







曾经,我学习的时候一直希望自己能够把控全局,希望能够有清晰的思路,于是我就花费大量时间精力来维护一个学习系统,然而收效甚微,甚至起反作用,我根本搞不懂该怎么做,所以总是做错,所以我决定不再过分苛求全局最优,这样根本是做不到。针对性的解决问题才是王道,不要浪费时间在无意义的事情上
话不多说,直接练习代码,注意,这是对深度学习的一个准备工作,因为前面已经学习了强化学习,所以要想会深度强化学习,得对深度学习的知识有所准备
分类
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import os
# torch.manual_seed(1) # reproducible
# make fake data
log_dirs="logs/classi"
writer=SummaryWriter(log_dir=log_dirs)
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
# The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
# x, y = Variable(x), Variable(y)
# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
# plt.show()
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.out = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2) # define the network
print(net) # net architecture
optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hotted
plt.ion() # something about plotting
for t in range(100):
out = net(x) # input x and predict based on x
loss = loss_func(out, y) # must be (1. nn output, 2. target), the target label is NOT one-hotted
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
writer.add_scalar("Loss",loss)
if t % 2 == 0:
# plot and show learning process
plt.cla()
prediction = torch.max(out, 1)[1]
pred_y = prediction.data.numpy()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
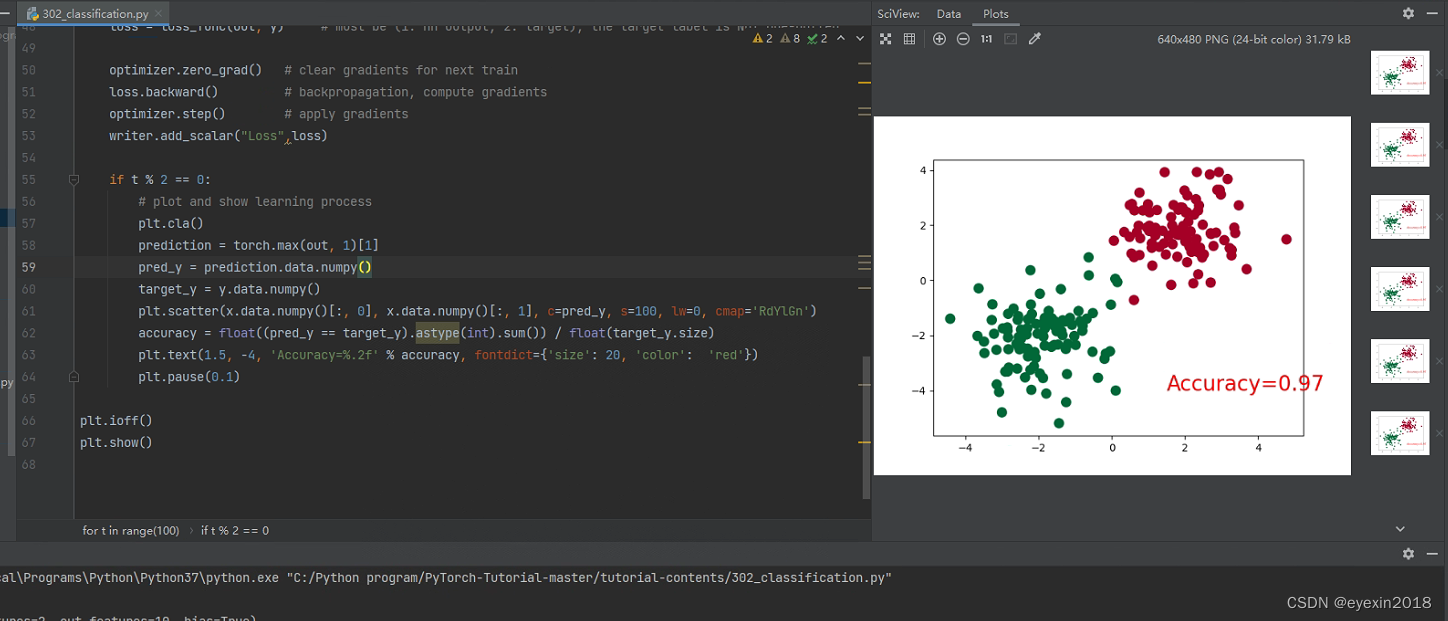
也添加了tensorboard,但是怎么感觉tensorboard对pytorch的支撑更弱一点,看不到网络结构。但是我查看了后发现并不是支持不到位,而是我代码没有到位,不过这也还是体现了它不如tensorboard的完美衔接,它还需要一个一个往里面添加,而TensorFlow只需要用回调函数即可。
将网络的结构图写入日志文件:在创建网络对象后,使用writer.add_graph()方法将网络的结构图写入日志文件。
writer.add_graph(model, input_to_model)
其中,model是你创建的网络对象,input_to_model是一个输入样本,用于确定网络的输入尺寸。
代码一定要多写几遍,多写几遍,多写几遍
已经多次提醒了,因为不练的话,到实战你只能抓瞎,啥都不会,看是看不会的,为啥印度的三哥在IT行业那么强,产生了许多硅谷CEO,人家从小就被代码,练代码,人家一直在实战啊!所以实战兴*,空看误*
下面是一个快速构建神经网络的例子
import torch
import torch.nn.functional as F
#这种是自定义的神经网络,自己写好类,然后用的时候直接新建对象即可
class Net(torch.nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net, self).__init__()
self.hidden=torch.nn.Linear(n_feature,n_hidden)
self.output=torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x=F.relu(self.hidden(x))
x=self.predict(x)
return x
#新建网络对象
net1=Net(1,10,1)
#另一种方式,借助pytorch中的函数直接定义,无需建类
net2=torch.nn.Sequential(torch.nn.Linear(1,10),torch.nn.ReLU(),torch.nn.Linear(10,1))
print(net1)
print(net2)
网络结构
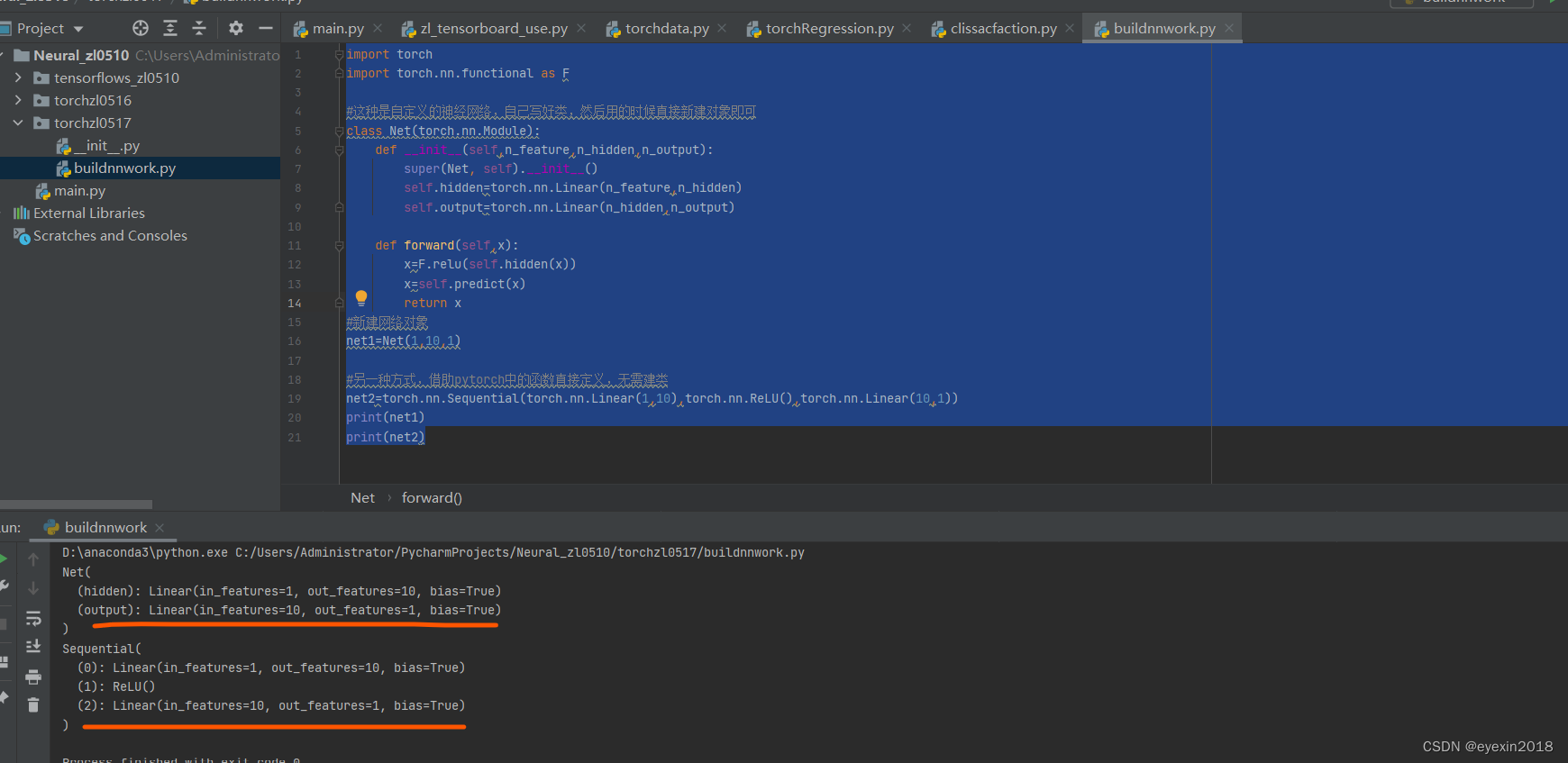
我希望工作的代码是可以帮助到后人快速入手和进步的,而不是充满问题的代码,增加学习难度,所以最怕的就是一些学习材料你无法复现,这就成了学习过程中的阻碍














 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









