






、前期准备
- 准备工具:一台已安装飞牛系统的NAS设备(如群晖等)
- 硬件连接:确保摄像头与路由器正确连接并通电
- 账号准备:提前注册好飞牛系统账号(后续会用到)
二、安装部署(关键步骤详解)
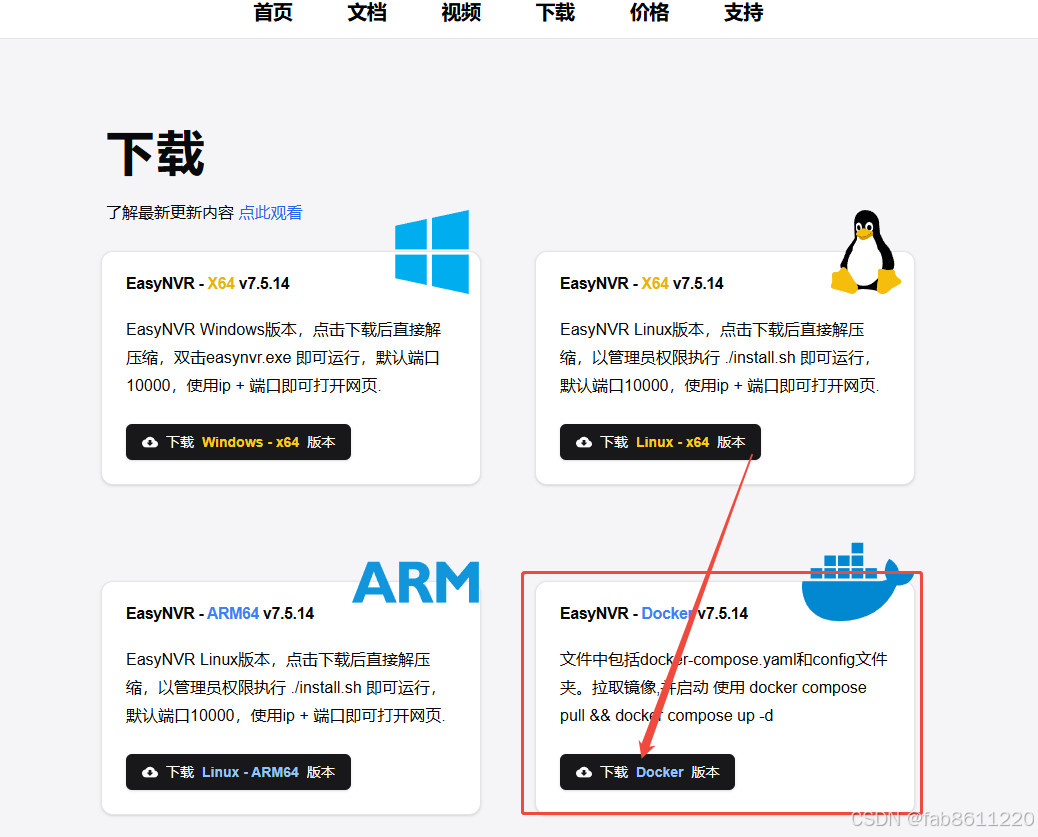
Step1:获取安装包
- 访问指定官网下载"EasynVR Docker安装包"
- https://www.easynvr.com/download.html
- 下载完成后得到一个压缩文件(约30MB)
Step2:部署Docker容器
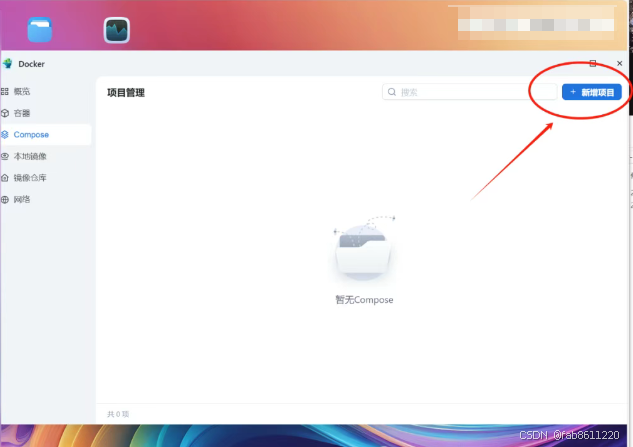
- 登录飞牛系统管理界面 → 进入"Docker"模块
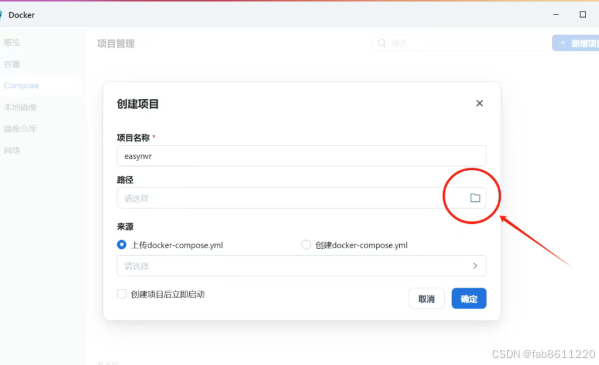
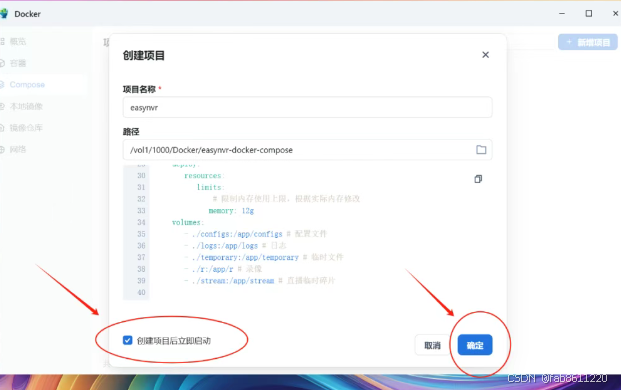
- 点击"新增项目" → 选择"Compose"模式
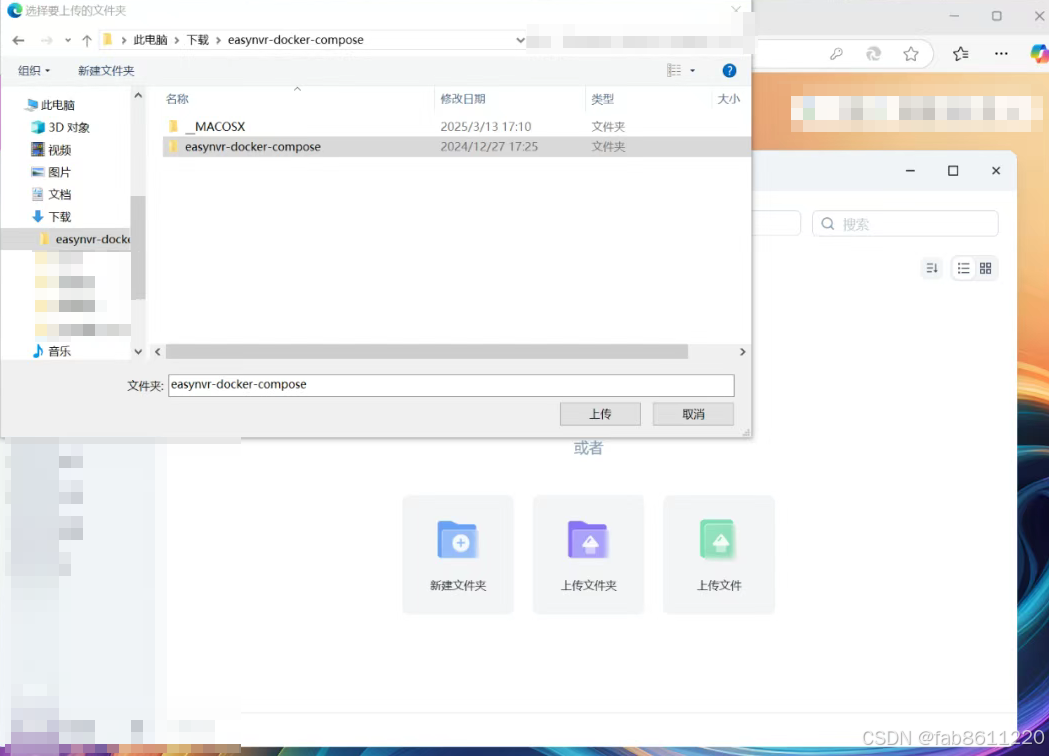
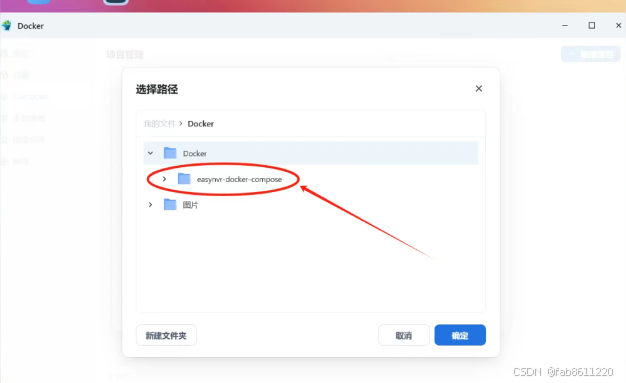
- 填写项目名称"easynvr" → 点击"路径"上传解压后的文件夹
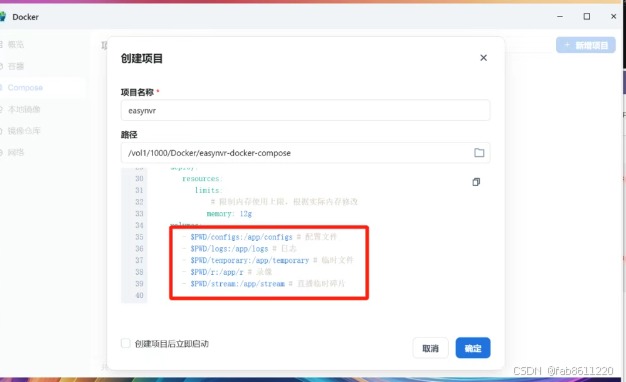
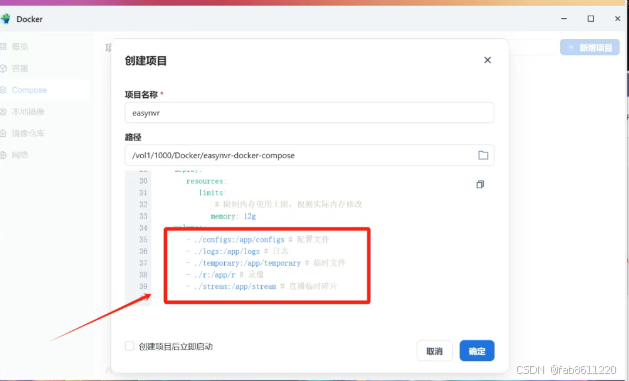
- 修改配置文件(重点!):
将原文件中的5处"pwd"替换为"."(例:原路径:pwd/configs → 修改后:./configs)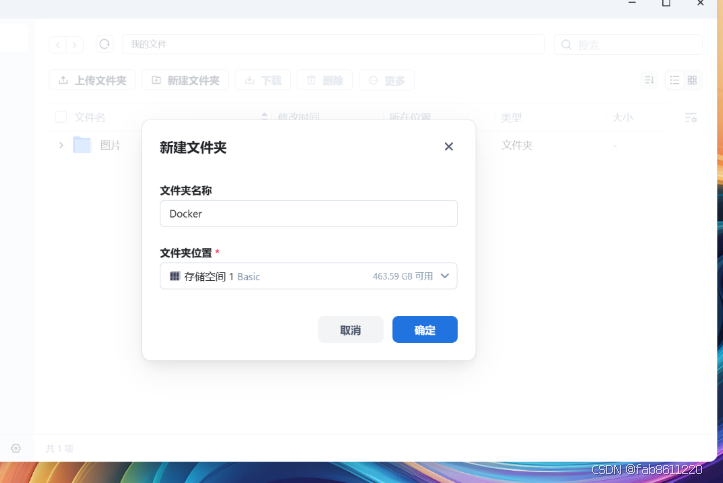
Step3:启动服务
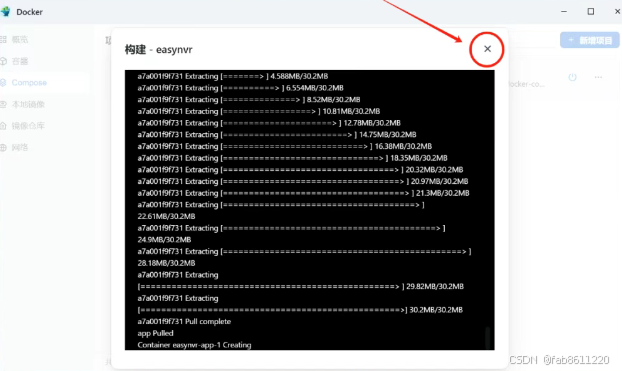
- 点击"创建项目后立即启动",等待部署完成(约需2-3分钟)
- 成功标志:界面出现绿色运行状态图标
三、设备接入配置
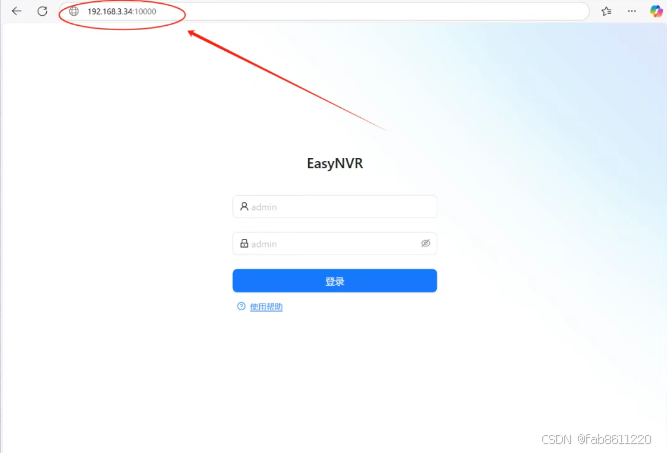
- 登录管理后台
- 地址格式:飞牛系统IP:10000(例:192.168.1.100:10000)
- 初始账号:admin/admin(首次登录需立即修改密码)添加监控设备
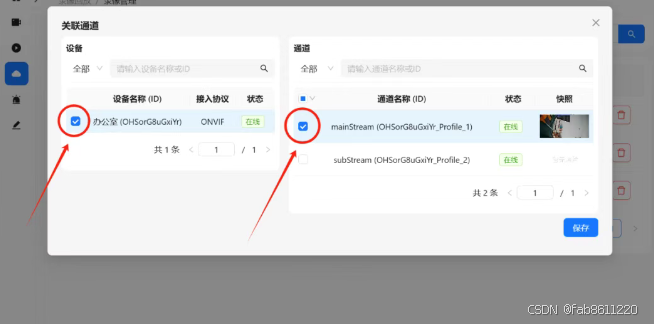
- 进入"设备列表" → 点击"添加设备"
- 选择协议类型(推荐使用ONVIF协议)
- 填写摄像头信息:
▶ 设备名称:自定义名称(如"办公室摄像头")
▶ IP地址:摄像头LAN口IP
▶ 端口号:默认80(部分型号需改成554)
▶ 用户名密码:摄像头登录凭证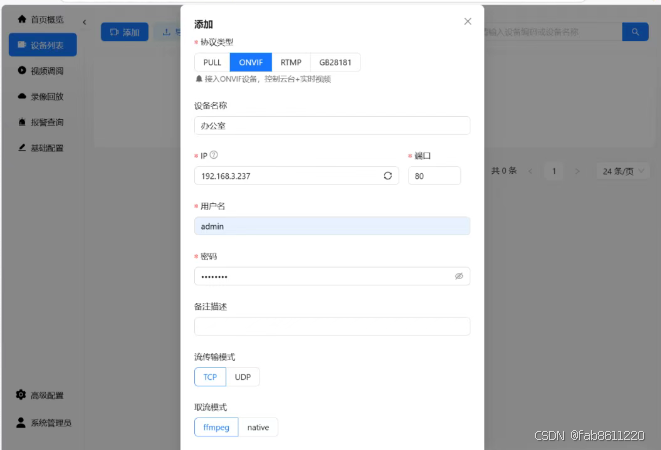
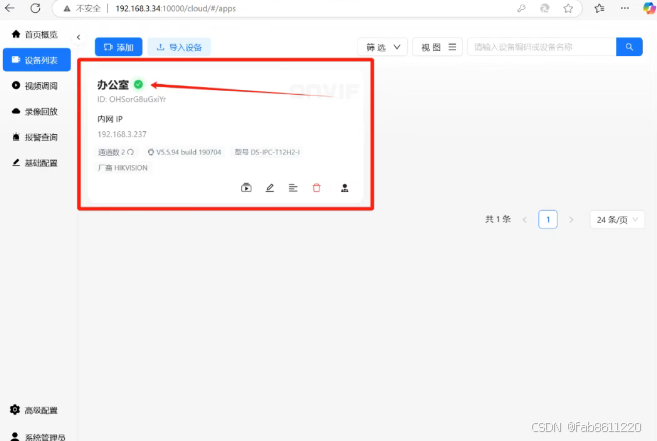
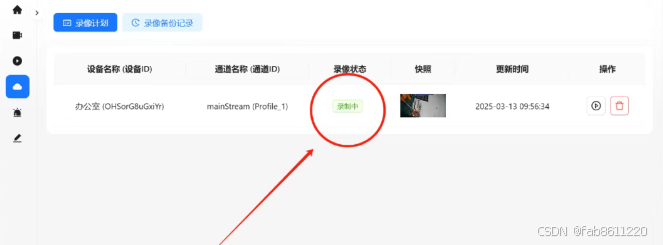
- 实时预览验证
- 添加成功后自动跳转监控界面
- 支持多画面预览、云台控制(支持海康/大华等主流品牌)
四、数据管理与维护
- 录像存储设置
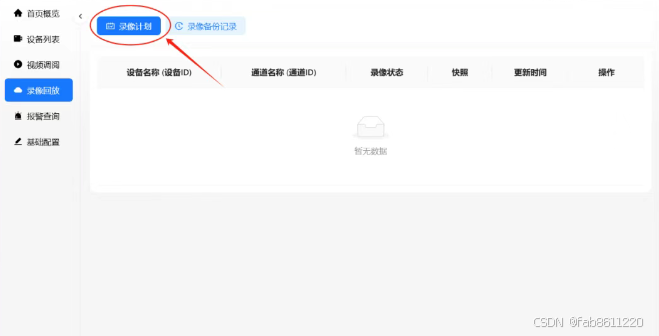
- 进入"录像计划" → 设置录像策略
- 支持定时录像、移动侦测录像等多种模式
- 默认存储路径:/app/r(可通过Docker挂载自定义路径)
- 数据备份与回放
- 支持本地存储+外接存储双备份
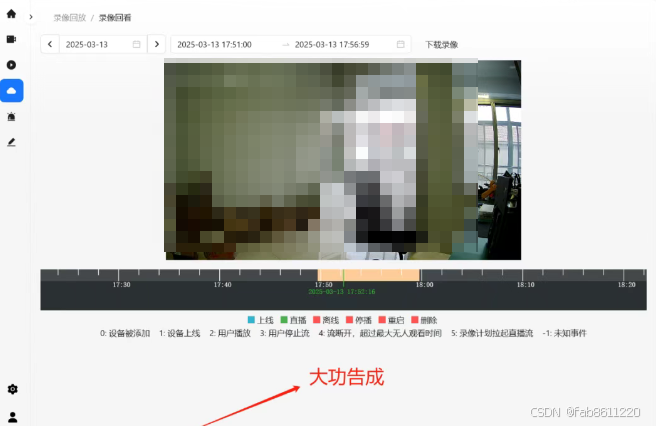
- 录像回放支持:
▶ 按时间检索(精确到秒)
▶ 关键帧快速定位
▶ 视频片段下载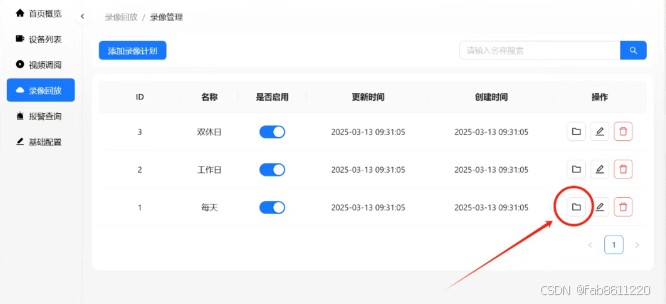
- 系统维护建议
- 每周检查存储空间使用情况
- 定期升级EasynVR容器版本
- 设置管理员短信告警(推荐搭配飞牛短信模块)
五、常见问题排查
-
设备离线?
→ 检查摄像头IP是否与NAS在同一网段
→ 测试端口连通性(Telnet IP 端口号)
→ 重启摄像头和Docker容器 -
录像缺失?
→ 确认存储路径权限设置正确
→ 检查硬盘健康状态(SMART监测)
→ 查看系统日志定位异常时间点 -
画面卡顿?
→ 优化摄像头码率(建议H.265编码)
→ 升级NAS处理器性能
→ 启用视频流缓存功能

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









