







前提
默认对Anaconda安装成功,不需要安装Cuda等和GPU相关的任何包,因为在虚拟环境中有相应的方法进行安装。故,本教程只需要在电脑中安装Anaconda即可。
电脑配置:
本文是在Windows11+3060环境下实现。
Nerf数据集下载
原文中提供了bash的下载方法,其对大多用户不可用,同时速度较慢,采用网盘下载。网盘链接
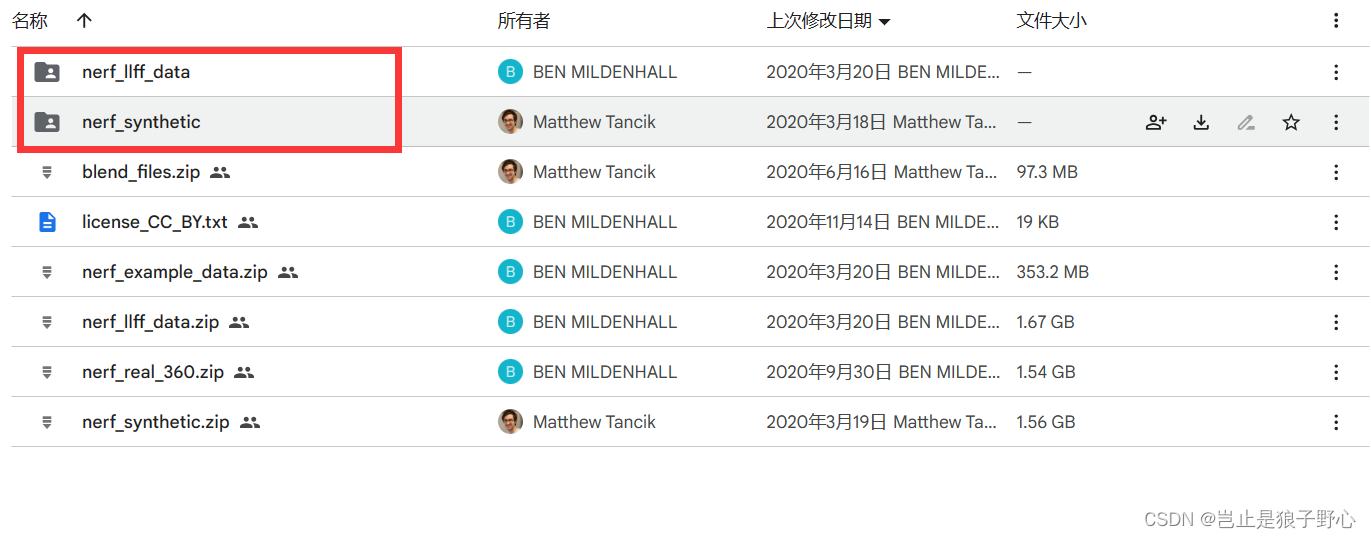
其中synthetic是有相机参数的文件夹,对于mipnerf很友好。(Mipnerf的使用方法见另一篇博客),如果只是用Nerf的话可以只下载llff_data。
下载成功后将数据集放在Nerf文件夹中的Data文件夹下即可。
Nerf运行使用
Nerf 文章地址。
Nerf 源码地址。
Nerf源码中已经详细的介绍了如何安装环境,但是安装过程发现遇到了pytorch和cuda版本不匹配的问题。下面将在原文基础改进此问题。
Nerf环境安装
原文安装方式:
git clone git@github.com:yenchenlin/nerf-pytorch.git
conda create -n nerf -y python=3.9
conda activate nerf
python -m pip install --upgrade pip
pip install -r requirements.txt
上述指令如果完全安装成功,则应该有如下的界面:
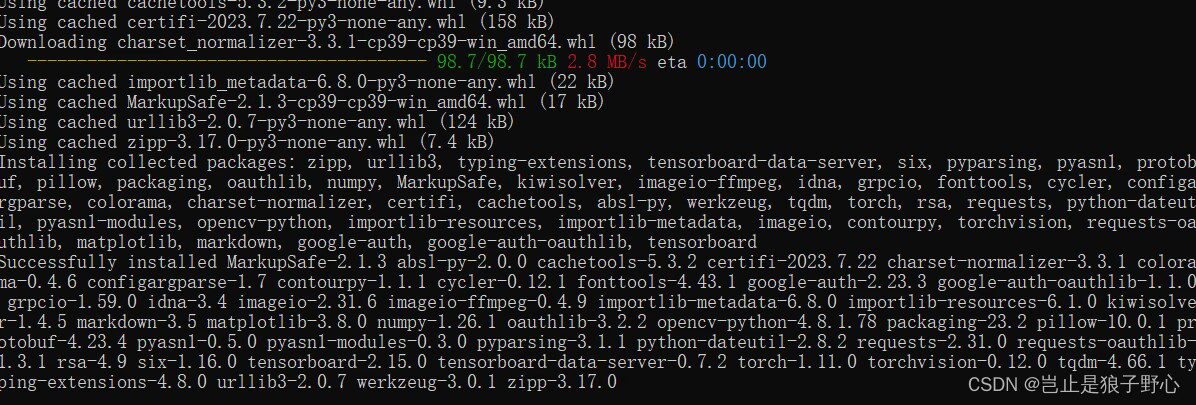
为了测试环境是否成功正确安装,运行一次训练程序:
conda activate nerf
python run_nerf.py --config configs/lego.txt
成功运行如下结果:

若出现如下结果,则进入问题一:

如果没问题,则跳过接下来的Nerf安装过程,进入使用自己数据集的过程,若有问题则继续修改。
问题1 CUDA和torch不匹配
出现此问题,我的解决方法是自己到官网安装pytorch、torchvision、torchaudio、cudatoolkit,这样对于CUDA和torch一定是匹配的,而且conda安装一般会比pip快一点。
保险的方法是写在刚才的nerf环境,重新安装环境。
第一步是修改requirements.txt文件,删掉对pytorch的安装部分。

之后依次输入指令
conda deactivate
conda remove -n nerf -y--all
conda create -n nerf -y python=3.9
conda activate nerf
python -m pip install --upgrade pip
# 根据自己电脑修改
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
如此修改之后,电脑安装过程和运行过程不再报错。
Nerf使用自己数据集
本章大量使用博主《三维小菜鸡》的文章:nerf训练自己的数据,过程记录十分详细
具体过程可以参考该文章,本文只对其中报错部分进行相关的完善。
COLMAP使用哦个
第一步配置操作可以忽略,进入第二步创建llff格式的数据集。首先需要下载COLMAP,进行参数获取。该部分博主《三维小菜鸡》已经进行了详细介绍,不再赘述。
在最后一步,运行程序:
conda activate llff
python imgs2poses.py data/nerf_ffll_data/llfftest
的时候出现报错(ERROR: the correct camera poses for current points cannot be accessed):

这是由于colmap使用的图片和数据集中的图片个数不匹配导致的,具体需要修改llff/poses/pose_utils.py文件(来自GitHub大佬starhiking ),修改文件后,会在llfftest目录下产生view_imgs.txt文件,其中存储的就是COLMAP使用的视角。
对文件修改比较复杂,这里直接将整个文件贴下,只需要将下面内容替换pose_utils.py文件即可。
import numpy as np
import os
import sys
import imageio
import skimage.transform
from llff.poses.colmap_wrapper import run_colmap
import llff.poses.colmap_read_model as read_model
def save_views(realdir,names):
with open(os.path.join(realdir,'view_imgs.txt'), mode='w') as f:
f.writelines('\n'.join(names))
f.close()
def load_save_pose(realdir):
# load colmap data
camerasfile = os.path.join(realdir, 'sparse/0/cameras.bin')
camdata = read_model.read_cameras_binary(camerasfile)
list_of_keys = list(camdata.keys())
cam = camdata[list_of_keys[0]]
print( 'Cameras', cam)
h, w, f = cam.height, cam.width, cam.params[0]
hwf = np.array([h,w,f]).reshape([3,1])
imagesfile = os.path.join(realdir, 'sparse/0/images.bin')
imdata = read_model.read_images_binary(imagesfile)
real_ids = [k for k in imdata]
w2c_mats = []
bottom = np.array([0,0,0,1.]).reshape([1,4])
names = [imdata[k].name for k in imdata]
print( 'Images #', len(names))
# if (len(names)< 32):
# raise ValueError(f'{realdir} only {len(names)} images register, need Re-run colmap or reset the threshold')
perm = np.argsort(names)
sort_names = [names[i] for i in perm]
save_views(realdir,sort_names)
for k in imdata:
im = imdata[k]
R = im.qvec2rotmat()
t = im.tvec.reshape([3,1])
m = np.concatenate([np.concatenate([R, t], 1), bottom], 0)
w2c_mats.append(m)
w2c_mats = np.stack(w2c_mats, 0)
c2w_mats = np.linalg.inv(w2c_mats)
poses = c2w_mats[:, :3, :4].transpose([1,2,0])
poses = np.concatenate([poses, np.tile(hwf[..., np.newaxis], [1,1,poses.shape[-1]])], 1)
points3dfile = os.path.join(realdir, 'sparse/0/points3D.bin')
pts3d = read_model.read_points3d_binary(points3dfile)
# must switch to [-u, r, -t] from [r, -u, t], NOT [r, u, -t]
poses = np.concatenate([poses[:, 1:2, :], poses[:, 0:1, :], -poses[:, 2:3, :], poses[:, 3:4, :], poses[:, 4:5, :]], 1)
# save pose
pts_arr = []
vis_arr = []
for k in pts3d:
pts_arr.append(pts3d[k].xyz)
cams = [0] * poses.shape[-1]
for ind in pts3d[k].image_ids:
if len(cams) < real_ids.index(ind):
print('ERROR: the correct camera poses for current points cannot be accessed')
return
cams[real_ids.index(ind)] = 1
vis_arr.append(cams)
pts_arr = np.array(pts_arr)
vis_arr = np.array(vis_arr)
print( 'Points', pts_arr.shape, 'Visibility', vis_arr.shape)
zvals = np.sum(-(pts_arr[:, np.newaxis, :].transpose([2,0,1]) - poses[:3, 3:4, :]) * poses[:3, 2:3, :], 0)
valid_z = zvals[vis_arr==1]
print( 'Depth stats', valid_z.min(), valid_z.max(), valid_z.mean() )
save_arr = []
for i in perm:
vis = vis_arr[:, i]
zs = zvals[:, i]
zs = zs[vis==1]
close_depth, inf_depth = np.percentile(zs, .1), np.percentile(zs, 99.9)
save_arr.append(np.concatenate([poses[..., i].ravel(), np.array([close_depth, inf_depth])], 0))
save_arr = np.array(save_arr)
np.save(os.path.join(realdir, 'poses_bounds.npy'), save_arr)
def load_colmap_data(realdir):
camerasfile = os.path.join(realdir, 'sparse/0/cameras.bin')
camdata = read_model.read_cameras_binary(camerasfile)
# cam = camdata[camdata.keys()[0]]
list_of_keys = list(camdata.keys())
cam = camdata[list_of_keys[0]]
print( 'Cameras', len(cam))
h, w, f = cam.height, cam.width, cam.params[0]
# w, h, f = factor * w, factor * h, factor * f
hwf = np.array([h,w,f]).reshape([3,1])
imagesfile = os.path.join(realdir, 'sparse/0/images.bin')
imdata = read_model.read_images_binary(imagesfile)
w2c_mats = []
bottom = np.array([0,0,0,1.]).reshape([1,4])
names = [imdata[k].name for k in imdata]
print( 'Images #', len(names))
perm = np.argsort(names)
for k in imdata:
im = imdata[k]
R = im.qvec2rotmat()
t = im.tvec.reshape([3,1])
m = np.concatenate([np.concatenate([R, t], 1), bottom], 0)
w2c_mats.append(m)
w2c_mats = np.stack(w2c_mats, 0)
c2w_mats = np.linalg.inv(w2c_mats)
poses = c2w_mats[:, :3, :4].transpose([1,2,0])
poses = np.concatenate([poses, np.tile(hwf[..., np.newaxis], [1,1,poses.shape[-1]])], 1)
points3dfile = os.path.join(realdir, 'sparse/0/points3D.bin')
pts3d = read_model.read_points3d_binary(points3dfile)
# must switch to [-u, r, -t] from [r, -u, t], NOT [r, u, -t]
poses = np.concatenate([poses[:, 1:2, :], poses[:, 0:1, :], -poses[:, 2:3, :], poses[:, 3:4, :], poses[:, 4:5, :]], 1)
return poses, pts3d, perm
def save_poses(basedir, poses, pts3d, perm):
pts_arr = []
vis_arr = []
for k in pts3d:
pts_arr.append(pts3d[k].xyz)
cams = [0] * poses.shape[-1]
for ind in pts3d[k].image_ids:
if len(cams) < ind - 1:
print('ERROR: the correct camera poses for current points cannot be accessed')
return
cams[ind-1] = 1
vis_arr.append(cams)
pts_arr = np.array(pts_arr)
vis_arr = np.array(vis_arr)
print( 'Points', pts_arr.shape, 'Visibility', vis_arr.shape )
zvals = np.sum(-(pts_arr[:, np.newaxis, :].transpose([2,0,1]) - poses[:3, 3:4, :]) * poses[:3, 2:3, :], 0)
valid_z = zvals[vis_arr==1]
print( 'Depth stats', valid_z.min(), valid_z.max(), valid_z.mean() )
save_arr = []
for i in perm:
vis = vis_arr[:, i]
zs = zvals[:, i]
zs = zs[vis==1]
close_depth, inf_depth = np.percentile(zs, .1), np.percentile(zs, 99.9)
# print( i, close_depth, inf_depth )
save_arr.append(np.concatenate([poses[..., i].ravel(), np.array([close_depth, inf_depth])], 0))
save_arr = np.array(save_arr)
np.save(os.path.join(basedir, 'poses_bounds.npy'), save_arr)
def minify_v0(basedir, factors=[], resolutions=[]):
needtoload = False
for r in factors:
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
for r in resolutions:
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
if not needtoload:
return
def downsample(imgs, f):
sh = list(imgs.shape)
sh = sh[:-3] + [sh[-3]//f, f, sh[-2]//f, f, sh[-1]]
imgs = np.reshape(imgs, sh)
imgs = np.mean(imgs, (-2, -4))
return imgs
imgdir = os.path.join(basedir, 'images')
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgs = np.stack([imageio.imread(img)/255. for img in imgs], 0)
for r in factors + resolutions:
if isinstance(r, int):
name = 'images_{}'.format(r)
else:
name = 'images_{}x{}'.format(r[1], r[0])
imgdir = os.path.join(basedir, name)
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
if isinstance(r, int):
imgs_down = downsample(imgs, r)
else:
imgs_down = skimage.transform.resize(imgs, [imgs.shape[0], r[0], r[1], imgs.shape[-1]],
order=1, mode='constant', cval=0, clip=True, preserve_range=False,
anti_aliasing=True, anti_aliasing_sigma=None)
os.makedirs(imgdir)
for i in range(imgs_down.shape[0]):
imageio.imwrite(os.path.join(imgdir, 'image{:03d}.png'.format(i)), (255*imgs_down[i]).astype(np.uint8))
def minify(basedir, factors=[], resolutions=[]):
needtoload = False
for r in factors:
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
for r in resolutions:
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
if not needtoload:
return
from shutil import copy
from subprocess import check_output
imgdir = os.path.join(basedir, 'images')
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgdir_orig = imgdir
wd = os.getcwd()
for r in factors + resolutions:
if isinstance(r, int):
name = 'images_{}'.format(r)
resizearg = '{}%'.format(int(100./r))
else:
name = 'images_{}x{}'.format(r[1], r[0])
resizearg = '{}x{}'.format(r[1], r[0])
imgdir = os.path.join(basedir, name)
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
os.makedirs(imgdir)
check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True)
ext = imgs[0].split('.')[-1]
args = ' '.join(['mogrify', '-resize', resizearg, '-format', 'png', '*.{}'.format(ext)])
print(args)
os.chdir(imgdir)
check_output(args, shell=True)
os.chdir(wd)
if ext != 'png':
check_output('rm {}/*.{}'.format(imgdir, ext), shell=True)
print('Removed duplicates')
print('Done')
def load_data(basedir, factor=None, width=None, height=None, load_imgs=True):
poses_arr = np.load(os.path.join(basedir, 'poses_bounds.npy'))
poses = poses_arr[:, :-2].reshape([-1, 3, 5]).transpose([1,2,0])
bds = poses_arr[:, -2:].transpose([1,0])
img0 = [os.path.join(basedir, 'images', f) for f in sorted(os.listdir(os.path.join(basedir, 'images'))) \
if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')][0]
sh = imageio.imread(img0).shape
sfx = ''
if factor is not None:
sfx = '_{}'.format(factor)
minify(basedir, factors=[factor])
factor = factor
elif height is not None:
factor = sh[0] / float(height)
width = int(sh[1] / factor)
minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
elif width is not None:
factor = sh[1] / float(width)
height = int(sh[0] / factor)
minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
else:
factor = 1
imgdir = os.path.join(basedir, 'images' + sfx)
if not os.path.exists(imgdir):
print( imgdir, 'does not exist, returning' )
return
imgfiles = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir)) if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')]
if poses.shape[-1] != len(imgfiles):
print( 'Mismatch between imgs {} and poses {} !!!!'.format(len(imgfiles), poses.shape[-1]) )
return
sh = imageio.imread(imgfiles[0]).shape
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])
poses[2, 4, :] = poses[2, 4, :] * 1./factor
if not load_imgs:
return poses, bds
# imgs = [imageio.imread(f, ignoregamma=True)[...,:3]/255. for f in imgfiles]
def imread(f):
if f.endswith('png'):
return imageio.imread(f, ignoregamma=True)
else:
return imageio.imread(f)
imgs = imgs = [imread(f)[...,:3]/255. for f in imgfiles]
imgs = np.stack(imgs, -1)
print('Loaded image data', imgs.shape, poses[:,-1,0])
return poses, bds, imgs
def gen_poses(basedir, match_type, factors=None):
files_needed = ['{}.bin'.format(f) for f in ['cameras', 'images', 'points3D']]
if os.path.exists(os.path.join(basedir, 'sparse/0')):
files_had = os.listdir(os.path.join(basedir, 'sparse/0'))
else:
files_had = []
if not all([f in files_had for f in files_needed]):
print( 'Need to run COLMAP' )
run_colmap(basedir, match_type)
else:
print('Don\'t need to run COLMAP')
print( 'Post-colmap')
load_save_pose(basedir)
# poses, pts3d, perm = load_colmap_data(basedir)
# save_poses(basedir, poses, pts3d, perm)
if factors is not None:
print( 'Factors:', factors)
minify(basedir, factors)
print( 'Done with imgs2poses' )
return True
修改文件后,再次运行脚本:
conda activate llff
python imgs2poses.py data/nerf_ffll_data/llfftest
出现如下界面,则表明成功生成文件,并查看llfftest文件下是否有类似的文件。
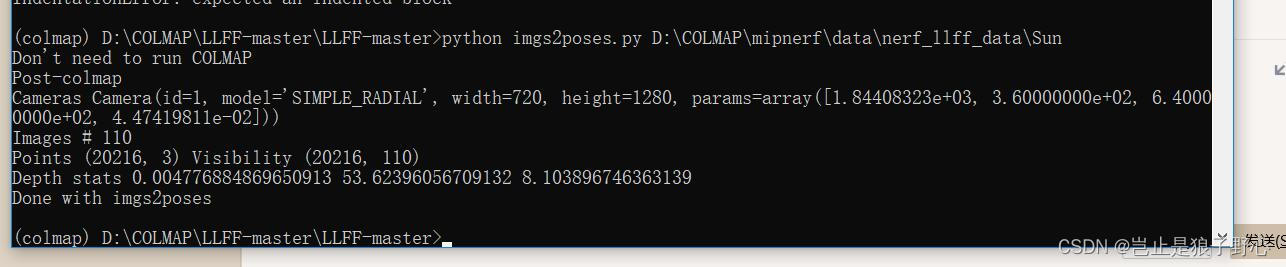
如果完全相同,则表明自己文件数据生成成功,接下来按照博主《三维小菜鸡》的操作进行即可。
输入代码:
conda activate nerf
python run_nerf.py --config configs/llfftest.txt
如果遇到了问题:
(nerf) D:\desk\nerf-pytorch-master\nerf-pytorch-master>python run_nerf.py --config configsfftest.txt
Minifying 8 ./data/nerf_llff_datafftest
'cp' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
Traceback (most recent call last):
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\run_nerf.py", line 879, in <module>
train()
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\run_nerf.py", line 541, in train
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\load_llff.py", line 246, in load_llff_data
poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\load_llff.py", line 76, in _load_data
_minify(basedir, factors=[factor])
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\load_llff.py", line 45, in _minify
check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True)
File "D:\anaconda3\envs\nerf\lib\subprocess.py", line 424, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "D:\anaconda3\envs\nerf\lib\subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command 'cp ./data/nerf_llff_datafftest\images/* ./data/nerf_llff_datafftest\images_8' returned non-zero exit status 1.
或者问题:
(nerf) D:\desk\nerf-pytorch-master\nerf-pytorch-master>python run_nerf.py --config configsfftest.txt
Mismatch between imgs 118 and poses 105 !!!!
Traceback (most recent call last):
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\run_nerf.py", line 879, in <module>
train()
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\run_nerf.py", line 541, in train
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
File "D:\desk\nerf-pytorch-master\nerf-pytorch-master\load_llff.py", line 246, in load_llff_data
poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x
TypeError: cannot unpack non-iterable NoneType object.
则表明,对于图片的使用方式有问题,其中第一个报错是windows没有cp指令,第二个报错是images_8中的文件数目和COLMAP的视角数目不匹配。
对于第一种错误,使用博主《三维小菜鸡》提供的代码即可解决,但对于第二种问题,需要根据之前产生的view_imgs.txt文件进行删除images_8中的多于图片:
import os
# 指定包含图像的文件夹和包含文件名的文本文件
image_folder = "images_8"
txt_file = "view_imgs.txt"
# 读取文本文件中的图像文件名
with open(txt_file, "r") as file:
lines = file.readlines()
image_names = [line.strip() for line in lines]
# 获取文件夹中的所有图像文件
all_images = os.listdir(image_folder)
# 找出不在文本文件中的图像文件
images_to_delete = [image for image in all_images if image not in image_names]
# 删除不在文本文件中的图像文件
for image in images_to_delete:
image_path = os.path.join(image_folder, image)
os.remove(image_path)
print(f"已删除: {image}")
print("已删除所有不在文本文件中的图像")
后续输入代码:
conda activate nerf
python run_nerf.py --config configs/llfftest.txt
可以成功运行。
则最终可以实现使用Nerf训练自己的数据集,如有遗漏,后续补充。
















 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











