






背景概述
在当今数字化时代,电影产业呈现出前所未有的繁荣与复杂性。随着全球电影市场的不断扩张,海量的电影作品被制作和发行,涵盖了各种类型、风格和主题。电影制作公司、发行商、影院以及相关的影视投资机构等面临着诸多挑战与机遇。一方面,如何在众多影片中精准定位受众需求,制定有效的营销策略以提高影片票房成绩和市场占有率成为关键问题。例如,了解不同地区、年龄、性别群体对电影类型的偏好差异,能够为影片的发行渠道选择和宣传推广重点提供有力依据。另一方面,对于电影创作者而言,分析过往成功与失败电影的数据,可以洞察观众喜好的变化趋势,在剧本创作、角色塑造、拍摄手法等方面做出更符合市场期待的决策,从而提升作品的艺术价值与商业竞争力。同时,随着互联网和社交媒体的蓬勃发展,观众的观影评价、讨论热度等数据也呈现出爆炸式增长,这些数据蕴含着丰富的信息,能够反映观众对电影的情感倾向、口碑传播效应以及对特定元素的关注度,为电影产业的各个环节提供了极具价值的参考,促使电影数据分析成为深入理解电影市场、优化产业运作的重要手段。
本文主要研究以下几个问题:
问题一:19年到22年电影类型如何随着时间的推移发生变化的?
问题二:19年到22年电影类型与票房的关系?
在类中导入对应的包(类名:MovieAnalyzer.py)
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.globals import ThemeType在主方法(main)中导入类方法
from MovieAnalyzer import MovieAnalyzer
import pandas as pd定义一个用来画图的类,先定义一个方法获取每个电影的类型
class MovieAnalyzer:
def __init__(self, data):
# 初始化方法,接收电影数据
self.df = data
def count_top_10_movie_types(self):
# 拆分电影类型字段,将包含多个类型的字符串拆分成列表
self.df['type'] = self.df['type'].str.split('/')
# 将数据框展开,每个电影类型占一行
self.df = self.df.explode('type')
# 统计不同类型的电影数量
movie_type_counts = self.df['type'].value_counts()
# 获取前十名的电影类型
top_10_movie_types = movie_type_counts.head(10)
return top_10_movie_types在定义一个方法用来画出动态柱状图
def plot_movie_type_trend(self):
# 将showtime列转换为日期类型
self.df['showtime'] = pd.to_datetime(self.df['showtime'])
# 提取年份
self.df['year'] = self.df['showtime'].dt.year
# 拆分电影类型字段,将包含多个类型的字符串拆分成列表
self.df['type'] = self.df['type'].str.split('/')
# 将数据框展开,每个电影类型占一行
self.df = self.df.explode('type')
# 统计每年不同类型的电影数量
yearly_movie_type_counts = self.df.groupby(['year', 'type']).size().reset_index(name='数量')
# 创建时间轴对象,用于生成动态柱状图
timeline = Timeline(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
for year in yearly_movie_type_counts['year'].unique():
# 获取当前年份的数据
year_df = yearly_movie_type_counts[yearly_movie_type_counts['year'] == year]
# 获取当前年份中存在的电影类型
movie_types_in_year = year_df['type'].unique()
bar = (
Bar()
# 设置x轴数据为当前年份的电影类型
.add_xaxis(movie_types_in_year.tolist())
# 设置y轴数据为当前年份各电影类型对应的数量
.add_yaxis("数量", year_df.set_index('type')['数量'].reindex(movie_types_in_year).tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title=f"电影类型分布 - {year}年"),
xaxis_opts=opts.AxisOpts(name="电影类型"),
yaxis_opts=opts.AxisOpts(name="数量"),
toolbox_opts=opts.ToolboxOpts(is_show=True)
)
)
timeline.add(bar, time_point=str(year))
timeline.add_schema(
play_interval=1000,
is_auto_play=True,
is_loop_play=True,
is_timeline_show=True,
label_opts=opts.LabelOpts(is_show=True)
)
# 渲染动态柱状图到HTML文件
timeline.render("movie_type_trend_timeline.html")问题一:这样我们通过main中读取数据在调用方法就可以画出19年到22年电影类型如何随着时间的推移发生变化的
# 读取电影数据文件(Excel格式)
excel_file = pd.ExcelFile('E:/xiazai/movie.xlsx')
# 获取指定工作表中的数据
df = excel_file.parse('Sheet1')
# 创建MovieAnalyzer对象,传入数据
analyzer = MovieAnalyzer(df)
# 统计不同类型的电影数量的前十名
top_10_movie_types = analyzer.count_top_10_movie_types()
print("不同类型的电影数量的前十名:")
print(top_10_movie_types)
# 绘制不同电影类型随时间变化的动态柱状图
analyzer.plot_movie_type_trend()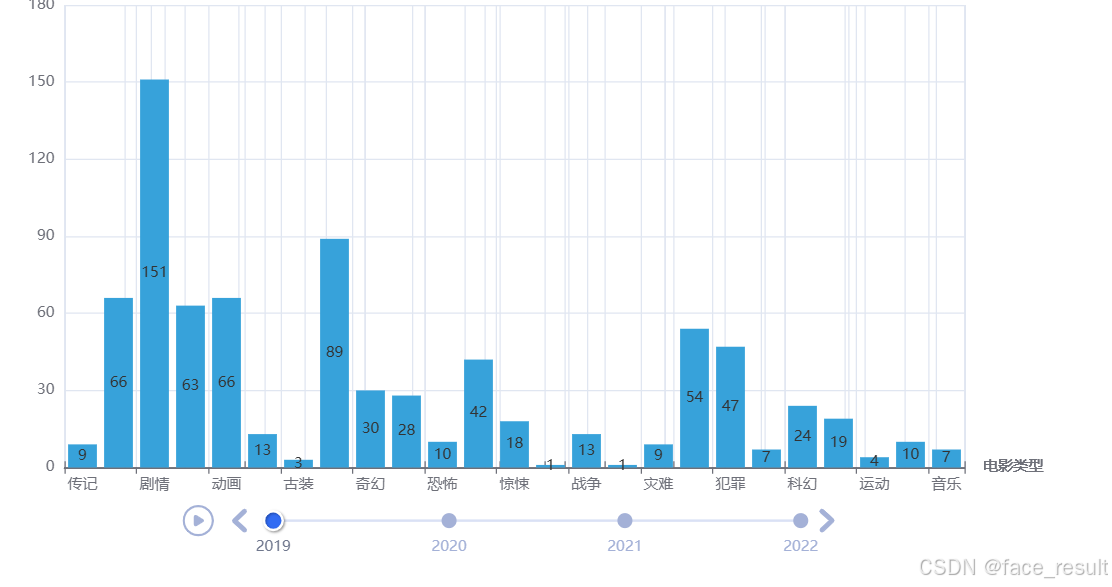
分析结论剧情,喜剧类型的电影遥遥领先其他类型,深受观众喜爱。
继续定义一个方法用来提取票房列中的数字部分,其中数据中含有无数据部分要先剔除,然后将数据改成float类型,在同一成以万为单位并保留整数
ef calculate_top_10_avg_box_office(self):
# 剔除票房列中的NaN值
self.df = self.df.dropna(subset=['票房'])
# 提取票房数据中的数字部分并转换为浮点数
self.df['box_office_num'] = self.df['票房'].str.extract('(\d+\.?\d*)').astype(float)
# 根据单位(万或亿)将票房数据统一转换为以万为单位
self.df['box_office_num'] = self.df.apply(lambda x: x['box_office_num'] * 10000 if '亿' in x['票房'] else x['box_office_num'], axis=1)
self.df['type'] = self.df['type'].str.split('/')
self.df = self.df.explode('type')
avg_box_office = self.df.groupby('type')['box_office_num'].mean().reset_index(name='平均票房')
sorted_avg_box_office = avg_box_office.sort_values(by='平均票房', ascending=False)
top_10_avg_box_office = sorted_avg_box_office.head(10)
# 将平均票房数据转换为以万为单位并保留整数
top_10_avg_box_office['平均票房'] = top_10_avg_box_office['平均票房'].round().astype(int)
return top_10_avg_box_office最后定义一个方法用来画出19年到22年电影类型与票房的关系图
def plot_top_10_avg_box_office(self):
# 获取不同类型电影的平均票房前十名的数据
top_10_avg_box_office = self.calculate_top_10_avg_box_office()
# 创建一个柱状图对象,设置初始化主题为`ThemeType.LIGHT`(明亮主题)
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
# 设置x轴数据,使用平均票房前十名的电影类型列表
.add_xaxis(top_10_avg_box_office['type'].tolist())
# 设置y轴数据,使用平均票房前十名的平均票房数值列表,并将y轴标签设置为"平均票房(万)"
.add_yaxis("平均票房(万)", top_10_avg_box_office['平均票房'].tolist())
.set_global_opts(
# 设置图表标题为"不同类型电影的平均票房前十名"
title_opts=opts.TitleOpts(title="不同类型电影的平均票房前十名"),
# 显示工具箱,方便用户进行一些操作,如缩放、下载等
toolbox_opts=opts.ToolboxOpts(is_show=True),
# 设置x轴的名称为"电影类型"
xaxis_opts=opts.AxisOpts(name="电影类型"),
# 设置y轴的名称为"平均票房(万)"
yaxis_opts=opts.AxisOpts(name="平均票房(万)"),
# 设置图例的位置在图表顶部95%的位置
legend_opts=opts.LegendOpts(pos_top="95%")
)
)
# 将绘制好的图表渲染为`top_10_avg_box_office.html`文件,以便在浏览器中查看
bar.render("top_10_avg_box_office.html")问题二:在main中调用方法画出19年到22年电影类型与平均票房的柱状图
# 统计各个类型电影的平均票房前十名
top_10_avg_box_office = analyzer.calculate_top_10_avg_box_office()
print("各个类型电影的平均票房前十名:")
print(top_10_avg_box_office)
# 绘制各个类型电影的平均票房前十名的柱状图
analyzer.plot_top_10_avg_box_office()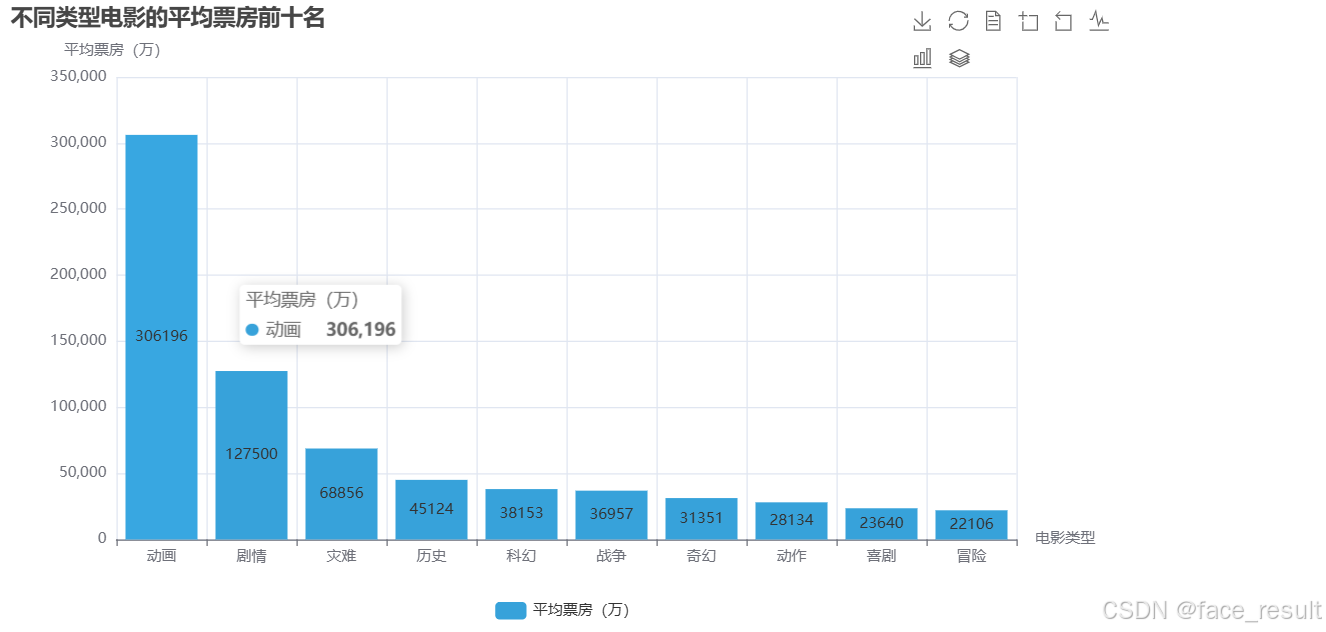
分析结论:动画,剧情,灾难三种电影类型票房最可观,然而电影类型数量排名第二的喜剧票房却排在了倒数第二,可能是因为该类型电影的市场斗争太过激烈,拍摄此电影有一定的风险

















 3035
3035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









