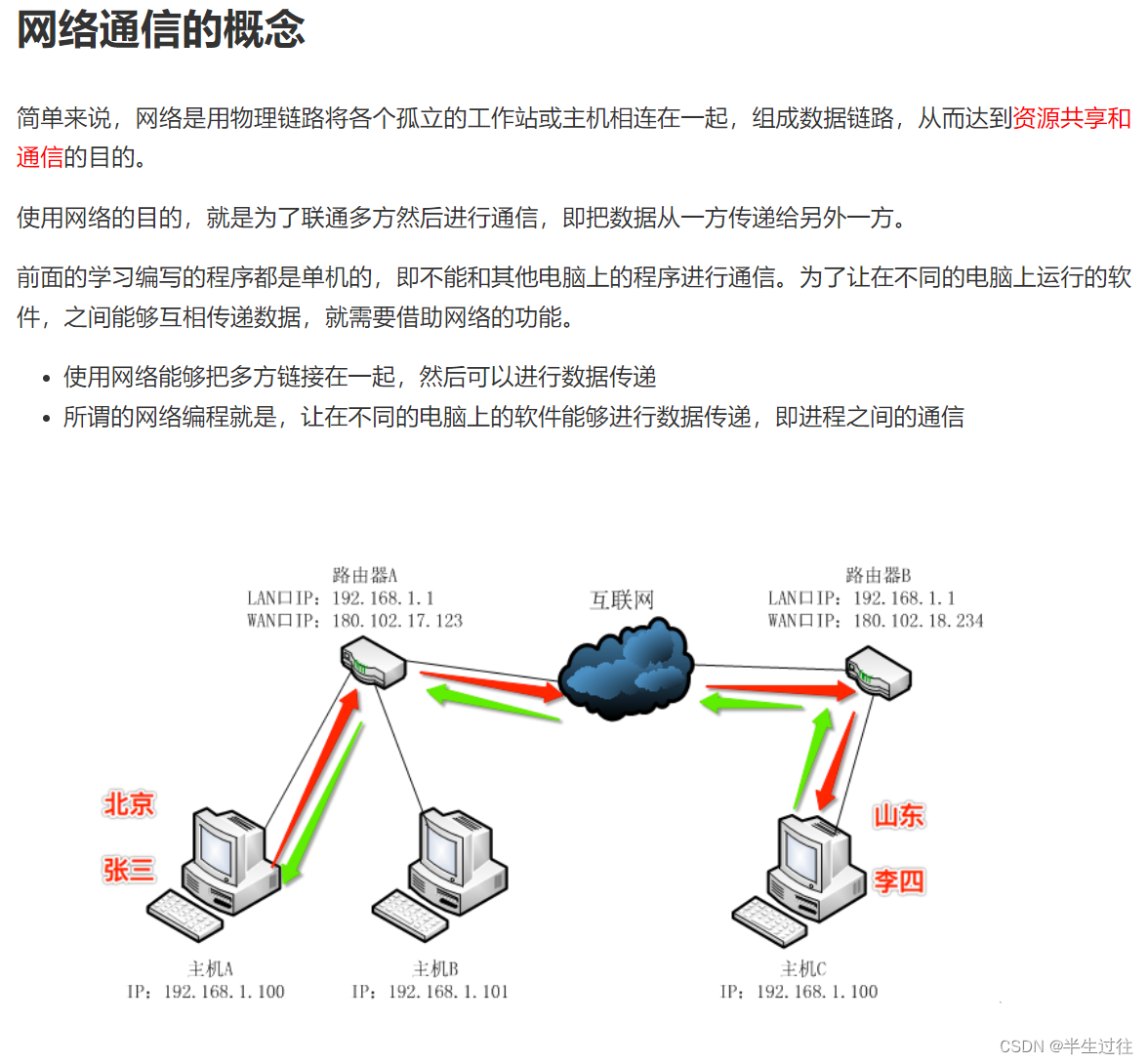
网络了解



网络调试助手 NetAssist.exe
NetAssist.exe
使用方法请自行寻找
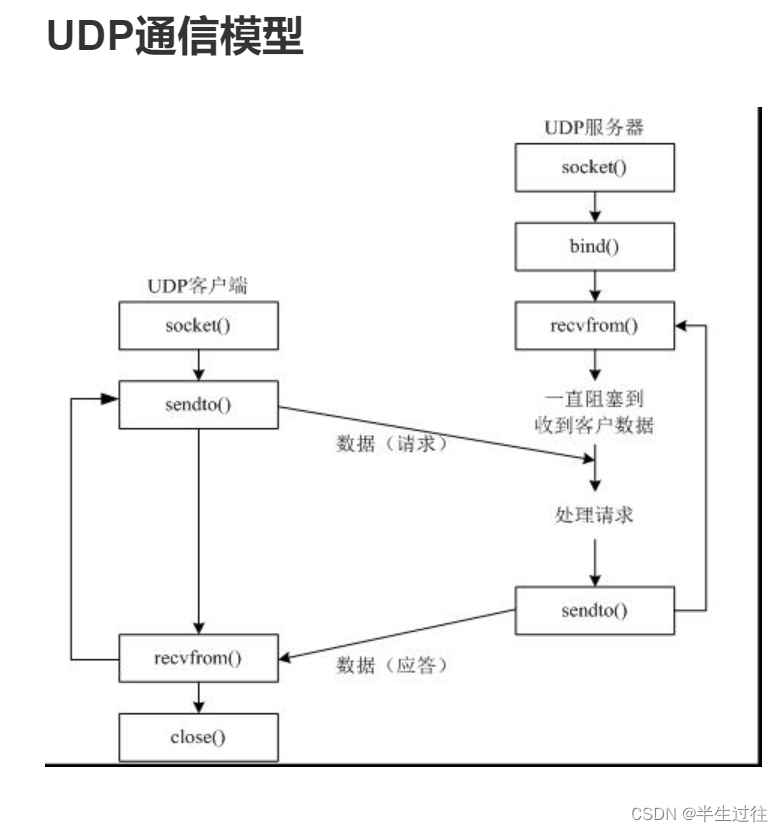
UDP协议 (只能一来一回的的发消息,不可连续发送)
UDP 是User Datagram Protocol的简称, 中文名是用户数据报协议。在通信开始之前,不需要建立相关的链接,只需要发送数据即可,类似于生活中,“写信”。
udp网络程序-发送数据
import socket
# 不同电脑之间的通信需要使用socket
# socket可以在不同的电脑间通信;还可以在同一个电脑的不同程序之间通信
# 1. 创建socket,并连接
# AF_INET:表示这个socket是用来进行网络连接
# SOCK_DGRAM:表示连接是一个 udp 连接
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2. 发送数据
# data:要发送的数据,它是二进制的数据
# address:发送给谁,参数是一个元组,元组里有两个元素
# 第0个表示目标的ip地址,第1个表示程序的端口号
# 给 192.168.31.199 这台主机的 9000 端口上发送了 hello
# 端口号:0~65536 0~1024 不要用,系统一些重要的服务在使用
# 找一个空闲的端口号
s.sendto('下午好'.encode('utf8'), ('192.168.31.199', 9090))
# 3. 关闭socket
s.close()
udp网络程序-接收数据
import socket
# 创建一个基于 udp 的网络socket连接
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定端口号和ip地址
s.bind(('192.168.31.199', 9090))
# recvfrom 接收数据
# content = s.recvfrom(1024)
# print(content)
# 接收到的数据是一个元组,元组里有两个元素
# 第 0 个元素是接收到的数据,第 1 个元素是发送方的 ip地址和端口号
data, addr = s.recvfrom(1024) # recvfrom是一个阻塞的方法,等待,接收到消息才开始真正执行
print('从{}地址{}端口号接收到了消息,内容是:{}'.format(addr[0], addr[1], data.decode('utf8')))
s.close()
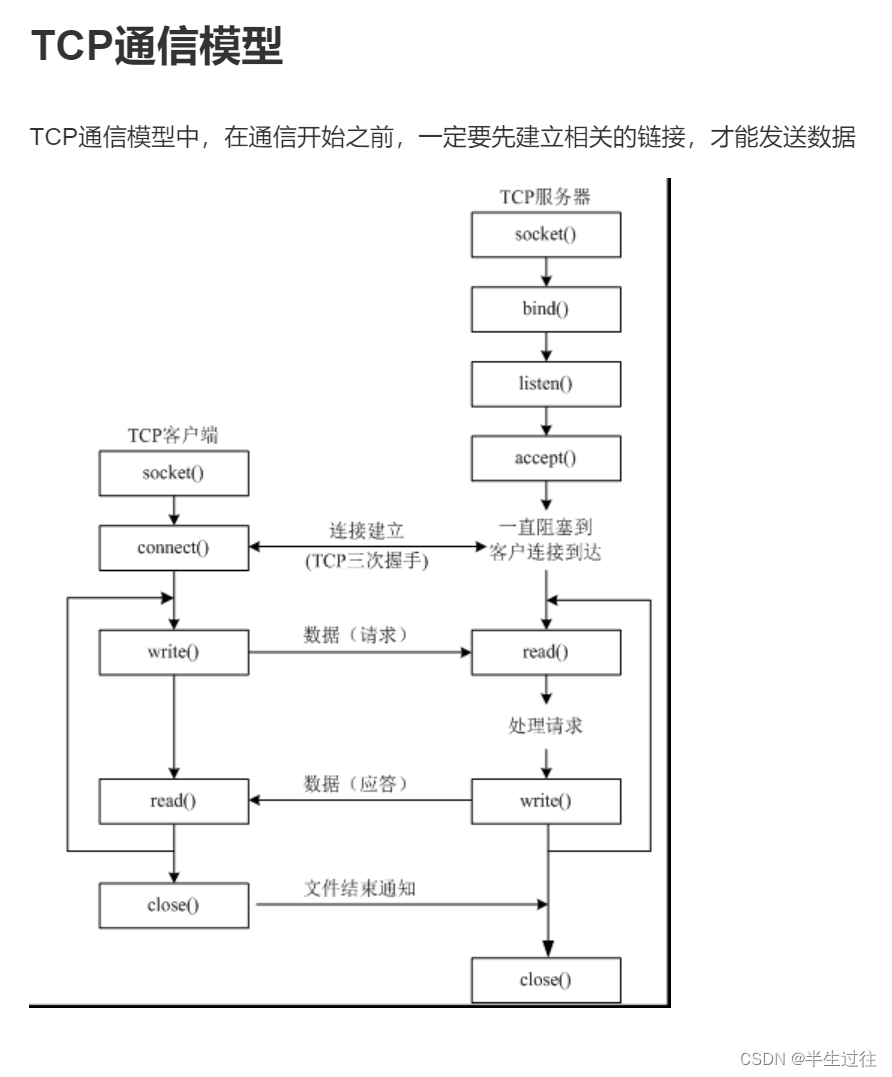
TCP协议
TCP协议,传输控制协议(英语:Transmission Control Protocol,缩写为 TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
TCP通信需要经过创建连接、数据传送、终止连接三个步骤。
TCP通信模型中,在通信开始之前,一定要先建立相关的链接,才能发送数据,类似于生活中,“打电话”。
- TCP特点
-
面向连接
通信双方必须先建立连接才能进行数据的传输,双方都必须为该连接分配必要的系统内核资源,以管理连接的状态和连接上的传输。双方间的数据传输都可以通过这一个连接进行。
完成数据交换后,双方必须断开此连接,以释放系统资源。
这种连接是一对一的,因此TCP不适用于广播的应用程序,基于广播的应用程序请使用UDP协议。
-
可靠传输
1)TCP采用发送应答机制
TCP发送的每个报文段都必须得到接收方的应答才认为这个TCP报文段传输成功2)超时重传
发送端发出一个报文段之后就启动定时器,如果在定时时间内没有收到应答就重新发送这个报文段。 TCP为了保证不发生丢包,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的包发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。3)错误校验
TCP用一个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验和。4) 流量控制和阻塞管理
流量控制用来避免主机发送得过快而使接收方来不及完全收下。 -
TCP与UDP的区别
面向连接(确认有创建三方交握,连接已创建才作传输。)
有序数据传输
重发丢失的数据包
舍弃重复的数据包
无差错的数据传输
阻塞/流量控制
-
TCP 客户端建立
import socket
# 基于tcp协议的socket连接
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 在发送数据之前,必须要先和服务器建立连接
s.connect(('192.168.31.199', 9090)) # 调用connect 方法连接到服务器
s.send('hello'.encode('utf8'))
# udp 直接使用sendto发送数据
# s.sendto('hello'.encode('utf8'),('192.168.31.199',9090))
s.close()
TCP 服务端建立
import socket
# 创建一个socket连接
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('192.168.31.199', 9090))
s.listen(128) # 把socket变成一个被动监听的socket
# (
# <socket.socket fd=512, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('192.168.31.199', 9090), raddr=('192.168.31.185', 38096)>,
# ('192.168.31.185', 38096)
# )
# 接收到的结果是一个元组,元组里有两个元素
# 第 0 个元素是客户端的socket连接,第 1 个元素是客户端的 ip 地址和端口号
# x = s.accept() # 接收客户端的请求
client_socket, client_addr = s.accept()
# udp里接收数据,使用的recvfrom
data = client_socket.recv(1024) # tcp里使用recv获取数据
print('接收到了{}客户端{}端口号发送的数据,内容是:{}'.format(client_addr[0], client_addr[1], data.decode('utf8')))
文件下载服务器
import socket, os
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('192.168.31.199', 9090))
server_socket.listen(128)
# 接收客户端的请求
client_socket, client_addr = server_socket.accept()
file_name = client_socket.recv(1024).decode('utf8')
if os.path.isfile(file_name):
# print('读取文件,返回给客户端')
with open(file_name, 'rb') as file:
content = file.read()
client_socket.send(content)
else:
print('文件不存在')
文件下载客户端
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('192.168.31.199', 9090))
# s.send('hello'.encode('utf8'))
file_name = input('清输入您要下载的文件名:')
s.send(file_name.encode('utf8'))
with open(file_name, 'wb') as file:
while True:
content = s.recv(1024)
if not content:
break
file.write(content)
s.close()
多任务 多线程
import threading, time
def dance():
for i in range(50):
time.sleep(0.2)
print('我正在跳舞')
def sing():
for i in range(50):
time.sleep(0.2)
print('我正在唱歌')
# 多个任务同时执行
# Python里执行多任务: 多线程、多进程、多进程+多线程
# dance()
# singe()
# target 需要的是一个函数,用来指定线程需要执行的任务
t1 = threading.Thread(target=dance) # 创建了线程1
t2 = threading.Thread(target=sing) # 创建了线程2
# 启动线程
t1.start()
t2.start()

多线程聊天
import socket, sys
import threading
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.bind(('172.16.180.230', 8080))
def send_msg():
while True:
msg = input('请输入您要发送的内容:')
s.sendto(msg.encode('utf8'), ('172.16.180.230', 9090))
if msg == 'exit':
break
def recv_msg():
while True:
# data的数据类型是一个元组
# 元组里第0个元素是接收到的数据
# 元组里第1个元素是发送方的ip地址和端口号
data, addr = s.recvfrom(1024)
print('接收到了{}地址{}端口的消息:{}'.format(addr[0], addr[1], data.decode('utf8')),
file=open('消息记录.txt', 'a', encoding='utf8'))
t1 = threading.Thread(target=send_msg)
t2 = threading.Thread(target=recv_msg)
t1.start()
t2.start()
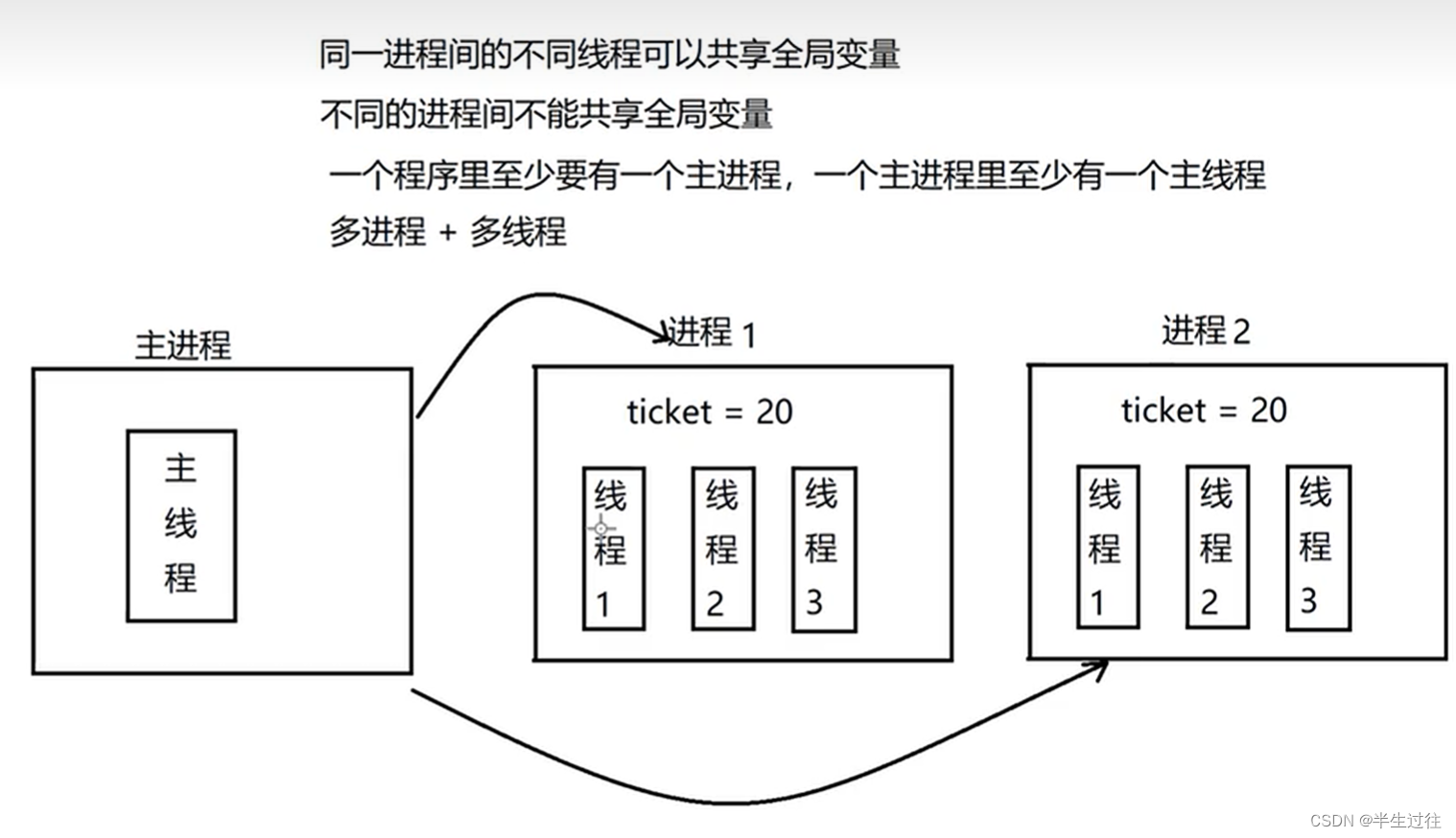
线程访问全局变量
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据。缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)。
import threading
import time
# 多个线程可以同时操作一个全局变量(多个线程共享全局变量)
# 线程安全问题
ticket = 20
def sell_ticket():
global ticket
while True: # ticket = 1 线程1:1 线程2: 1
if ticket > 0:
time.sleep(1) # 线程1: ticket=1 线程2:ticket=1
ticket -= 1 # 线程1: ticket = 0 线程2:ticket=-1
print('{}卖出一张票,还剩{}张'.format(threading.current_thread().name, ticket))
else:
print('票卖完了')
break
t1 = threading.Thread(target=sell_ticket, name='线程1')
t2 = threading.Thread(target=sell_ticket, name='线程2')
t1.start()
t2.start()
# 打印结果容易出现 -1 的结果 存在安全问题
# 线程1卖出一张票,还剩19张
# 线程2卖出一张票,还剩18张
# 线程1卖出一张票,还剩17张
# 线程2卖出一张票,还剩16张
#
# 线程1卖出一张票,还剩15张
# 线程2卖出一张票,还剩14张
# 线程2卖出一张票,还剩13张
# 线程1卖出一张票,还剩12张
#
# 线程2卖出一张票,还剩11张
# 线程1卖出一张票,还剩10张
# 线程1卖出一张票,还剩9张
# 线程2卖出一张票,还剩8张
#
# 线程1卖出一张票,还剩7张
# 线程2卖出一张票,还剩6张
#
# 线程2卖出一张票,还剩5张
# 线程1卖出一张票,还剩4张
# 线程2卖出一张票,还剩3张
# 线程1卖出一张票,还剩2张
# 线程2卖出一张票,还剩1张
# 线程1卖出一张票,还剩0张
# 票卖完了
# 线程2卖出一张票,还剩-1张
# 票卖完了
线程锁的使用
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
创建锁 mutex = threading.Lock() 锁定 mutex.acquire() 释放 mutex.release()注意:
- 如果这个锁之前是没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前 它已经被 其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止。
- 和文件操作一样,Lock也可以使用with语句快速的实现打开和关闭操作。
import threading
import time
ticket = 20
# 创建一把锁
lock = threading.Lock()
def sell_ticket():
global ticket
while True:
lock.acquire() # 加同步锁
if ticket > 0:
time.sleep(1)
ticket -= 1
lock.release()
print('{}卖出一张票,还剩{}张'.format(threading.current_thread().name, ticket))
else:
lock.release()
print('票卖完了')
break
t1 = threading.Thread(target=sell_ticket, name='线程1')
t2 = threading.Thread(target=sell_ticket, name='线程2')
t1.start()
t2.start()
# 线程1卖出一张票,还剩19张
# 线程2卖出一张票,还剩18张
# 线程1卖出一张票,还剩17张
# 线程2卖出一张票,还剩16张
# 线程1卖出一张票,还剩15张
# 线程2卖出一张票,还剩14张
# 线程1卖出一张票,还剩13张
# 线程2卖出一张票,还剩12张
# 线程1卖出一张票,还剩11张
# 线程2卖出一张票,还剩10张
# 线程1卖出一张票,还剩9张
# 线程2卖出一张票,还剩8张
# 线程1卖出一张票,还剩7张
# 线程2卖出一张票,还剩6张
# 线程1卖出一张票,还剩5张
# 线程2卖出一张票,还剩4张
# 线程1卖出一张票,还剩3张
# 线程2卖出一张票,还剩2张
# 线程2卖出一张票,还剩1张
# 线程1卖出一张票,还剩0张票卖完了
#
# 票卖完了
上锁过程:
当一个线程调用锁的acquire()方法获得锁时,锁就进入“locked”状态。每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为“blocked”状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked”状态。
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
总结
锁的好处:
- 确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
- 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
- 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁。
线程间通信
线程之间有时需要通信,操作系统提供了很多机制来实现进程间的通信,其中我们使用最多的是队列Queue.
Queue的原理
Queue是一个先进先出(First In First Out)的队列,主进程中创建一个Queue对象,并作为参数传入子进程,两者之间通过put( )放入数据,通过get( )取出数据,执行了get( )函数之后队列中的数据会被同时删除,可以使用multiprocessing模块的Queue实现多进程之间的数据传递。
import threading, queue
import time
def produce():
for i in range(10):
time.sleep(0.5)
print('{}生产++++++面包{} {}'.format('\n',threading.current_thread().name, i))
q.put('{}{}'.format(threading.current_thread().name, i))
def consumer():
while True:
time.sleep(1)
# q.get()方法时一个阻塞的方法
print('{}. .{}买到------面包{}'.format('\n', threading.current_thread().name, q.get()))
q = queue.Queue() # 创建一个q
# 一条生产线
pa = threading.Thread(target=produce, name='pa')
pb = threading.Thread(target=produce, name='pb')
pc = threading.Thread(target=produce, name='pc')
# 一条消费线
ca = threading.Thread(target=consumer, name='ca')
cb = threading.Thread(target=consumer, name='cb')
cc = threading.Thread(target=consumer, name='cc')
pa.start()
pb.start()
pc.start()
ca.start()
cb.start()
cc.start()
# 生产++++++面包pb 0
# 生产++++++面包pa 0
#
#
# 生产++++++面包pc 0
#
# . .ca买到------面包pb0
#
# 生产++++++面包pb 1
#
# . .cc买到------面包pa0
#
# 生产++++++面包pc 1
#
# 生产++++++面包pa 1
#
# . .cb买到------面包pc0
#
# 生产++++++面包pb 2
#
# 生产++++++面包pa 2
#
# 生产++++++面包pc 2
#
# . .ca买到------面包pb1
#
# . .cb买到------面包pc1
#
# . .cc买到------面包pa1
#
# 生产++++++面包pb 3
#
# 生产++++++面包pa 3
#
# 生产++++++面包pc 3
#
# 生产++++++面包pa 4
#
# 生产++++++面包pb 4
#
# 生产++++++面包pc 4
#
# . .ca买到------面包pb2
#
# . .cc买到------面包pa2
#
# . .cb买到------面包pc2
#
# 生产++++++面包pb 5
#
# 生产++++++面包pa 5
#
# 生产++++++面包pc 5
#
# 生产++++++面包pa 6
#
# 生产++++++面包pb 6
#
# 生产++++++面包pc 6
#
# . .ca买到------面包pb3
#
# . .cb买到------面包pa3
#
# . .cc买到------面包pc3
#
# 生产++++++面包pb 7
#
# 生产++++++面包pa 7
#
# 生产++++++面包pc 7
#
# 生产++++++面包pa 8
# 生产++++++面包pb 8
#
#
# 生产++++++面包pc 8
#
# . .ca买到------面包pa4
#
# . .cc买到------面包pb4
#
# . .cb买到------面包pc4
#
# 生产++++++面包pb 9
#
# 生产++++++面包pa 9
#
# 生产++++++面包pc 9
#
# . .ca买到------面包pb5
#
# . .cb买到------面包pa5
#
# . .cc买到------面包pc5
#
# . .ca买到------面包pa6
#
# . .cb买到------面包pb6
#
# . .cc买到------面包pc6
#
# . .ca买到------面包pb7
#
# . .cc买到------面包pa7
#
# . .cb买到------面包pc7
#
# . .ca买到------面包pb8
#
# . .cb买到------面包pa8
#
# . .cc买到------面包pc8
#
# . .cb买到------面包pb9
# . .ca买到------面包pa9
#
#
# . .cc买到------面包pc9
多进程
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
import multiprocessing, time, os
def dance(n):
for i in range(n):
time.sleep(0.5)
print('正在跳舞{},pid={}'.format(i, os.getpid()))
def sing(m):
for i in range(m):
time.sleep(0.5)
print('正在唱歌{},pid={}'.format(i, os.getpid()))
if __name__ == '__main__': # 进入这个页面才开始执行
print('主进程的pid={}'.format(os.getpid()))
# 创建了两个进程
# target 用来表示执行的任务
# args 用来传参,类型是一个元组
p1 = multiprocessing.Process(target=dance, args=(20,))
p2 = multiprocessing.Process(target=sing, args=(20,))
p1.start()
p2.start()
# 主进程的pid=22856
# 正在跳舞0,pid=25952
# 正在唱歌0,pid=12352
#
# 正在唱歌1,pid=12352
# 正在跳舞1,pid=25952
#
# 正在唱歌2,pid=12352
# 正在跳舞2,pid=25952
#
# 正在唱歌3,pid=12352
# 正在跳舞3,pid=25952
#
# 正在跳舞4,pid=25952
# 正在唱歌4,pid=12352
#
# 正在唱歌5,pid=12352
# 正在跳舞5,pid=25952
#
# 正在唱歌6,pid=12352
# 正在跳舞6,pid=25952
#
# 正在唱歌7,pid=12352
# 正在跳舞7,pid=25952
#
# 正在跳舞8,pid=25952
# 正在唱歌8,pid=12352
# 正在唱歌9,pid=12352
# 正在跳舞9,pid=25952
# 正在唱歌10,pid=12352
# 正在跳舞10,pid=25952
# 正在唱歌11,pid=12352
# 正在跳舞11,pid=25952
# 正在唱歌12,pid=12352
# 正在跳舞12,pid=25952
# 正在唱歌13,pid=12352
# 正在跳舞13,pid=25952
# 正在唱歌14,pid=12352
# 正在跳舞14,pid=25952
# 正在唱歌15,pid=12352
# 正在跳舞15,pid=25952
# 正在唱歌16,pid=12352
# 正在跳舞16,pid=25952
# 正在跳舞17,pid=25952
# 正在唱歌17,pid=12352
# 正在跳舞18,pid=25952
# 正在唱歌18,pid=12352
# 正在跳舞19,pid=25952
# 正在唱歌19,pid=12352
方法说明
Process( target [, name [, args [, kwargs]]])- target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
- args:给target指定的函数传递的参数,以元组的方式传递
- kwargs:给target指定的函数传递命名参数
- name:给进程设定一个名字,可以不设定
- Process创建的实例对象的常用方法:
- start():启动子进程实例(创建子进程)
- is_alive():判断进程子进程是否还在活着
- join([timeout]):是否等待子进程执行结束,或等待多少秒
- terminate():不管任务是否完成,立即终止子进程
- Process创建的实例对象的常用属性:
- name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程的pid(进程号)
示例:
from multiprocessing import Process
import os
from time import sleep
def run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)
if __name__=='__main__':
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1秒中之后,立即结束子进程
p.terminate()
p.join()
Pool
开启过多的进程并不能提高你的效率,反而会降低你的效率,假设有500个任务,同时开启500个进程,这500个进程除了不能一起执行之外(cpu没有那么多核),操作系统调度这500个进程,让他们平均在4个或8个cpu上执行,这会占用很大的空间。
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
def task(n):
print('{}----->start'.format(n))
time.sleep(1)
print('{}------>end'.format(n))
if __name__ == '__main__':
p = Pool(8) # 创建进程池,并指定线程池的个数,默认是CPU的核数
for i in range(1, 11):
# p.apply(task, args=(i,)) # 同步执行任务,一个一个的执行任务,没有并发效果
p.apply_async(task, args=(i,)) # 异步执行任务,可以达到并发效果
p.close()
p.join()
进程池获取任务的执行结果:
def task(n):
print('{}----->start'.format(n))
time.sleep(1)
print('{}------>end'.format(n))
return n ** 2
if __name__ == '__main__':
p = Pool(4)
for i in range(1, 11):
res = p.apply_async(task, args=(i,)) # res 是任务的执行结果
print(res.get()) # 直接获取结果的弊端是,多任务又变成同步的了
p.close()
# p.join() 不需要再join了,因为 res.get()本身就是一个阻塞方法
异步获取线程的执行结果:
import time
from multiprocessing.pool import Pool
def task(n):
print('{}----->start'.format(n))
time.sleep(1)
print('{}------>end'.format(n))
return n ** 2
if __name__ == '__main__':
p = Pool(4)
res_list = []
for i in range(1, 11):
res = p.apply_async(task, args=(i,))
res_list.append(res) # 使用列表来保存进程执行结果
for re in res_list:
print(re.get())
p.close()
1----->start
# 2----->start
# 3----->start
# 4----->start
# 1------>end
# 5----->start
# 1
# 4------>end
# 2------>end
# 3------>end
# 6----->start
# 7----->start
# 4
# 8----->start
# 9
# 16
# 5------>end
# 9----->start
# 25
# 7------>end
# 6------>end
# 10----->start
# 36
# 49
# 8------>end
# 64
# 9------>end
# 81
# 10------>end
# 100
进程间不能共享全局变量
import os, multiprocessing, threading
n = 100
def test():
global n
n += 1
print('test==={}里n的值是{}'.format(os.getpid(), hex(id(n))))
def demo():
global n
n += 1
print('demo===={}里n的值是{}'.format(os.getpid(), hex(id(n))))
print(threading.current_thread().name)
test() # 101
demo() # 102
# 同一个主进程里的两个子线程。线程之间可以共享同一进程的全局变量
# t1 = threading.Thread(target=test)
# t2 = threading.Thread(target=demo)
# t1.start()
# t2.start()
# if __name__ == '__main__':
# 不同进程各自保存一份全局变量,不会共享全局变量
# p1 = multiprocessing.Process(target=test)
# p2 = multiprocessing.Process(target=demo)
# p1.start() # 101
# p2.start() # 101
from multiprocessing import Process
import os
nums = [11, 22]
def work1():
"""子进程要执行的代码"""
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
def work2():
"""子进程要执行的代码"""
nums.pop()
print("in process2 pid=%d ,nums=%s" % (os.getpid(), nums))
if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
p1.join()
p2 = Process(target=work2)
p2.start()
print('in process0 pid={} ,nums={}'.format(os.getpid(),nums))
# in process1
# pid = 23336, nums = [11, 22]
# in process1
# pid = 23336, nums = [11, 22, 0]
# in process1
# pid = 23336, nums = [11, 22, 0, 1]
# in process1
# pid = 23336, nums = [11, 22, 0, 1, 2]
# in process0
# pid = 2164, nums = [11, 22]
# in process2
# pid = 27396, nums = [11]
线程和进程的区别
- 功能
- 进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ。
- 线程,能够完成多任务,比如 一个QQ中的多个聊天窗口。
- 定义的不同
- 进程是系统进行资源分配和调度的一个独立单位.
- 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运 行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源 (如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
- 区别
- 一个程序至少有一个进程,一个进程至少有一个线程.
- 线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
- 线线程不能够独立执行,必须依存在进程中
- 可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
- 优缺点
- 线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
进程间通信-Queue
from multiprocessing import Queue
q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) #False
q.put("消息3")
print(q.full()) #True
#因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常,第二个Try会立刻抛出异常
try:
q.put("消息4",True,2)
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
try:
q.put_nowait("消息4")
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
#推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息4")
#读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
# False
# True
# 消息列队已满,现有消息数量: 3
# 消息列队已满,现有消息数量: 3
# 消息1
# 消息2
# 消息3
-
初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
- Queue.qsize():返回当前队列包含的消息数量;
- Queue.empty():如果队列为空,返回True,反之False ;
- Queue.full():如果队列满了,返回True,反之False;
- Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
-
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常;
-
2)如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
- Queue.get_nowait():相当Queue.get(False);
- Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True;
-
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常;
-
2)如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
- Queue.put_nowait(item):相当Queue.put(item, False);
import os, multiprocessing, time
def producer(x):
for i in range(4):
time.sleep(0.5)
print('生产了+++++++pid{} {}'.format(os.getpid(), i))
x.put('pid{} {}'.format(os.getpid(), i))
def consumer(x):
for i in range(4):
time.sleep(0.3)
print('消费了-------{}'.format(x.get()))
if __name__ == '__main__':
q = multiprocessing.Queue() # 要当成全局变量传给每一个进程
p1 = multiprocessing.Process(target=producer, args=(q,))
p2 = multiprocessing.Process(target=producer, args=(q,))
p3 = multiprocessing.Process(target=producer, args=(q,))
p1.start()
p2.start()
p3.start()
c2 = multiprocessing.Process(target=consumer, args=(q,))
c2.start()
# 生产了+++++++pid17816 0
# 消费了-------pid17816 0
# 生产了+++++++pid13004 0
# 生产了+++++++pid24400 0
# 消费了-------pid13004 0
# 生产了+++++++pid17816 1
# 生产了+++++++pid13004 1
# 生产了+++++++pid24400 1
# 消费了-------pid24400 0
# 消费了-------pid17816 1
# 生产了+++++++pid17816 2
# 生产了+++++++pid13004 2
# 生产了+++++++pid24400 2
# 生产了+++++++pid17816 3
# 生产了+++++++pid13004 3
# 生产了+++++++pid24400 3
使用Queue实现进程共享
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
break
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 等待pw结束:
pw.join()
# 启动子进程pr,读取:
pr.start()
pr.join()
print('所有数据都写入并且读完')
# Put A to queue...
# Put B to queue...
# Put C to queue...
# Get A from queue.
# Get B from queue.
# Get C from queue.
# 所有数据都写入并且读完
import multiprocessing, queue
# q1 = multiprocessing.Queue() # 进程间通信
# q2 = queue.Queue() # 线程间通信
# 创建队列时,可以指定最大长度。默认值是0,表示不限
q = multiprocessing.Queue(5)
q.put('hello')
q.put('good')
q.put('yes')
q.put('ok')
q.put('hi')
# print(q.full()) # True 判断是否放满了
# q.put('how') # 无法放进去,规定放 5个
# # block = True:表示是阻塞,如果队列已经满了,就等待
# # timeout 超时,等待多久以后程序会出错,单位是秒
# q.put('how', block=True, timeout=5) # block=True, timeout=5 有阻塞 等待5秒
# q.put_nowait('how') # 等价于 q.put('how',block=False) # block=False 放进去就放 放不进去就崩
print(q.get()) # hello
print(q.get()) # good
print(q.get()) # yes
print(q.get()) # ok
print(q.get()) # hi
# print(q.get()) # 拿不到了 阻塞 进程不会停止 一直等
# q.get(block=True, timeout=10) # 设置超时
# q.get_nowait() # 拿不到了 立刻报错
进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg, os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random() * 2)
t_stop = time.time()
print(msg, "执行完毕,耗时%0.2f" % (t_stop - t_start))
if __name__ == '__main__':
po = Pool(3) # 定义一个进程池,最大进程数3
for i in range(0, 10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker, (i,))
print("----start----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
# ----start----
# 0开始执行,进程号为21804
# 1开始执行,进程号为17268
# 2开始执行,进程号为12340
# 0 执行完毕,耗时1.46
# 3开始执行,进程号为21804
# 1 执行完毕,耗时1.63
# 4开始执行,进程号为17268
# 2 执行完毕,耗时1.66
# 5开始执行,进程号为12340
# 3 执行完毕,耗时1.12
# 6开始执行,进程号为21804
# 4 执行完毕,耗时1.10
# 7开始执行,进程号为17268
# 7 执行完毕,耗时0.53
# 8开始执行,进程号为17268
# 6 执行完毕,耗时0.97
# 9开始执行,进程号为21804
# 5 执行完毕,耗时1.94
# 9 执行完毕,耗时0.60
# 8 执行完毕,耗时1.18
# -----end-----

-
multiprocessing.Pool常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表, kwds为传递给func的关键字参数列表;
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
# 修改import中的Queue为Manager
from multiprocessing import Manager, Pool
import os, time, random
def reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))
def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "helloworld":
q.put(i)
if __name__ == "__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())
# (3256)
# start
# writer启动(5312), 父进程为(3256)
# reader启动(27216), 父进程为(3256)
# reader从Queue获取到消息:h
# reader从Queue获取到消息:e
# reader从Queue获取到消息:l
# reader从Queue获取到消息:l
# reader从Queue获取到消息:o
# reader从Queue获取到消息:w
# reader从Queue获取到消息:o
# reader从Queue获取到消息:r
# reader从Queue获取到消息:l
# reader从Queue获取到消息:d
# (3256)
# End
HTTP(了解)
手动搭建HTTP服务器
HTTP 服务器
import re
import socket
from multiprocessing import Process
class WSGIServer():
def __init__(self, server, port, root):
self.server = server
self.port = port
self.root = root
self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.server_socket.bind((self.server, self.port))
self.server_socket.listen(128)
def handle_socket(self, socket):
data = socket.recv(1024).decode('utf-8').splitlines()[0]
file_name = re.match(r'[^/]+(/[^ ]*)', data)[1]
# print(file_name)
if file_name == '/':
file_name = self.root + '/index.html'
else:
file_name = self.root + file_name
try:
file = open(file_name, 'rb')
except IOError:
response_header = 'HTTP/1.1 404 NOT FOUND \r\n'
response_header += '\r\n'
response_body = '========Sorry,file not found======='.encode('utf-8')
else:
response_header = 'HTTP/1.1 200 OK \r\n'
response_header += '\r\n'
response_body = file.read()
finally:
socket.send(response_header.encode('utf-8'))
socket.send(response_body)
def forever_run(self):
while True:
client_socket, client_addr = self.server_socket.accept()
# self.handle_socket(client_socket)
p = Process(target=self.handle_socket, args=(client_socket,))
p.start()
client_socket.close()
if __name__ == '__main__':
ip = '0.0.0.0'
port = 8899
server = WSGIServer(ip, port, './pages')
print('server is running at {}:{}'.format(ip, port))
server.forever_run()
HTTP 服务器
import socket
# HTTP 服务器都是基于TCP的socket链接
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('192.168.31.199', 9090))
server_socket.listen(128)
# 获取的数据是一个元组,元组里有两个元素
# 第 0 个元素是 客户端的socket链接
# 第 1 个元素是 客户端的ip地址和端口号
while True:
client_socket, client_addr = server_socket.accept()
# 从客户端的 socket 里获取数据
data = client_socket.recv(1024).decode('utf8')
print('接收到{}的数据{}'.format(client_addr[0], data))
# 返回内容之前,需要先设置HTTP响应头
# 设置一个响应头就换一行
client_socket.send('HTTP/1.1 200 OK\n'.encode('utf8'))
client_socket.send('content-type:text/html\n'.encode('utf8'))
# 所有的响应头设置完成以后,再换行
client_socket.send('\n'.encode('utf8'))
# 发送内容
client_socket.send('<h1 style="color:red">hello world</h1>'.encode('utf8'))
HTTP服务器函数封装
import json
from wsgiref.simple_server import make_server
def load_file(file_name, **kwargs):
try:
with open('pages/' + file_name, 'r', encoding='utf8') as file:
content = file.read()
if kwargs: # kwargs = {'username':'zhangsan','age':19,'gender':'male'}
content = content.format(**kwargs)
# {username},欢迎回来,你今年{age}岁了,你的性别是{gender}.format(**kwargs)
return content
except FileNotFoundError:
print('文件未找到')
def index():
return '欢迎来到我的首页'
def show_test():
return json.dumps({'name': 'zhangsan', 'age': 18})
def show_demo():
return load_file('xxxx.txt')
def show_hello():
return load_file('hello.html')
def show_info():
return load_file('info.html', username='zhangsan', age=19, gender='male')
def demo_app(environ, start_response):
path = environ['PATH_INFO']
status_code = '200 OK'
if path == '/':
response = index()
elif path == '/test':
response = show_test()
elif path == '/demo':
response = show_demo()
elif path == '/hello':
response = show_hello()
elif path == '/info':
response = show_info()
else:
status_code = '404 Not Found'
response = '页面走丢了'
start_response(status_code, [('Content-Type', 'text/html;charset=utf8')])
return [response.encode('utf8')]
if __name__ == '__main__':
httpd = make_server('', 8080, demo_app)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
httpd.serve_forever()
HTTP 请求头
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('192.168.31.199', 8090))
server_socket.listen(128)
while True:
client_socket, client_addr = server_socket.accept()
data = client_socket.recv(1024).decode('utf8')
print('接收到{}的数据{}'.format(client_addr[0], data))
"""
# GET 请求方式,GET/POST/PUT/DELETE... ...
# /index.html?name=jack&age=18 请求的路径以及请求参数
# HTTP/1.1 HTTP版本号
GET /index.html?name=jack&age=18 HTTP/1.1
Host: 192.168.31.199:8090 # 请求的服务器地址
Upgrade-Insecure-Requests: 1
# UA 用户代理,最开始设计的目的,是为了能从请求头里辨识浏览器的类型
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: close
"""
client_socket.send('HTTP/1.1 200 OK\n'.encode('utf8'))
client_socket.send('content-type:text/html\n'.encode('utf8'))
client_socket.send('\n'.encode('utf8'))
client_socket.send('<h1 style="color:red">hello world</h1>'.encode('utf8'))
根据不同的请求返回不同的内容
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('0.0.0.0', 8090))
server_socket.listen(128)
while True:
client_socket, client_addr = server_socket.accept()
data = client_socket.recv(1024).decode('utf8')
path = ''
if data: # # 浏览器发送过来的数据有可能是空的
path = data.splitlines()[0].split(' ')[1]
print('请求的路径是{}'.format(path))
response_body = 'hello world'
# 响应头
response_header = 'HTTP/1.1 200 OK\n' # 200 OK 成功了
if path == '/login':
response_body = '欢迎来到登录页面'
elif path == '/register':
response_body = '欢迎来到注册页面'
elif path == '/':
response_body = '欢迎来到首页'
else:
# 页面未找到 404 Page Not Found
response_header = 'HTTP/1.1 404 Page Not Found\n'
response_body = '对不起,您要查看的页面不存在!!!'
response_header += 'content-type:text/html;charset=utf8\n'
response_header += '\n'
# 响应
response = response_header + response_body
# 发送给客户端
client_socket.send(response.encode('utf8'))
面向对象的封装
import socket
class MyServer(object):
def __init__(self, ip, port):
self.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.socket.bind((ip, port))
self.socket.listen(128)
def run_forever(self):
while True:
client_socket, client_addr = self.socket.accept()
data = client_socket.recv(1024).decode('utf8')
path = ''
if data:
path = data.splitlines()[0].split(' ')[1]
response_header = 'HTTP/1.1 200 OK\n'
if path == '/login':
response_body = '欢迎来到登录页面'
elif path == '/register':
response_body = '欢迎来到注册页面'
elif path == '/':
response_body = '欢迎来到首页'
else:
response_header = 'HTTP/1.1 404 Page Not Found\n'
response_body = '对不起,您要查看的页面不存在!!!'
response_header += 'content-type:text/html;charset=utf8\n'
response_header += '\n'
response = response_header + response_body
client_socket.send(response.encode('utf8'))
server = MyServer('0.0.0.0', 9090)
server.run_forever()
WSGI接口
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello, web!”:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return '<h1>Hello, web!</h1>'
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
- environ:一个包含所有HTTP请求信息的dict对象;
-
start_response:一个发送HTTP响应的函数。
-
在application()函数中,调用:
start_response('200 OK', [('Content-Type', 'text/html')])
-
就发送了HTTP响应的Header,注意Header只能发送一次,也就是只能调用一次start_response()函数。start_response()函数接收两个参数,一个是HTTP响应码,一个是一组list表示的HTTP Header,每个Header用一个包含两个str的tuple表示。
通常情况下,都应该把Content-Type头发送给浏览器。其他很多常用的HTTP Header也应该发送。
然后,函数的返回值<h1>Hello, web!</h1>将作为HTTP响应的Body发送给浏览器。
有了WSGI,我们关心的就是如何从environ这个dict对象拿到HTTP请求信息,然后构造HTML,通过start_response()发送Header,最后返回Body。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,底层代码不需要我们自己编写,我们只负责在更高层次上考虑如何响应请求就可以了。
不过,等等,这个application()函数怎么调用?如果我们自己调用,两个参数environ和start_response我们没法提供,返回的str也没法发给浏览器。
所以application()函数必须由WSGI服务器来调用。有很多符合WSGI规范的服务器,我们可以挑选一个来用。但是现在,我们只想尽快测试一下我们编写的application()函数真的可以把HTML输出到浏览器,所以,要赶紧找一个最简单的WSGI服务器,把我们的Web应用程序跑起来。
好消息是Python内置了一个WSGI服务器,这个模块叫wsgiref,它是用纯Python编写的WSGI服务器的参考实现。所谓“参考实现”是指该实现完全符合WSGI标准,但是不考虑任何运行效率,仅供开发和测试使用。
新建WSGI服务器
-
创建hello.py文件,用来实现WSGI应用的处理函数。
def application(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) print(environ) return ['<h1>Hello, web!</h1>'.encode('utf-8'),'hello'.encode('utf-8')] -
创建server.py文件,用来启动WSGI服务器,加载appliction 函数
# 从wsgiref模块导入: from wsgiref.simple_server import make_server # 导入我们自己编写的application函数: from hello import application # 创建一个服务器,IP地址为空,端口是8000,处理函数是application: httpd = make_server('', 8000, application) print("Serving HTTP on port 8000...") # 开始监听HTTP请求: httpd.serve_forever()
wsgi服务器
from wsgiref.simple_server import make_server
# demo_app 需要两个参数
# 第 0 个参数,表示环境(电脑的环境;请求路径相关的环境)
# 第 1 个参数,是一个函数,用来返回响应头
# 这个函数需要一个返回值,返回值是一个列表
# 列表里只有一个元素,是一个二进制,表示返回给浏览器的数据
def demo_app(environ, start_response):
# environ是一个字典,保存了很多的数据
# 其中重要的一个是 PATH_INFO能够获取到用户的访问路径
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8')])
return ['hello'.encode('utf8')] # 浏览器显示的内容
if __name__ == '__main__':
# demo_app 是一个函数,用来处理用户的请求
httpd = make_server('', 8000, demo_app)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
# 代码的作用是打开电脑的浏览器,并在浏览器里输入 http://localhost:8000/xyz?abc
# import webbrowser
# webbrowser.open('http://localhost:8000/xyz?abc')
# 处理一次请求
# httpd.handle_request()
httpd.serve_forever() # 服务器在后台一致运行
自定义WSGI服务器
from wsgiref.simple_server import make_server
def demo_app(environ, start_response):
path = environ['PATH_INFO']
print('path= {}'.format(path))
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ('sss', 'dddd')])
return ['你好'.encode('utf8')]
if __name__ == '__main__':
httpd = make_server('', 8080, demo_app)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
httpd.serve_forever()
请求路径
使用if管理请求路径
文件结构:
├── server.py
├── utils.py
├── pages
└── index.html
└── templates
└── info.html
-
utlis.py文件
PAGE_ROOT = './pages' TEMPLATE_ROOT = './templates' def load_html(file_name, start_response, root=PAGE_ROOT): """ 加载HTML文件时调用的方法 :param file_name: 需要加载的HTML文件 :param start_response: 函数,用来设置响应头。如果找到文件,请求头设置为200,否则设置为410 :param root: HTML文件所在的目录。默认PAGE_ROOT表示静态HTML文件,TEMPLATE_ROOT表示的是模板文件 :return: 读取HTML文件成功的话,返回HTML文件内容;读取失败提示资源被删除 """ file_name = root + file_name try: file = open(file_name, 'rb') except IOError: start_response('410 GONE', [('Content-Type', "text/html;charset=utf-8")]) return ['资源被删除了'.encode('utf-8')] else: start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")]) content = file.read() return [content] def load_template(file_name, start_respone, **kwargs): """ 加载模板文件 :param file_name: 需要加载的模板文件名 :param start_respone: 函数,用来设置响应头。如果找到文件,请求头设置为200,否则设置为410 :param kwargs: 用来设置模板里的变量 :return: 读取HTML文件成功的话,返回HTML文件内容;读取失败提示资源被删除 """ content = load_html(file_name, start_respone, root=TEMPLATE_ROOT) html = content[0].decode('utf-8') if html.startswith('<!DOCTYPE html>'): return [html.format(**kwargs).encode('utf-8')] else: return content -
service.py文件
from wsgiref.simple_server import make_server from utils import load_html, load_template def show_home(start_response): return load_html('/index.html', start_response) def show_test(start_response): start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")]) return ['我是一段普通的文字'.encode('utf-8')] def show_info(start_response): return load_template('/info.html', start_response, name='张三',age=18}) def application(environ, start_response): path = environ.get('PATH_INFO') # 处理首页请求(加载一个HTML文件) if path == '/' or path == '/index.html': result = show_home(start_response) return result # 处理test.html请求(返回一个普通的字符串) elif path == '/test.html': return show_test(start_response) # 处理info.html请求(加载一个模板并且返回) elif path == '/info.html': return show_info(start_response) # 其它请求暂时无法处理,返回404 else: start_response('400 NOT FOUND', [('Content-Type', "text/html;charset=utf-8")]) return ['页面未找到'.encode('utf-8')] httpd = make_server('', 8000, application) print("Serving HTTP on port 8000...") httpd.serve_forever()
使用字典管理请求路径
文件结构:
├── server.py
├── utils.py
├── urls.py
├── pages
└── index.html
└── templates
└── info.html
-
urls.py文件:该文件里只有一个字典对象,用来保存请求路径和处理函数之间的对应关系。
urls = { '/': 'show_home', '/index.html': 'show_home', '/test.html': 'show_test', '/info.html': 'show_info' } -
server.py文件:
from wsgiref.simple_server import make_server from urls import urls from utils import load_html, load_template def show_home(start_response): return load_html('/index.html', start_response) def show_test(start_response): start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")]) return ['我是一段普通的文字'.encode('utf-8')] def show_info(start_response): return load_template('/info.html', start_response, name='张三',age=18}) def application(environ, start_response): path = environ.get('PATH_INFO') # 这里不再是一大堆的if...elif语句了,而是从urls字典里获取到对应的函数 func = urls.get(path) if func: return eval(func)(start_response) # 其它请求暂时无法处理,返回404 else: start_response('400 NOT FOUND', [('Content-Type', "text/html;charset=utf-8")]) return ['页面未找到'.encode('utf-8')] httpd = make_server('', 8000, application) print("Serving HTTP on port 8000...") httpd.serve_forever()
使用装饰器管理请求路径
from wsgiref.simple_server import make_server
from utils import load_html, load_template
g_url_route = {}
def route(url):
def handle_action(action):
g_url_route[url] = action
def do_action(start_response):
return action(start_response)
return do_action
return handle_action
@route('/index.html')
@route('/')
def show_home(start_response):
return load_html('/index.html', start_response)
@route('/test.html')
def show_test(start_response):
start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")])
return ['我是一段普通的文字'.encode('utf-8')]
@route('/info.html')
def show_info(start_response):
return load_template('/info.html', start_response, name='张三', age=18)
def application(environ, start_response):
file_name = environ.get('PATH_INFO')
try:
return g_url_route[file_name](start_response)
except Exception:
start_response('404 NOT FOUND', [('Content-Type', 'text/html;charset=utf-8')])
return ['对不起,界面未找到'.encode('utf-8')]
if __name__ == '__main__':
httpd = make_server('', 8000, application)
print("Serving HTTP on port 8000...")
httpd.serve_forever()
requests模块
除了使用浏览器给服务器发送请求以外,我们还可以使用第三方模块requests用代码来给服务器发送器请求,并获取结果。
url = 'https://www.apiopen.top/satinApi'
params = {'type': 1, 'page': 2}
response = requests.get(url, params)
print(response)
# 方法二: 只能用于get请求
url = 'https://www.apiopen.top/satinApi?type=1&page=1'
response = requests.get(url)
# print(response)
# 2.获取请求结果
print(response.headers)
# 2)响应体(数据)
# a.获取二进制对应的原数据(数据本身是图片、压缩文件、视频等文件数据)
content = response.content
print(type(content))
# b.获取字符类型的数据
text = response.text
print(type(text))
# c.获取json数据(json转换成python对应的数据)
json = response.json()
print(type(json))
print(json)
根据请求路径返回不同内容
from wsgiref.simple_server import make_server
def demo_app(environ, start_response):
path = environ['PATH_INFO']
# 状态码: RESTFUL ==> 前后端分离
# 2XX: 请求响应成功
# 3XX: 重定向
# 4XX: 客户端的错误。 404 客户端访问了一个不存在的地址 405:请求方式不被允许
# 5XX: 服务器的错误。
status_code = '200 OK' # 默认状态码是 200
if path == '/':
response = '欢迎来到我的首页'
elif path == '/test':
response = '欢迎阿里到test页面'
elif path == '/demo':
response = '欢迎来到demo页面'
else:
status_code = '404 Not Found' # 如果页面没有配置,返回404
response = '页面走丢了'
start_response(status_code, [('Content-Type', 'text/html;charset=utf8')])
return [response.encode('utf8')]
if __name__ == '__main__':
httpd = make_server('', 8080, demo_app)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
httpd.serve_forever()
返回不同的类型
import json
from wsgiref.simple_server import make_server
def demo_app(environ, start_response):
path = environ['PATH_INFO']
# print(environ.get('QUERY_STRING')) # QUERY_STRING ==> 获取到客户端GET请求方式传递的参数
# POST 请求数据的方式后面再说
status_code = '200 OK'
if path == '/':
response = '欢迎来到我的首页'
elif path == '/test':
response = json.dumps({'name': 'zhangsan', 'age': 18})
elif path == '/demo':
with open('pages/xxxx.txt', 'r', encoding='utf8') as file:
response = file.read()
elif path == '/hello':
with open('pages/hello.html', 'r', encoding='utf8') as file:
response = file.read()
elif path == '/info':
# 查询数据库,获取到用户名
name = 'jack'
with open('pages/info.html', 'r', encoding='utf8') as file:
# '{username}, 欢迎回来'.format(username=name)
# flask django 模板,渲染引擎
response = file.read().format(username=name, age=18, gender='男')
else:
status_code = '404 Not Found'
response = '页面走丢了'
start_response(status_code, [('Content-Type', 'text/html;charset=utf8')])
return [response.encode('utf8')]
if __name__ == '__main__':
httpd = make_server('', 8080, demo_app)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
httpd.serve_forever()
















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











