










引言
模式识别是一门基于数据的学科,因此所有的模式识别问题都会面临的同一个问题就是数据的随机性问题。模式识别中每个方法的实现都是基于一个特定的数据样本集的,但是这个样本集只是所有可能的样本中的一次随机抽样,毕竟在我们的生活实际中存在着万物众生,多到我们数也数不清,甚至计算机都无法统计的清,而我们搜集到的充其量只是其中很小很小的一部分,这也是为什么机器学习中缺少的只是数据,只要有足够多的学习数据,就一定能取得惊人的结果,因此模式识别和机器学习中的很多方法的实现结果都无疑会受到这种随机性的影响,我们训练得到的分类器也因此具有偶然性,尤其是样本不足够多时更为明显。
对于决策树而言,其树的生长是采用的贪心算法,只考虑当前局部的最优,因此其受这种随机性影响会更加严重,这也是为什么有的决策树泛化能力那么差的原因。
针对这种随机性的影响,最早在统计学中有人提出了一种叫做”自举(Bootstrap)“的策略,基本思想是对现有样本进行重复采样而产生多个样本子集,通过这种多次重复采样来模拟数据的随机性,然后在最后的输出结果中加进去这种随机性的影响。随后有人把这种自举的思想运用到了模式识别中,衍生出了一系列的解决方法,像随机森林、Bagging、Adaboost等,这篇博客就来学习下什么是随机森林。
基本思想
随机森林是以决策树为基础的,从其名字”森林“俩字可以看出肯定有很多个什么鬼组成的一片茂密的大森林啊,那到底是什么鬼捏,其实就是决策树;随机森林其实就是建立很多个决策树,组建成决策树”森林“,然后通过对多个决策树投票来进行决策,通常决策为投票最多的。随机森林跟C4.5算法一样,不光可以处理离散数值特征,而且可以处理连续数值特征,这是ID3算法所不具备的。
具体做法
1)根据实际需要,得出需要构造的决策树数目T;
2)首先对样本数据进行自举重采样,生成多个样本子集;什么是自举重采样,就是高中学概率问题的时候接触到最多的有放回问题,即每次从N个样本中有放回的随机取出一个,这样取N次,最后会得到N个样本,当然有可能取到重复样本,但是没关系;
3)随机抽取用来构造决策树的特征:每次从所有候选特征中随机的选出m个特征,作为当前节点下决策用的备选特征,然后根据比较信息增益的方法选取出可以最好划分训练样本的特征;
4)利用上述已经选好的代表性特征,将每个重采样的样本集作为训练样本构造决策树;
5)得到事先给定的决策树数目的众多决策树后,分别对每棵树的输出结果进行投票,将票数最多的类决策为随机森林最后的决策;
上述原理如图所示,一目了然:
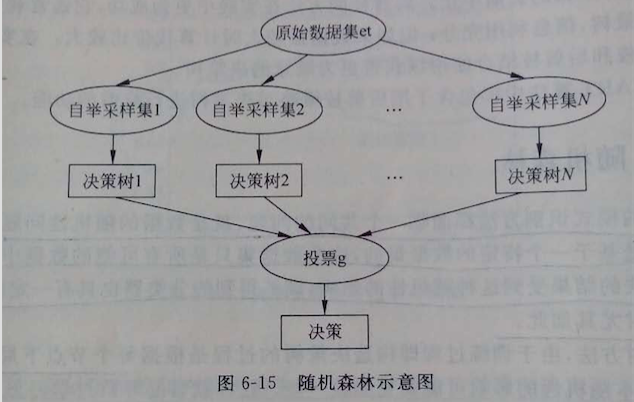
可以发现,在上面的步骤中,随机森林做了两方面的采样:1)对训练样本采样;2)对特征进行采样,因此保证了每一颗树之间的独立性,彼此不相关,从而使得最后的投票结果是无偏的。另外上面实现过程中涉及到两个人为给定的参数:1)树的个数;2)备选的特征数;这两个参数在实际应用中一定要结合实际和经验来选取,通常来说,树的个数最好多一些,毕竟多一些人投票就公平些,而对备选的特征数,不宜太多不宜太少,可设为总的候选特征数的平方根;
优缺点分析
优点:
1)可以处理离散特征和连续特征;
2)不会出现过学习的现象;
3)减少样本偶然性,结果无偏;
4)在样本数据分布严重不均的情况下,仍然能保障结果的可靠性;
5)可以处理高维数据;
6)训练和预测速度快;
7)训练完后,会明确给出那些特征具有高辨别力;
8)简单高效;
缺点:
1)需要人为确定特征数,对于没经验者不太好拿捏;
2)尽管树之间的独立性可以保证不会出现过学习,但是当数据中夹杂噪声的情况下不能保证;
3)会被有多个候选特征属性的样本数据误导;















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









