







引言
马尔可夫决策过程(Markov Decision Process, MDP)作为现代决策理论的基石,为序贯决策问题提供了严格的数学框架。本文旨在系统探讨MDP的理论基础、求解算法及其实际应用,同时通过可视化方式直观展现MDP模型的形成过程与内在机制。MDP在强化学习、运筹学、控制理论等多个领域具有深远影响,已成为人工智能研究中不可或缺的理论工具。通过马尔可夫性质,MDP能够在保持计算可行性的前提下,处理复杂的决策问题,这使其成为解决实际问题的重要方法论。
MDP的数学基础
马尔可夫决策过程基于马尔可夫性质,即系统的未来状态仅依赖于当前状态,而与历史路径无关。形式上,MDP可定义为一个五元组(S, A, P, R, γ):
- S:有限状态空间集合
- A:有限动作空间集合
- P:状态转移概率函数,P(s'|s,a)表示在状态s下采取动作a后转移到状态s'的概率
- R:奖励函数,R(s,a,s')表示从状态s经过动作a到达状态s'所获得的即时奖励
- γ:折扣因子,γ∈[0,1],用于平衡即时奖励与未来奖励
MDP的核心目标是寻找最优策略π*,使得从任意初始状态出发,按照该策略行动能够获得最大的期望累积奖励。最优策略可通过最优值函数V*(s)或最优动作-值函数Q*(s,a)来确定:
V*(s) = max_a [R(s,a) + γ∑P(s'|s,a)V*(s')]
Q*(s,a) = R(s,a) + γ∑P(s'|s,a)max_a' Q*(s',a')
MDP的组成部分与形成过程
理解MDP的形成过程对于掌握其内在机制至关重要。下图系统展示了MDP的关键组成部分及其相互关系:
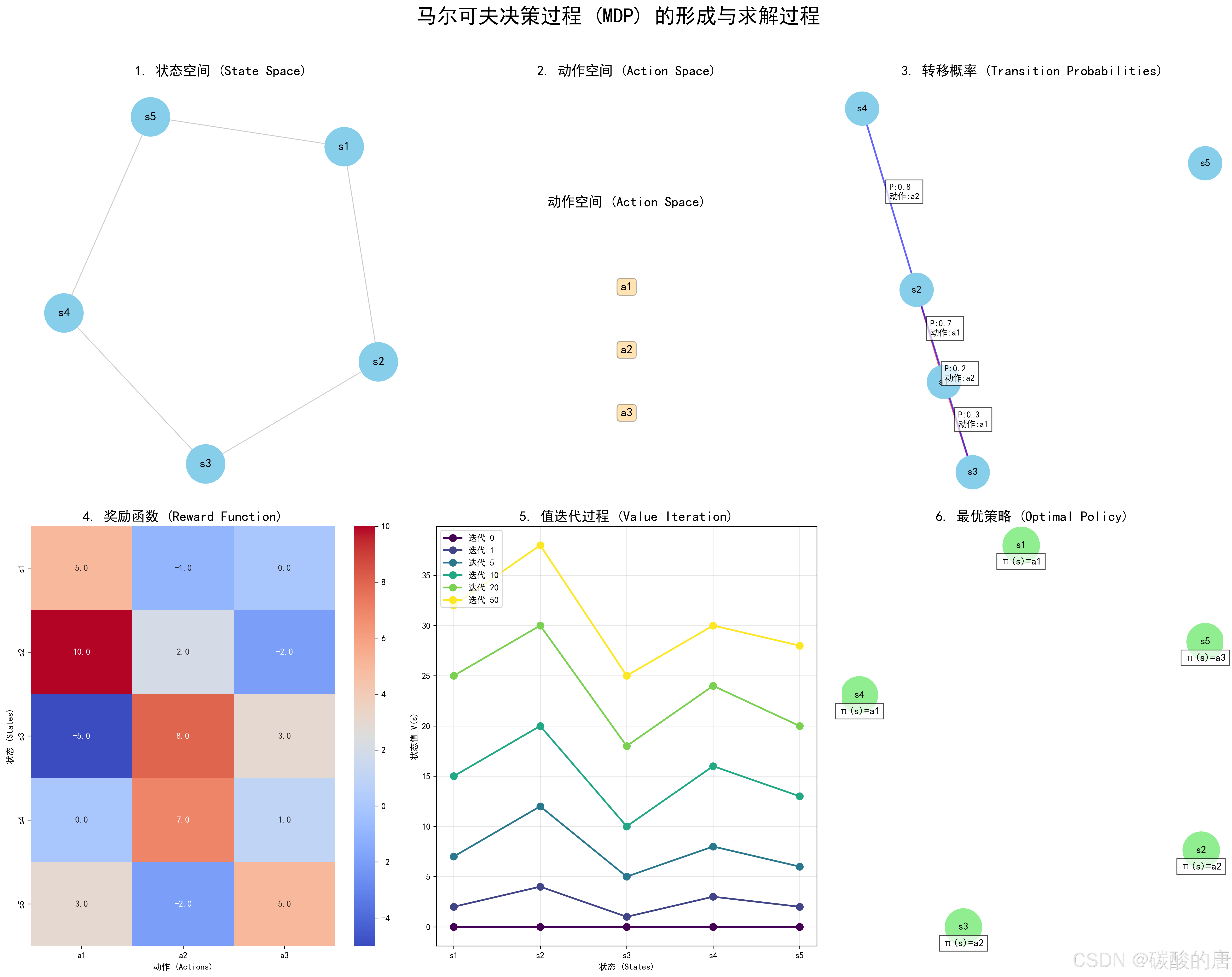
如图所示,MDP模型由六个核心部分组成:
1. 状态空间(State Space):在左上角显示,由节点s1-s5组成。状态空间代表系统可能处于的所有可能情况,是MDP的基础元素。
2. 动作空间(Action Space):在右上角展示,包含可选动作a1-a3。每个状态下,智能体可以从动作空间中选择一个动作执行。
3. 转移概率(Transition Probabilities):右上方展示了状态间的转移关系及概率。例如,在状态s1下执行动作a1,有0.7的概率转移到s2,0.3的概率转移到s3。转移概率反映了环境的动态特性及不确定性。
4. 奖励函数(Reward Function):左下方热图展示了不同状态-动作对应的奖励值。奖励函数指导智能体的学习方向,定义了任务的目标。
5. 值迭代过程(Value Iteration):中下方展示了状态值函数随迭代次数的演变趋势。可以观察到随着迭代次数增加,值函数逐渐收敛,这是求解MDP的关键步骤。
6. 最优策略(Optimal Policy):右下方展示了最终导出的最优策略,即在每个状态应采取的最优动作。例如,在状态s1应执行动作a1,在状态s2应执行动作a2。
这六个部分构成了MDP的完整框架,其中状态空间、动作空间、转移概率和奖励函数是MDP的基本元素,而值迭代过程和最优策略则是求解MDP的结果。
MDP求解算法的比较分析
MDP的求解方法多种多样,主要包括值迭代、策略迭代、Q学习等算法。不同算法在收敛速度、计算效率、内存需求等方面具有各自特点。下图对比了主要MDP求解算法的性能特征:
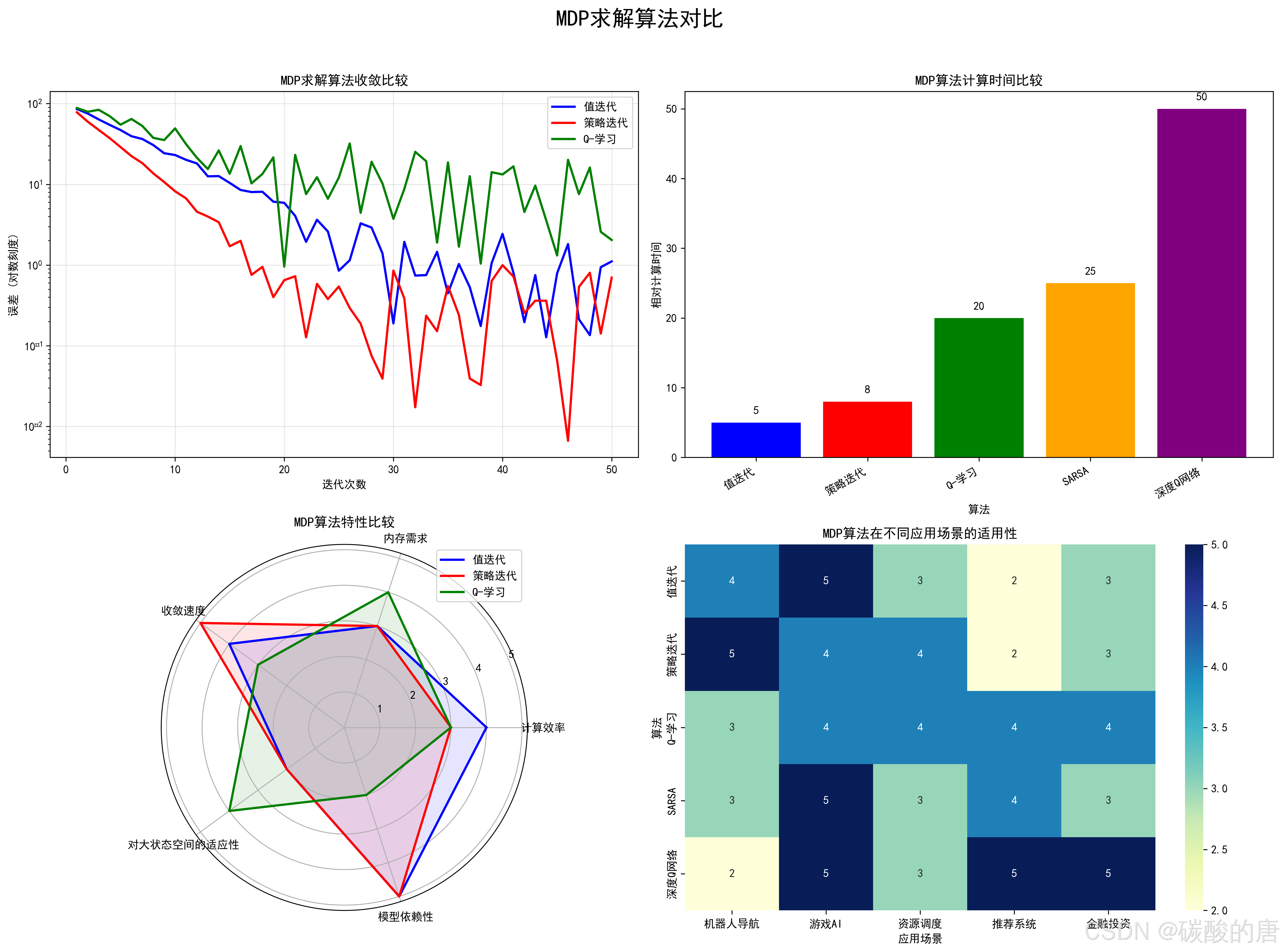
从上图可以得出以下几点观察:
1. 收敛速度比较:左上角的收敛曲线显示,策略迭代通常具有最快的收敛速度,而Q学习则收敛较慢且波动较大。这与策略迭代的理论特性相符,即每次迭代都保证策略改进。
2. 计算时间比较:右上角的柱状图展示了不同算法的相对计算时间。值迭代和策略迭代计算效率较高,而深度Q网络等基于神经网络的方法计算开销较大。
3. 算法特性雷达图:左下角的雷达图从多维度比较了算法特性。可以看出:
- 值迭代在计算效率方面表现优异,但对大状态空间适应性较差
- 策略迭代在收敛速度方面领先,但同样不适合大规模问题
- Q学习对大状态空间适应性较好,但模型依赖性较低,需要更多探索
4. 应用场景适用性:右下角的热图展示了不同算法在各类应用场景中的适用程度。例如,值迭代和策略迭代更适合机器人导航,而深度Q网络在游戏AI和金融投资等场景中表现更佳。
这些比较为选择合适的MDP求解算法提供了依据。在实际应用中,应根据问题特性、计算资源限制和精度要求等因素选择适当的算法。
MDP在网格世界中的实例应用
为了更直观地理解MDP的应用,下面通过经典的网格世界(Grid World)问题进行说明:
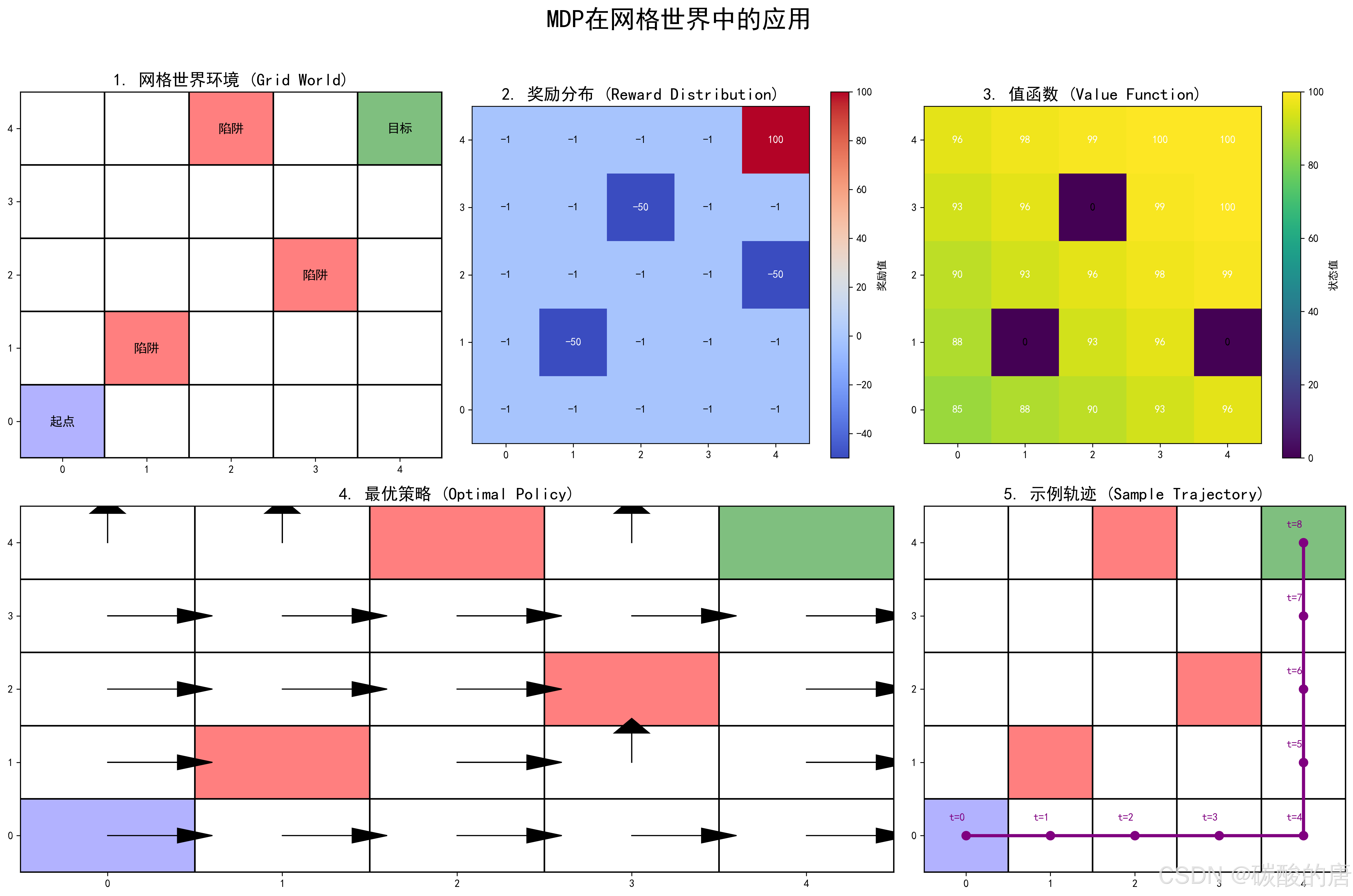
网格世界是强化学习研究中广泛使用的测试环境,其具体设置如下:
1. 环境设置:左上图展示了一个5×5的网格环境,包含起点(蓝色)、目标(绿色)和多个陷阱(红色)。智能体需要从起点出发,避开陷阱,到达目标位置。
2. 奖励分布:中上图展示了环境中的奖励分布。目标位置奖励为100,陷阱位置惩罚为-50,普通格子惩罚为-1(表示移动成本)。这种奖励设置鼓励智能体尽快到达目标,同时避开陷阱。
3. 值函数:右上图展示了经过值迭代后得到的状态值函数。值越高的格子(黄色区域)对智能体越有吸引力,值为0的格子(深蓝色)对应陷阱位置。
4. 最优策略:左下图通过箭头展示了最优策略,即智能体在每个位置应采取的最优动作(上、下、左、右)。可以看出,最优策略引导智能体沿着最安全且最短的路径到达目标。
5. 示例轨迹:右下图展示了按照最优策略执行的一条示例轨迹,从t=0到t=8,智能体成功地从起点导航到目标,完全避开了陷阱。
这个网格世界实例生动展示了MDP在路径规划、导航、避障等问题中的应用价值。通过定义适当的状态空间、动作空间、转移模型和奖励函数,MDP能够为智能体提供最优决策指导。
MDP模型实现的关键代码
以下展示了部分关键代码,用于实现MDP模型的可视化:
def visualize_mdp_formation():
"""生成一系列图片来展示MDP模型的形成过程"""
# 创建主图表
plt.figure(figsize=(20, 16))
gs = GridSpec(2, 3, figure=plt.gcf())
# ---- 1. 状态空间可视化 ----
ax1 = plt.subplot(gs[0, 0])
G_states = nx.Graph()
states = ["s1", "s2", "s3", "s4", "s5"]
G_states.add_nodes_from(states)
# 添加一些边来优化布局
G_states.add_edges_from([("s1", "s2"), ("s2", "s3"), ("s3", "s4"), ("s4", "s5"), ("s5", "s1")])
pos = nx.spring_layout(G_states, seed=42)
nx.draw_networkx_nodes(G_states, pos, node_size=2000,
node_color='skyblue', ax=ax1)
nx.draw_networkx_labels(G_states, pos, font_size=14,
font_weight='bold', ax=ax1)
# ... 其他组件的可视化代码 ...值迭代算法的典型实现如下:
def value_iteration(states, actions, transition_prob, rewards, gamma=0.9, epsilon=1e-6):
"""
实现值迭代算法求解MDP
参数:
states: 状态空间
actions: 动作空间
transition_prob: 转移概率函数 P(s'|s,a)
rewards: 奖励函数 R(s,a,s')
gamma: 折扣因子
epsilon: 收敛阈值
返回:
V: 最优值函数
policy: 最优策略
"""
# 初始化值函数
V = {s: 0 for s in states}
while True:
delta = 0
# 遍历所有状态
for s in states:
v = V[s]
# 计算在当前状态下采取每个动作的值
action_values = []
for a in actions:
# 计算期望值: \sum_{s'} P(s'|s,a)[R(s,a,s') + gamma*V(s')]
expected_value = sum(
transition_prob(s, a, s_prime) *
(rewards(s, a, s_prime) + gamma * V[s_prime])
for s_prime in states
)
action_values.append(expected_value)
# 选择最大值作为新的状态值
V[s] = max(action_values)
# 计算值变化
delta = max(delta, abs(v - V[s]))
# 检查是否收敛
if delta < epsilon:
break
# 根据值函数导出最优策略
policy = {}
for s in states:
action_values = []
for a in actions:
expected_value = sum(
transition_prob(s, a, s_prime) *
(rewards(s, a, s_prime) + gamma * V[s_prime])
for s_prime in states
)
action_values.append((a, expected_value))
# 选择值最大的动作
policy[s] = max(action_values, key=lambda x: x[1])[0]
return V, policy
```在实际应用中,MDP模型的实现可能需要根据具体问题进行调整。例如,对于大规模状态空间,可能需要采用函数逼近或深度学习方法来估计值函数;对于连续状态空间,可能需要采用状态离散化或直接处理连续MDP的方法。
MDP的前沿应用与研究方向
随着人工智能和决策理论的发展,MDP在多个领域展现出广阔的应用前景:
1. **自动驾驶**:MDP可用于建模自动驾驶系统的决策过程,如车道变换、速度控制和路径规划等。通过合理设计奖励函数,可以平衡安全性、舒适性和效率等多重目标。
2. **医疗决策支持**:在医疗领域,MDP可用于治疗方案的优化决策,帮助医生制定个性化治疗计划。例如,癌症治疗的剂量调整、慢性病的长期管理等。
3. **资源管理**:MDP在能源调度、计算资源分配、网络带宽管理等资源优化问题中有广泛应用。通过动态规划方法,可以在时变环境中实现资源的最优分配。
4. **金融投资**:在金融领域,MDP可用于投资组合优化、风险管理和交易策略制定。考虑市场的随机性和投资者的风险偏好,MDP能够提供理论上最优的投资决策。
5. **智能推荐系统**:MDP框架可用于构建序贯推荐系统,考虑用户长期兴趣和短期行为,优化推荐序列,提高用户满意度和平台收益。
当前MDP研究的前沿方向包括:
部分可观测MDP(POMDP):处理状态不完全可观测的决策问题
-多智能体MDP:研究多个智能体共同决策的均衡和协作机制
- 鲁棒MDP:考虑模型不确定性和环境扰动的稳健决策
- 逆强化学习:从专家行为中逆向推导奖励函数
- *深度强化学习:结合深度学习与MDP框架,处理高维状态空间问题
结论
马尔可夫决策过程作为序贯决策理论的基石,为构建智能决策系统提供了严格的数学框架。本文通过系统的可视化展示,阐述了MDP的理论基础、组成部分、求解算法及其应用实例,旨在帮助读者建立对MDP的直观理解。
MDP的核心价值在于其能够处理不确定性环境中的长期规划问题,并能通过动态规划或强化学习等方法求得最优策略。通过合理的状态表示、动作设计和奖励函数定义,MDP可以应用于广泛的实际问题,从简单的网格世界导航到复杂的自动驾驶决策。
随着计算能力的提升和算法的进步,MDP及其扩展形式将在人工智能和决策系统中发挥越来越重要的作用。理解和掌握MDP的原理与应用,对于从事人工智能、运筹学、控制理论等领域的研究者和实践者具有重要意义。


















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











