








此篇为翻译GENSIM官网中有关FastText model的内容。我用自己moke的数据代替原文中的语料做模型训练例子。
之前文章介绍过word2vec模型有一个缺陷就是对于词库外的词不能给出向量表示,但是FastText模型可以很好的解决这个问题。
FastText模型是Facebook开发的一个向量表征模型,它既支持直接调用,也可以根据自己的业务场景需求自己训练。下面介绍下FastText模型的几种快速启动使用方法。
方法1: 引用已有词库,快速启动训练
from gensim.models import FastText
from gensim.test.utils import common_texts # some example sentences
print(common_texts[:5])
print(len(common_texts))
# 快速启动
model = FastText(vector_size=8, window=3, min_count=1) # instantiate
model.build_vocab(corpus_iterable=common_texts)
model.train(corpus_iterable=common_texts, total_examples=len(common_texts), epochs=10)
print("computer 的表示:", model.wv['computer'])
# 快速启动方法
model2 = FastText(vector_size=8, window=3, min_count=1, sentences=common_texts, epochs=10)
print("computer 的表示:", model2.wv['computer'])
import numpy as np
np.allclose(model.wv['computer'], model2.wv['computer'])
方法2: 训练自己的语料文件
# 示例:假设有一个大规模的语料库文件
corpus_file = 'large_corpus_sku_name.txt'
# 定义一个函数来读取语料库文件
def read_corpus(file_path):
lines = []
with open(file_path, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
lines.append(line.replace('"','').strip().split(',')) # 每行按空格分割分好词
return lines
corpus = read_corpus(corpus_file)
corpus[5:15]
# 模型训练
model = FastText(vector_size=20, window=3, min_count=1) # instantiate
model.build_vocab(corpus_iterable=corpus)
model.train(corpus_iterable=corpus, total_examples=len(corpus), epochs=10)
# #或者
# model2 = FastText(vector_size=20, window=3, min_count=1, sentences=common_texts, epochs=10)
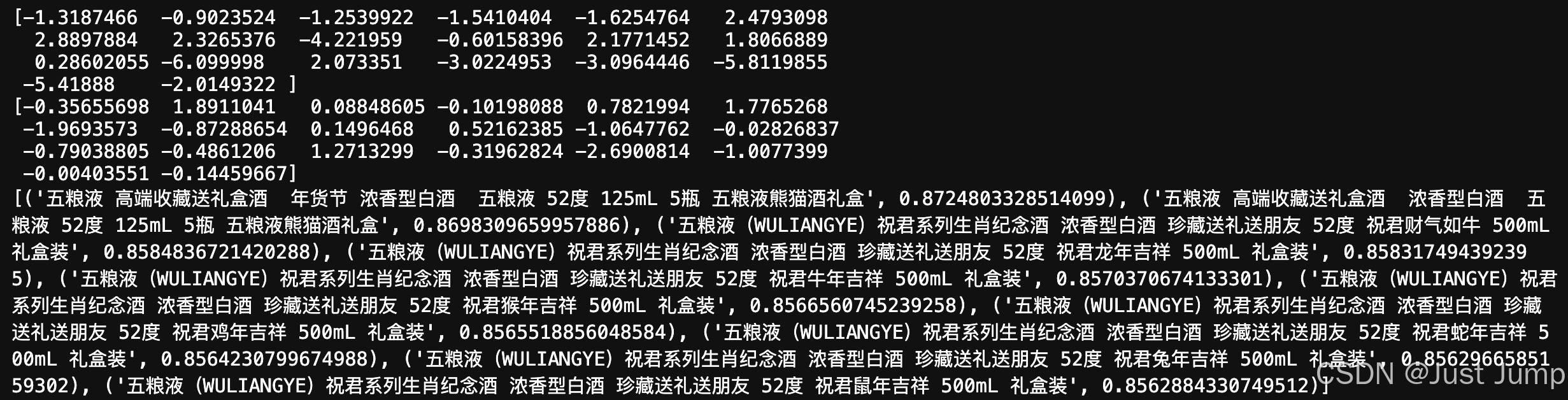
print(model.wv['茅台贵州茅台53度飞天茅台500ml*1瓶酱香型白酒单瓶装'])
print(model.wv['【浓香】五粮液甲辰龙年纪念酒(5瓶装)'])
print(model.wv.most_similar('【浓香】五粮液甲辰龙年纪念酒(5瓶装)', topn=10))
![]()
方法3: 对于数据集较大的语料文件,streaming流式处理
# 如果数据集量级较大,建议是用streaming流式处理。 corpus_file的存储格式 每行是按空格做好分割的词
from gensim.test.utils import datapath
corpus_file = datapath('/home/gao/酒类商品Embedding/large_corpus_sku_name.txt') # absolute path to corpus
model3 = FastText(vector_size=20, window=3, min_count=1)
model3.build_vocab(corpus_file=corpus_file) # scan over corpus to build the vocabulary 先扫描词库
total_words = model3.corpus_total_words # number of words in the corpus,需要提前计算
model3.train(corpus_file=corpus_file, total_words=total_words, epochs=5)
print(model3.wv['茅台贵州茅台53度飞天茅台500ml*1瓶酱香型白酒单瓶装'])
print(model3.wv['【浓香】五粮液甲辰龙年纪念酒(5瓶装)'])
print(model3.wv.most_similar('【浓香】五粮液甲辰龙年纪念酒(5瓶装)', topn=10))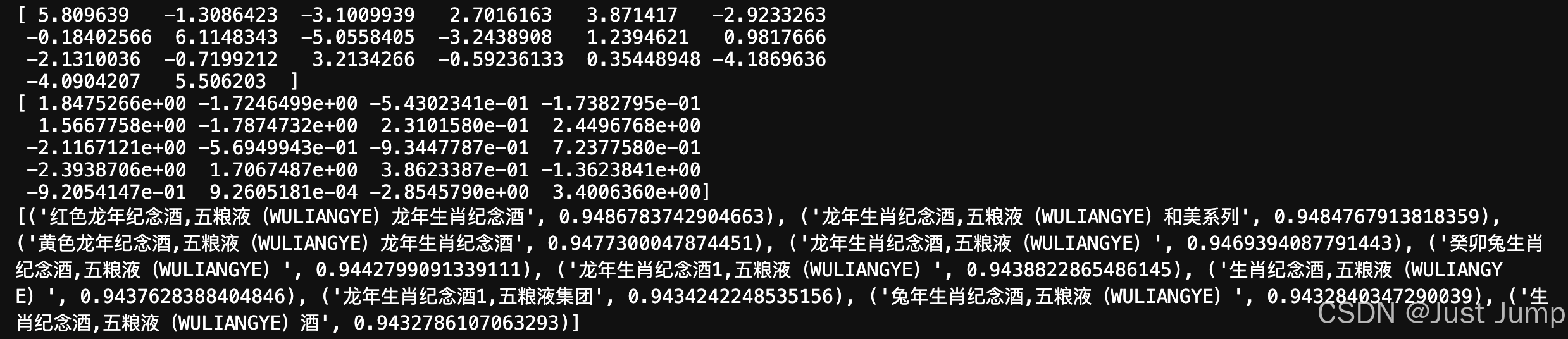
方法4: 迭代训练
# 使用自己准备的语料文件,进行迭代训练
from gensim.utils import tokenize
from gensim import utils
class MyIter:
def __iter__(self):
path = 'large_corpus_sku_name.txt'
with utils.open(path, 'r', encoding='utf-8') as fin:
for line in fin:
new_line = ' '.join(line.replace('"','').replace(' ','').strip().split(',')) # 替换分隔符。逗号改成空格
yield list(tokenize(new_line))
model4 = FastText(vector_size=20, window=3, min_count=2)
model4.build_vocab(corpus_iterable=MyIter())
total_examples = model4.corpus_count
model4.train(corpus_iterable=MyIter(), total_examples=total_examples, epochs=5)
print(model4.wv['茅台贵州茅台53度飞天茅台500ml*1瓶酱香型白酒单瓶装'])
print(model4.wv['【浓香】五粮液甲辰龙年纪念酒(5瓶装)'])
print(model4.wv.most_similar('【浓香】五粮液甲辰龙年纪念酒(5瓶装)', topn=10))
方法5: 在原模型上新增语料继续训练
# 在原来模型上新增语料继续训练
import numpy as np
# 原模型中没有的词向量表示
print('茅台贵州' in model4.wv.key_to_index ) # New word, currently out of vocab
old_vector = np.copy(model4.wv['茅台贵州']) # Grab the existing vector
print("old_vector: ", old_vector)
# 新的语料库
new_sentences = [
['贵州茅台', '五粮液', '酒鬼酒'],
['甲辰龙年', '癸卯兔年', '壬寅虎年'],
['贵州茅台集团', '生肖纪念酒'],
['五粮液', '生肖收藏纪念酒'],
]
# 更新语料库: build_vocab 设置 update=True
model4.build_vocab(new_sentences, update=True) # Update the vocabulary
#模型继续训练
model4.train(new_sentences, total_examples=len(new_sentences), epochs=model4.epochs)
#更新训练后的词向量表示
new_vector = model4.wv['茅台贵州']
print("new_vector: ", new_vector)
print('茅台贵州' in model.wv.key_to_index) # Word is still out of vocab
#前后两次向量表示对比
print(np.allclose(old_vector, new_vector, atol=1e-4)) # Vector has changed, model has learnt something
保存模型:
# 保存模型
from gensim.test.utils import get_tmpfile
fname = get_tmpfile("fasttext_model4.model")
model4.save(fname)
model4_new = FastText.load(fname)
print(model4_new.wv['茅台贵州茅台53度飞天茅台500ml*1瓶酱香型白酒单瓶装'])
print(model4_new.wv['【浓香】五粮液甲辰龙年纪念酒(5瓶装)'])
print(model4_new.wv.most_similar('【浓香】五粮液甲辰龙年纪念酒(5瓶装)', topn=10))
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









