







 FixMatch是一种结合了一致性正则化和伪标记技术的半监督学习算法。它通过对无标签数据进行增强并利用模型预测结果作为伪标签来指导模型训练。该算法包括四个步骤:数据增强、伪标签生成、损失计算及模型更新。
FixMatch是一种结合了一致性正则化和伪标记技术的半监督学习算法。它通过对无标签数据进行增强并利用模型预测结果作为伪标签来指导模型训练。该算法包括四个步骤:数据增强、伪标签生成、损失计算及模型更新。
FixMatch
本博客仅做算法流程疏导,具体细节请参见原文
原文
Github代码
解读
FixMatch算法抓住了半监督算法的两个重要观点,第一个是一致性正则化,第二个是伪标记。一致性正则化在MixMatch中已经介绍过了,在此不再赘述。伪标记是一种常用的半监督算法。
伪标记
伪标记(pseudo label)其实算最早的一类半监督算法,代表算法self-training。简单地说就是通过训练的模型对无标记样本打标签,这个标签有对有错,通过一些方法筛选标签后,选择一部分无标记样本和模型打的标签一起送入模型继续训练。伪标记的方法最大问题在于,如何保证伪标记的正确性。因为当模型打的标签提供了较多的错误信息时,会使模型的训练结果更劣。一般常见的筛选方式是将模型输出的预测结果( S o f t m a x Softmax Softmax之后)进行阈值判断,其 a r g m a x argmax argmax的概率大于阈值,才认为是有效标记,否则将此无标记样本丢弃。
整体算法
FixMatch算法并不复杂,结合一致性正则化和伪标记两种算法。由其论文中的流程图就可以很好的理解。
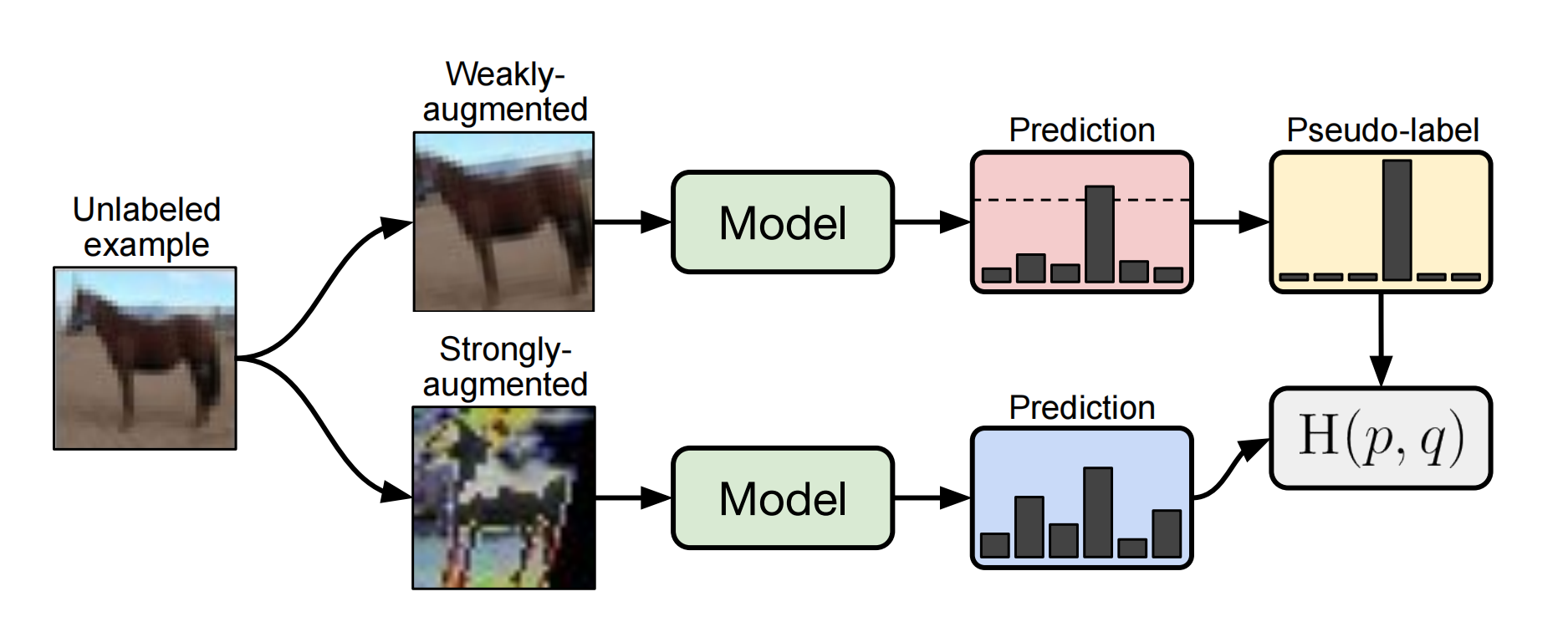
对于有标记样本,进行正常的监督学习,损失函数为 C r o s s E n t r o p y L o s s CrossEntropyLoss CrossEntropyLoss,得到 L s L_s Ls。其公式表达如下:
L s = 1 B ∑ b = 1 B H ( p b , p m ( y ∣ α ( x b ) ) ) L_s=\frac{1}{B}\sum^B_{b=1}H(p_b,p_m(y|\alpha(x_b))) Ls=B1∑b=1BH(pb,pm(y∣α(xb)))
对于无标记样本,参照上图,共四步。
第一步,先对无标记样本进行扩增(Augment),扩增分为强扩增和弱扩增,弱扩增使用标准的旋转和移位;强扩增使用RandAugment和CTAugment两种算法。
第二步,对扩增后的样本进行预测。对于弱扩增的样本,输出的预测结果( S o f t m a x Softmax Softmax之后的)最高预测概率(即 a r g m a x argmax argmax的结果)大于阈值(图中的虚线),则认为是有效的样本,将其预测结果作为标签(这就是pseudo label)。
第三步:对强扩增的样本,输出的预测结果和对应弱标记样本得到的标签做 C r o s s E n t r o p y L o s s CrossEntropyLoss CrossEntropyLoss,得到损失函数 L u L_u Lu。其公式表达为:
L u = 1 μ B ∑ b = 1 μ B 1 ( m a x ( q b ) ≥ τ ) H ( q b ^ , p m ( y ∣ A ( u b ) ) ) L_u=\frac{1}{\mu B}\sum^{\mu B}_{b=1}\mathcal{1}(max(q_b)\geq \tau )H(\hat{q_b},p_m(y|\mathcal{A}(u_b))) Lu=μB1∑b=1μB1(max(qb)≥τ)H(qb^,pm(y∣A(ub)))
简而言之就是选择 m a x ( q b ) ≥ τ max(q_b)\geq \tau max(qb)≥τ的 H ( q b ^ , p m ( y ∣ A ( u b ) ) H(\hat{q_b},p_m(y|\mathcal{A}(u_b)) H(qb^,pm(y∣A(ub))作为 L u L_u Lu的组成成分,参与反向梯度传播更新。
第四步:最终损失函数为 L o s s = L s + α L u Loss = L_s+\alpha L_u Loss=Ls+αLu, α \alpha α是超参数。
对 L o s s Loss Loss反向梯度传播完成整个算法模型更新。
核心代码解读
这里读取一个batch的操作,和前一篇MixMatch的代码实现相同,为了读取指定次数的batch,而不通过Dataloader。
for batch_idx in range(args.eval_step):
try:
inputs_x, targets_x = labeled_iter.next()
except:
if args.world_size > 1:
labeled_epoch += 1
labeled_trainloader.sampler.set_epoch(labeled_epoch)
labeled_iter = iter(labeled_trainloader)
inputs_x, targets_x = labeled_iter.next()
try:
(inputs_u_w, inputs_u_s), _ = unlabeled_iter.next()
except:
if args.world_size > 1:
unlabeled_epoch += 1
unlabeled_trainloader.sampler.set_epoch(unlabeled_epoch)
unlabeled_iter = iter(unlabeled_trainloader)
(inputs_u_w, inputs_u_s), _ = unlabeled_iter.next()
得到strong_augment样本和weak_augment样本,分别为logits_u_s和logits_u_w。
logits = model(inputs)
logits = de_interleave(logits, 2*args.mu+1)
logits_x = logits[:batch_size]
logits_u_w, logits_u_s = logits[batch_size:].chunk(2)
对有标记样本做 C r o s s E n t r o p y L o s s CrossEntropyLoss CrossEntropyLoss
Lx = F.cross_entropy(logits_x, targets_x, reduction='mean')
通过weak_augment样本计算伪标记pseudo label和mask,其中,mask用来筛选哪些样本最大预测概率超过阈值,可以拿来使用,哪些不能使用
pseudo_label = torch.softmax(logits_u_w.detach()/args.T, dim=-1)
max_probs, targets_u = torch.max(pseudo_label, dim=-1)
mask = max_probs.ge(args.threshold).float()
计算无标记样本的损失函数 L u L_u Lu,其中通过mask进行样本筛选
Lu = (F.cross_entropy(logits_u_s, targets_u, reduction='none') * mask).mean()
完整损失函数如下
loss = Lx + args.lambda_u * Lu
反向梯度更新,完成!~


















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









