







1、目的:
前文中讲到Logstash解析Json后并处理Json数组,因考虑到消息体大小(数组长度过长),在进行打印日志时,对json字符串进行压缩。
2、消息体:
测试消息体
{
"ecProvince": "北京",
"ecId": 1,
"ecName": "测试企业名称",
"mobiles": [{
"bizCode": "1",
"mobile": "10000000000"
}, {
"bizCode": "2",
"mobile": "20000000000"
}],
"type": 1
}3、压缩方法样例:
public static String gzip(String param) {
if (param == null || param.length() == 0) {
return param;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPOutputStream gzip = null;
try {
gzip = new GZIPOutputStream(out);
gzip.write(param.getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
if (gzip != null) {
try {
gzip.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return new String(Base64.encodeBase64(out.toByteArray()), StandardCharsets.UTF_8);
}压缩后消息体 :
H4sIAAAAAAAAAKtWSk0OKMovy8xLTlWyUnraM/3JrjVKOkBRzxQlK0MQwy8xFyT1bGv3i/VTn+xpfLJj1tMJvc+XbwAqy81PysxJLVayiq5WSsqscs5PASk1hMuAOAZwoFSrg6zMCFmZEbKyWB2lksoCoLBhLRcAtVNcjKIAAAA=4、Logstash实现:
logstash.conf读取本地txt文件
input
input {
file {
#type => "type_a"
start_position => "beginning"
path => ["D:/1.txt"]
}
}filter
filter{
# 使用ruby过滤器解码和解压数据
ruby {
code => '
require "base64"
require "zlib"
# 获取Base64解码后的gzip数据
gzip_data = Base64.decode64(event.get("message"))
# 解压gzip数据
decompressed_data = Zlib::GzipReader.new(StringIO.new(gzip_data)).read
# 设置解压后的新字段
event.set("decompressed_message", decompressed_data)
'
}
json {
source => "decompressed_message"
}
split {
field => "mobiles"
}
mutate {
add_field => {"field1" => "%{mobiles}"}
}
json {
source => "field1"
}
mutate {
remove_field => ["field1","mobiles","message","decompressed_message"]
}
}output
output {
stdout {
codec => rubydebug
}
}5、运行效果:
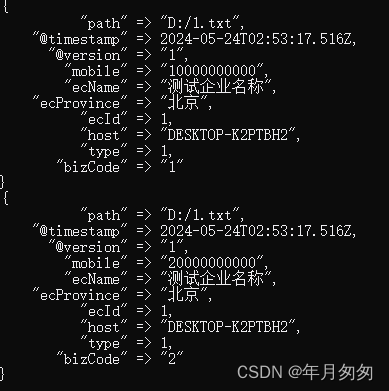
运行结果与前文拆分的结果一样,复用图片进行展示了。
以上为自己测试情况,还未用到生产环境,之后运用到生产或遇到什么问题,会在此文中进行更正。
同时也欢迎大佬指教并进行沟通。















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









