






优化器是深度学习领域的重要组成模块之一,执行深度学习任务时采用不同的优化器会产生截然不同的效果。这也是研究者们不遗余力「炼丹」的原因之一。常见的优化算法包括梯度下降(变体 BGD、SGD 和 MBGD)、Adagrad、Adam、Momentum 等,如此繁多的优化器应该如何做出抉择呢?
为机器学习项目选择好的优化器不是一项容易的任务。流行的深度学习库(如 PyTorch 或 TensorFLow)提供了多种优化器选择,它们各有优缺点。并且,选择不合适的优化器可能会对机器学习项目产生很大的负面影响。这使得选择优化器成为构建、测试和部署机器学习模型过程中的关键一环。
选择优化器的问题在于没有一个可以解决所有问题的单一优化器。实际上,优化器的性能高度依赖于设置。所以根本问题是:「哪种优化器最适合自身项目的特点?」
下文就围绕这个问题分两部分展开,第一部分简要介绍常用的优化器,第二部分讲述「三步选择法」,帮助用户为自己的机器学习项目挑选出最佳优化器。
一. 常用优化器
深度学习中几乎所有流行的优化器都是基于梯度下降。这意味着它们要反复估计给定损失函数 L 的斜率,并沿着相反的方向移动参数(因此向下移动至假定的全局最小值)。这种优化器最简单的示例是自 20 世纪 50 年代以来一直使用的随机梯度下降(SGD)算法。21 世纪前 10 年,自适应梯度法(如 AdaGrad 或 Adam)变得越来越流行。
但最近的趋势表明,部分研究转而使用先前的 SGD,而非自适应梯度法。此外,当前深度学习中的挑战带来了新的 SGD 变体,例如 LARS、LAMB[6][7]。例如谷歌研究院在其最近的论文中使用 LARS 训练一种强大的自监督模型[8]。
本文中用 w 代表参数,g 代表梯度,α为每个优化器的全局学习率,t 代表时间步(time step)。
1.随机梯度下降(SGD)算法
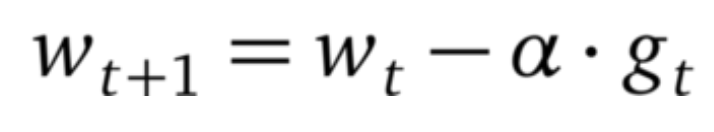
在随机梯度下降算法(SGD)中,优化器基于小批量估计梯度下降最快的方向,并朝该方向迈出一步。由于步长固定,因此 SGD 可能很快停滞在平稳区(plateaus)或者局部最小值上。
2.带动量的SGD
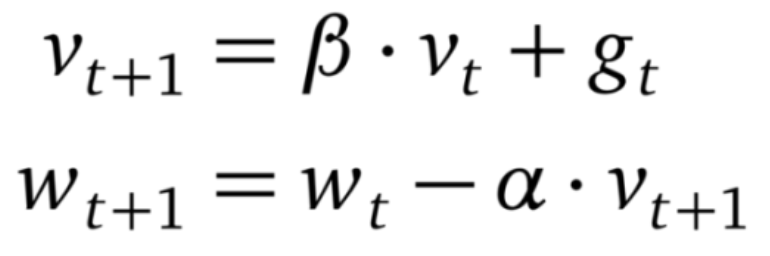
其中β<1。当带有动量时,SGD 会在连续下降的方向上加速(这就是该方法被称为「重球法」的原因)。这种加速有助于模型逃脱平稳区,使其不易陷入局部极小值。
3.AdaGrad
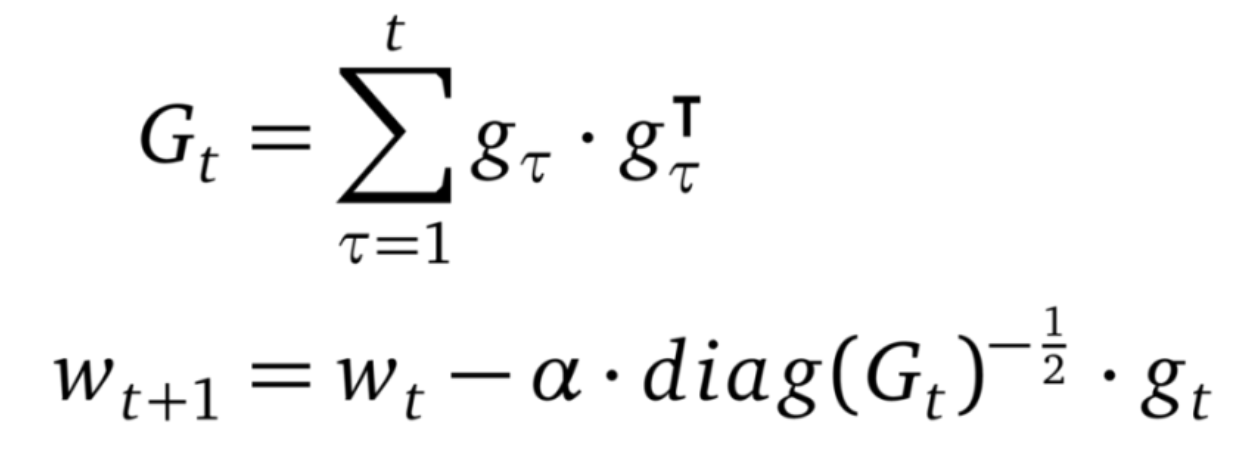
AdaGrad 是首批成功利用自适应学习率的方法之一。AdaGrad 基于平方梯度之和的倒数的平方根来缩放每个参数的学习率。该过程将稀疏梯度方向放大,以允许在这些方向上进行较大调整。结果是在具有稀疏特征的场景中,AdaGrad 能够更快地收敛。
4.RMSprop
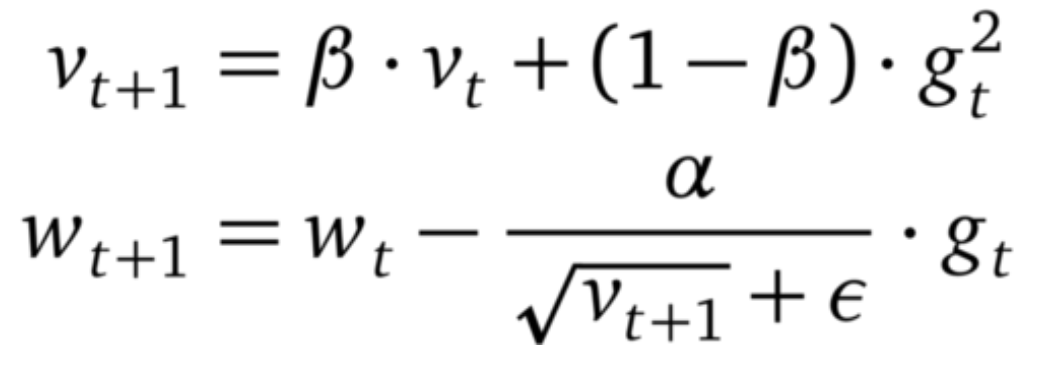
RMSprop 是一个未发布的优化器,但在最近几年中已被过度使用。其理念类似于 AdaGrad,但是梯度的重新缩放不太积极:用平方梯度的移动均值替代平方梯度的总和。RMSprop 通常与动量一起使用,可以理解为 Rprop 对小批量设置的适应。
5.Adam
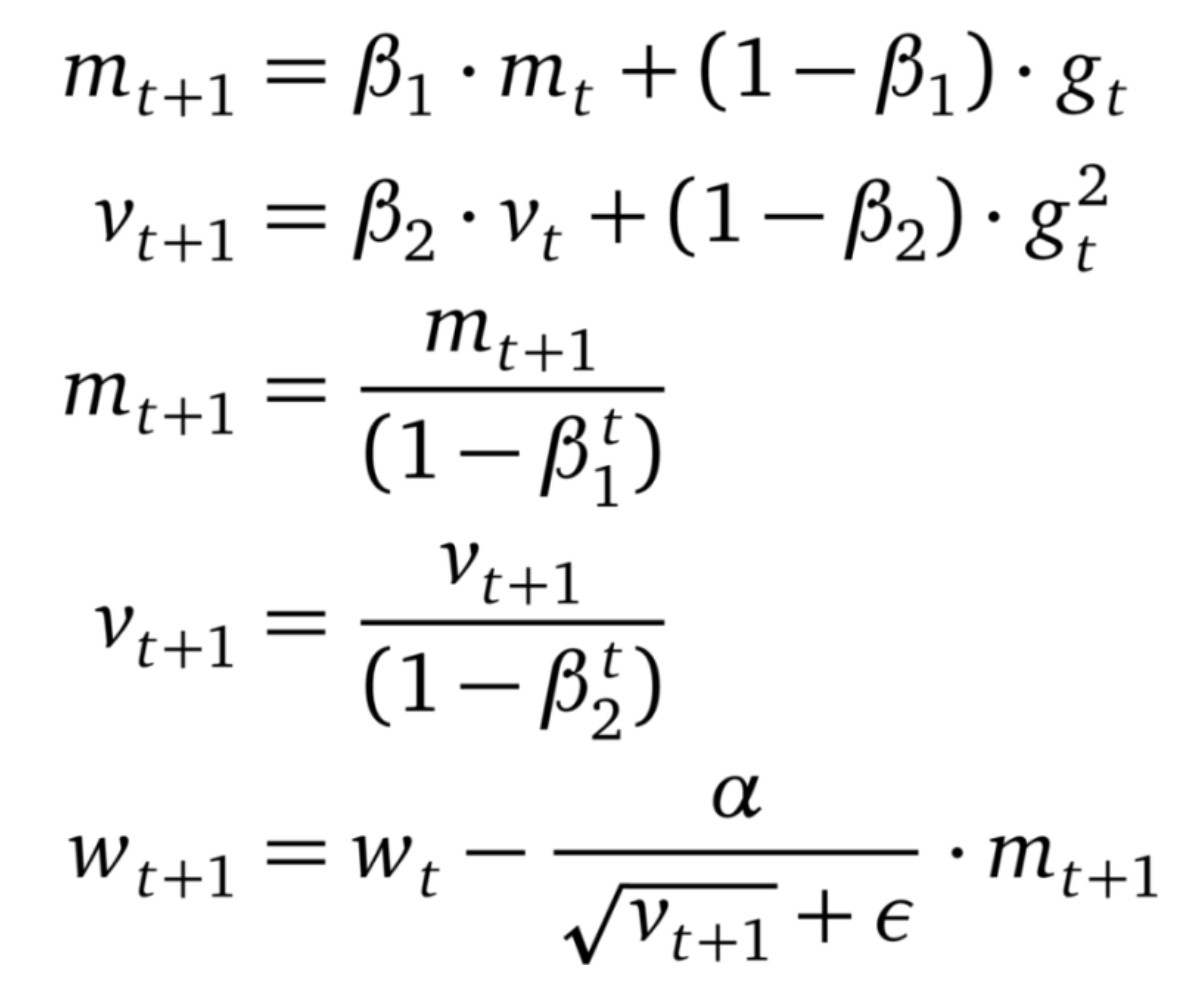
Adam 将 AdaGrad、RMSprop 和动量方法结合到一起。下一步的方向由梯度的移动平均值决定,步长大小由全局步长大小设置上限。此外,类似于 RMSprop,Adam 对梯度的每个维度进行重新缩放。Adam 和 RMSprop(或 AdaGrad)之间一个主要区别是对瞬时估计 m 和 v 的零偏差进行了矫正。Adam 以少量超参数微调就能获得良好的性能著称。
6.AdamW
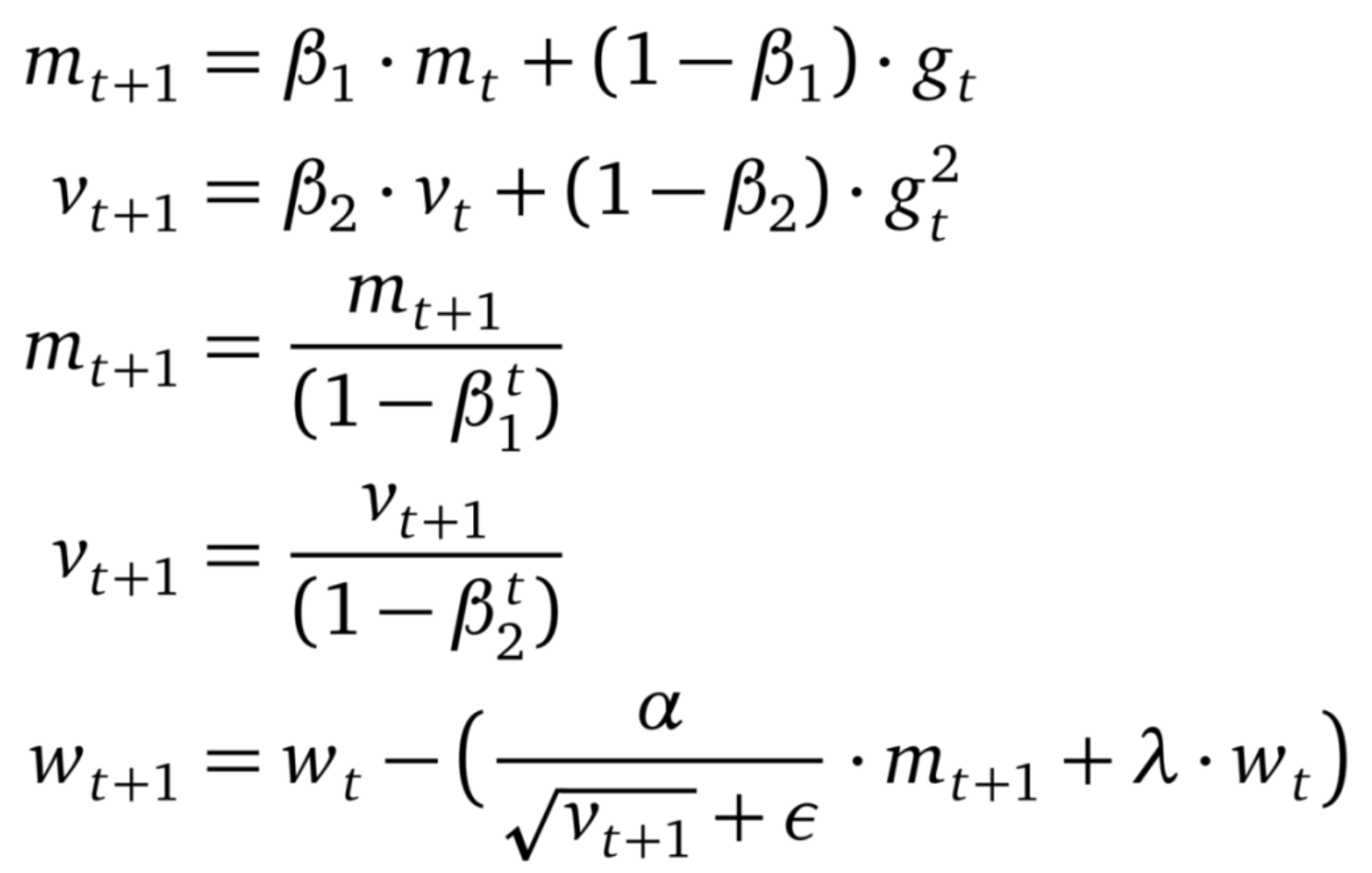
Loshchilov 和 Hutter 在自适应梯度方法中确定了 L2 正则化和权重下降的不等式,并假设这种不等式限制了 Adam 的性能。然后,他们提出将权重衰减与学习率解耦。实验结果表明 AdamW 比 Adam(利用动量缩小与 SGD 的差距)有更好的泛化性能,并且对于 AdamW 而言,最优超参数的范围更广。
7.LARS
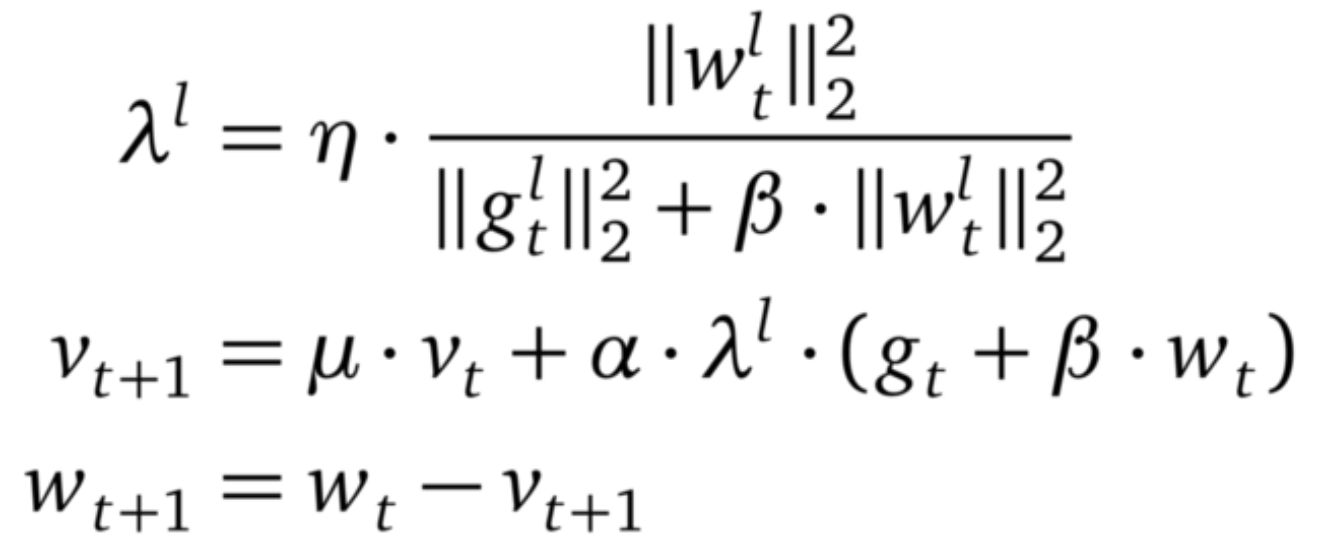
LARS 是 SGD 的有动量扩展,可以适应每层的学习率。LARS 最近在研究界引起了关注。这是由于可用数据的稳定增长,机器学习的分布式训练也变得越来越流行。这使得批处理大小开始增长,但又会导致训练变得不稳定。有研究者(Yang et al)认为这些不稳定性源于某些层的梯度标准和权重标准之间的不平衡。因此他们提出了一种优化器,该优化器基于「信任」参数η<1 和该层梯度的反范数来重新调整每层的学习率。
二. 如何选择合适的优化器?
如上所述,为机器学习问题选择合适的优化器可能非常困难。更具体地说,没有万能的解决方案,只能根据特定问题选择合适的优化器。但在选择优化其之前应该问自己以下 3 个问题:
类似的数据集和任务的 SOTA 结果是什么?
使用了哪些优化器?
[图片上传中...(优化器性能对比.png-96ee76-1677241715730-0)]
为什么使用这些优化器?
如果您使用的是新型机器学习方法,那么可能存在一篇或多篇涵盖类似问题或处理了类似数据的优秀论文。通常,论文作者会进行广泛的交叉验证,并且给出最成功的配置。读者可以尝试理解他们选择那些优化器的原因。
例如:假设你想训练生成对抗网络(GAN),以对一组图像执行超分辨率。经过一番研究后,你偶然发现了一篇论文 [12],研究人员使用 Adam 优化器解决了完全相同的问题。威尔逊等人[2] 认为训练 GAN 并不应该重点关注优化问题,并且 Adam 可能非常适合这种情况。所以在这种情况下,Adam 是不错的优化器选择。
此外,你的数据集中是否存在可以发挥某些优化器优势的特性?如果是这样,则需要考虑优化器的选择问题。
下表 1 概述了几种优化器的优缺点。读者可以尝试找到与数据集特征、训练设置和项目目标相匹配的优化器。某些优化器在具有稀疏特征的数据上表现出色,而有一些将模型应用于先前未见过的数据时可能会表现更好。一些优化器在大批处理量下可以很好地工作,而另一些优化器会在泛化不佳的情况下收敛到极小的最小值。

举例而言:如果你需要将用户给出的反馈分类成正面和负面反馈,考虑使用词袋模型(bag-of-words)作为机器学习模型的输入特征。由于这些特征可能非常稀疏,所以决定采用自适应梯度方法。但是具体选择哪一种优化器呢?参考上表 1,你会发现 AdaGrad 具有自适应梯度方法中最少的可调参数。在项目时间有限的情况下,可能就会选择 AdaGrad 作为优化器。
最后需要考虑的问题:该项目有哪些资源?项目可用资源也会影响优化器的选择。计算限制或内存限制以及项目时间范围都会影响优化器的选择范围。
如上表 1 所示,可以看到每个优化器有不同的内存要求和可调参数数量。此信息可以帮助你估计项目设置是否可以支持优化器的所需资源。
举例而言:你正在业余时间进行一个项目,想在家用计算机的图像数据集上训练一个自监督的模型(如 SimCLR)。对于 SimCLR 之类的模型,性能会随着批处理大小的增加而提高。因此你想尽可能多地节省内存,以便进行大批量的训练。选择没有动量的简单随机梯度下降作为优化器,因为与其他优化器相比,它需要最少的额外内存来存储状态。

















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









