






马士兵Spring:
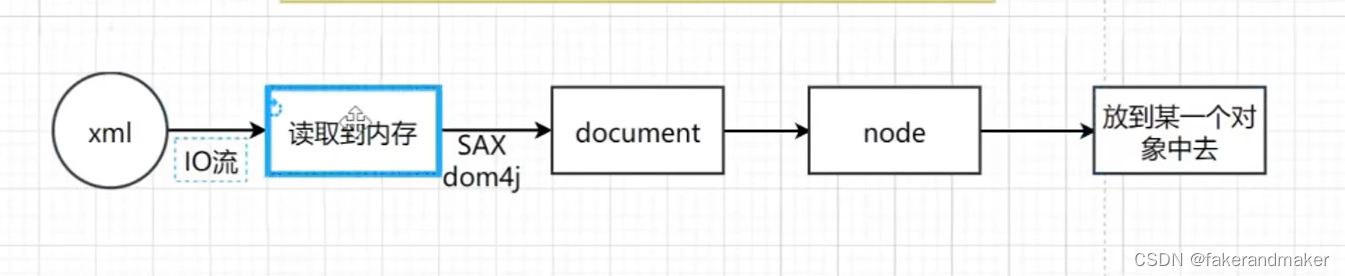
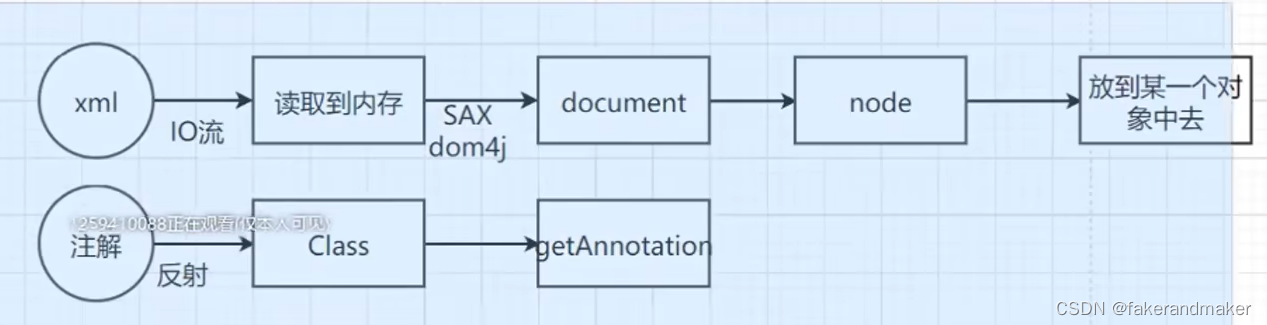
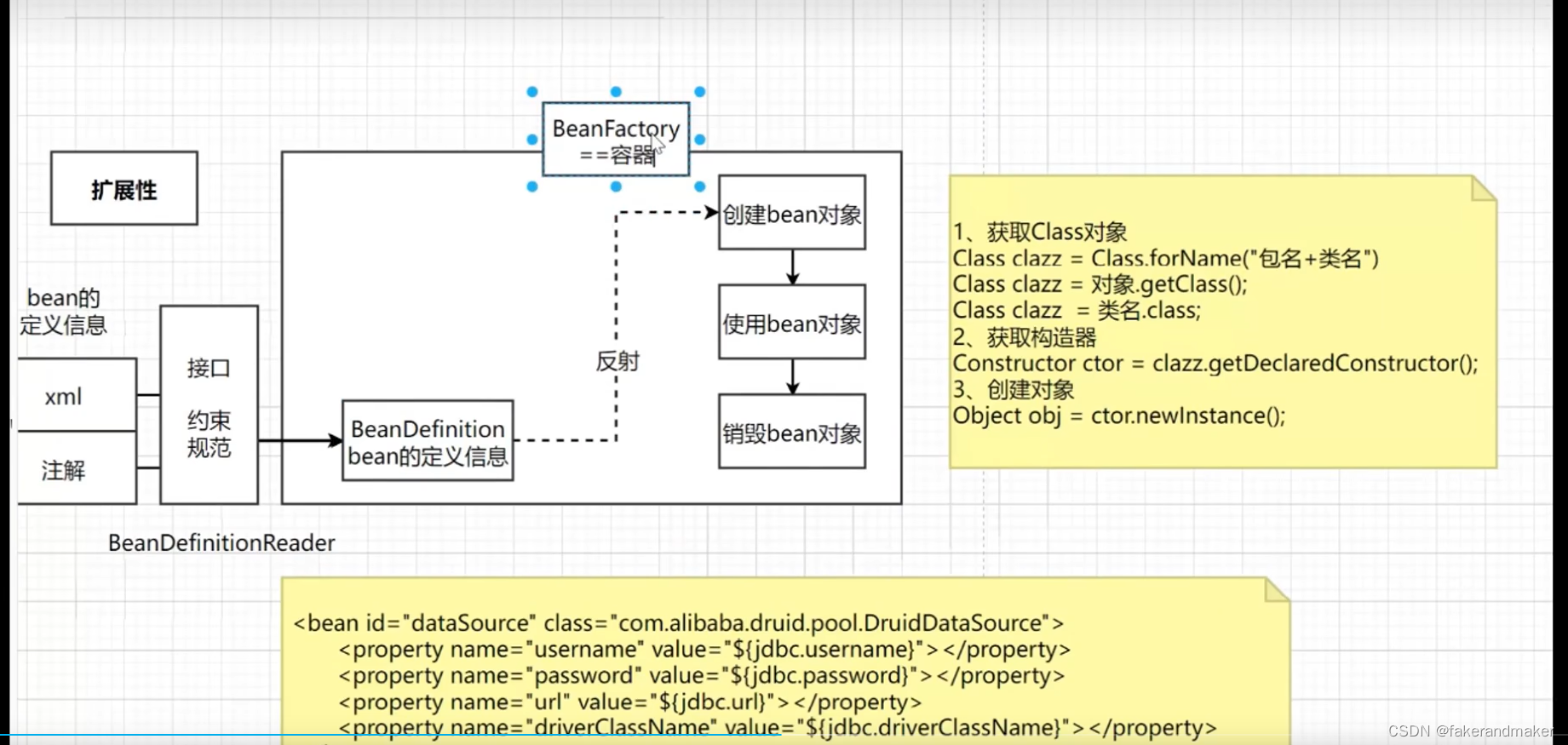
标签下的属性都 在BeanDefinition中,
PostProcessor->后置处理器(增强器)->提供额外的扩展功能->①BeanFactoryProcessor(BeanFactory)②BeanPostProcessor(bean)
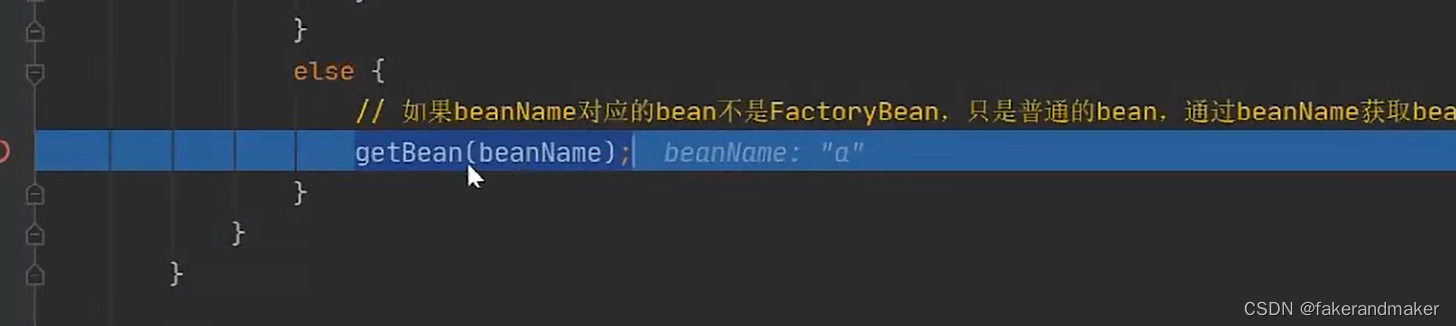
BeanFactory是个factory,也就是IOC容器或对象工厂,FactoryBean是个Bean在Spring中,所有的Bean都是由Factory来管理的。如XMLBeanFactory就是一种典型的BeanFactory。常用的ApplicationContext接口也是由BeanFactory接口派生而来,ApplicationContext包含BeanFactory的所有功能,通常建议比BeanFactory优先。
对FactoryBean而言,这个bean不是简单的Bean,而是一个能生产或装饰对象生成的工厂bean,它为IOC容器中bean的实现提供了更加灵活的方式,可以在getObject()方法中灵活配置。
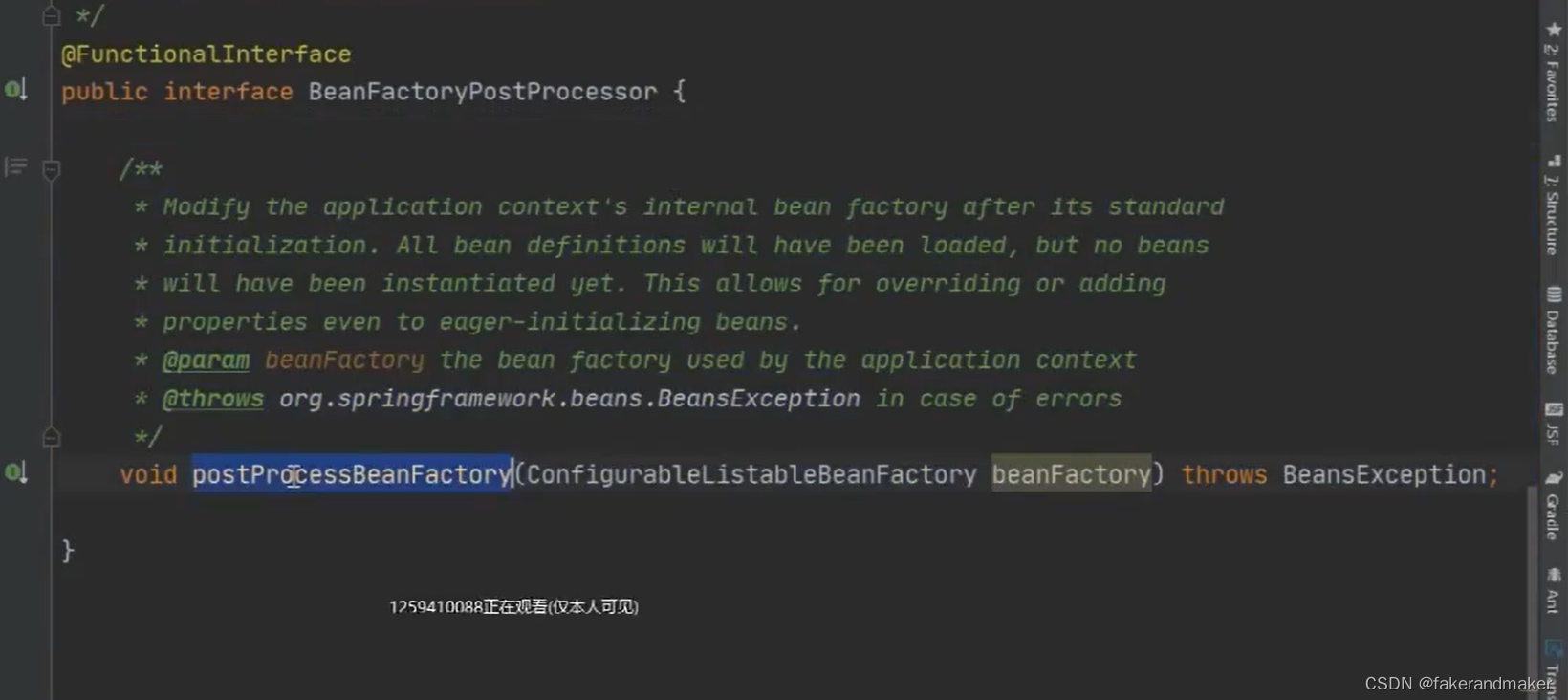
2.BeanFactoryPostProcessor对BeanDefinition进行修改
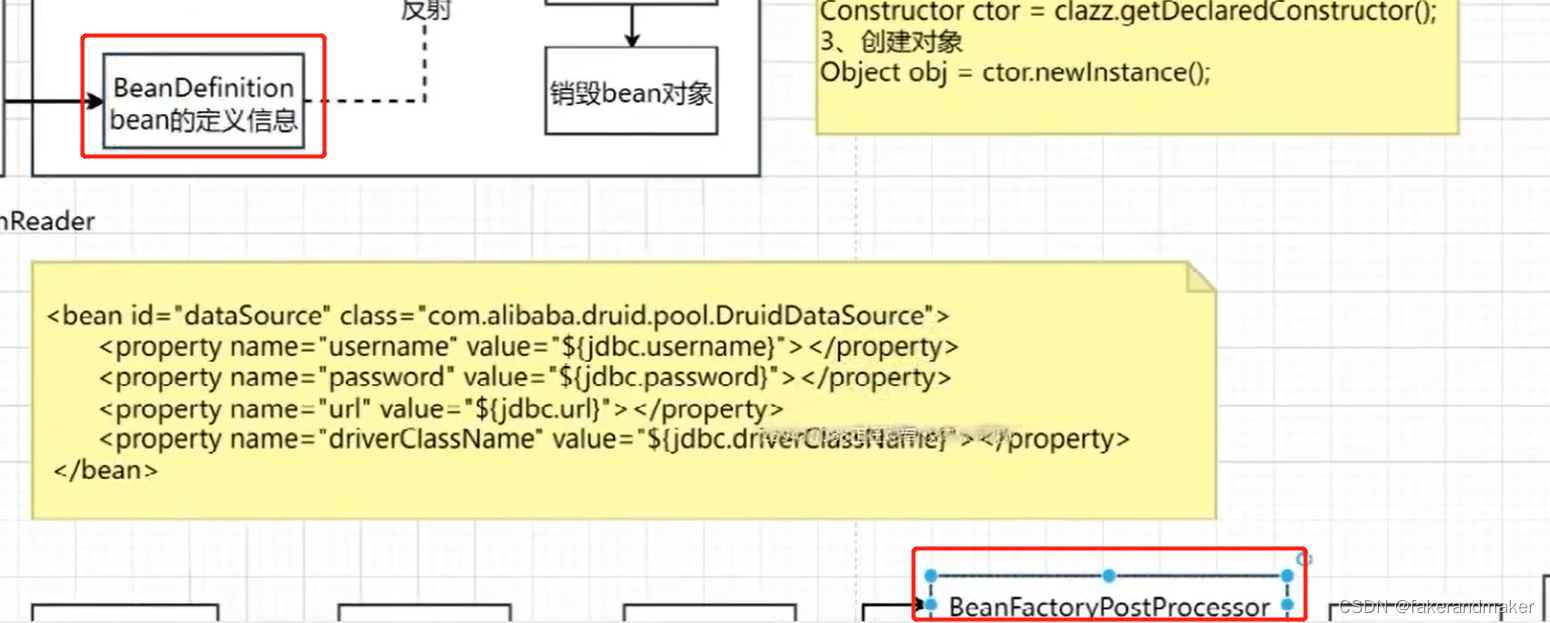
postProcessBeanFactory
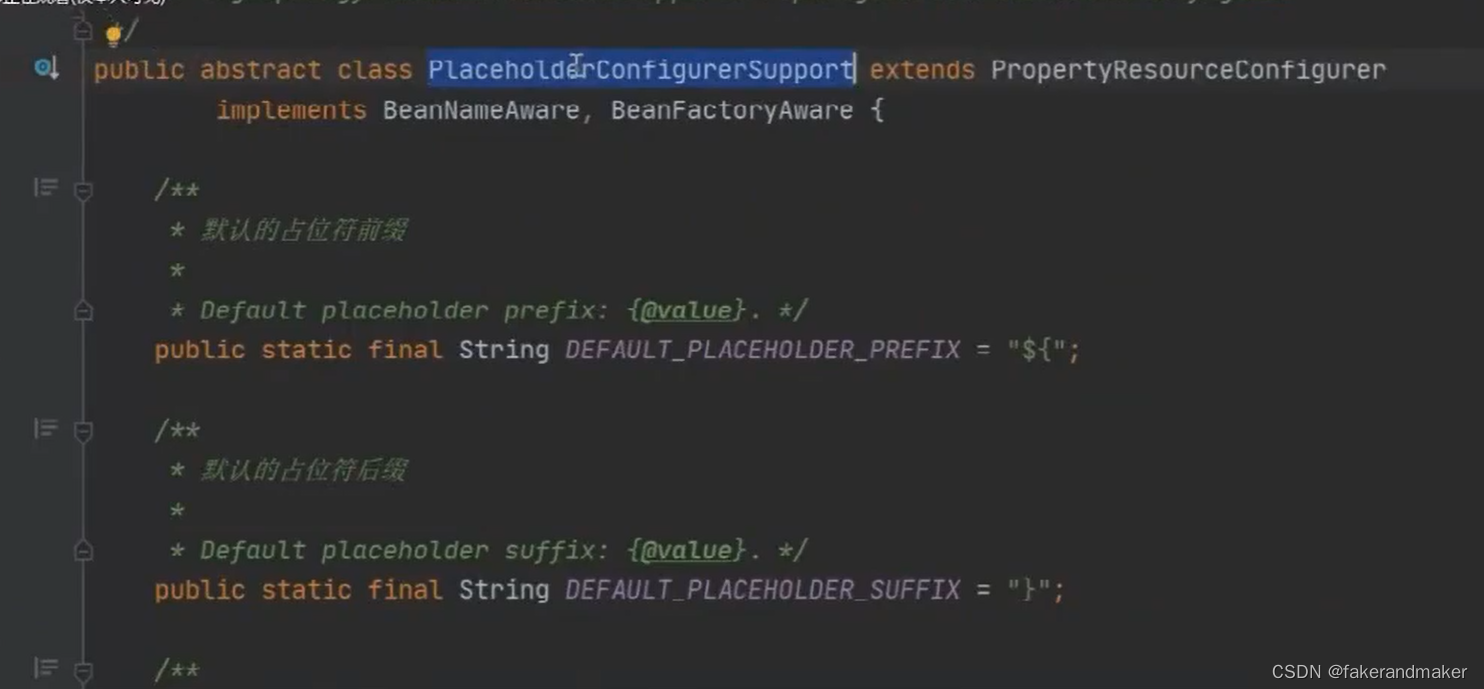
下面有一个子类实现:
PlaceholderConfigrationSupport
抽象基础类通过此类将xml文件替换占位符
 验证工作:
验证工作:
ApplicationAbstract类的refresh方法
postProcessBeanFactory(beanFactory) 此处还只是一个占位符
invokeBeanFactoryPostProcessors(beanFactory)
xml->标准的解析处理流程
注解->是推倒重写,还是在原来的基础上做扩展
ConfigurationClassPostProcessorImplementsBeanDefinitionRegistryPostProcessor
生命周期:从对象的创建到使用销毁的过程
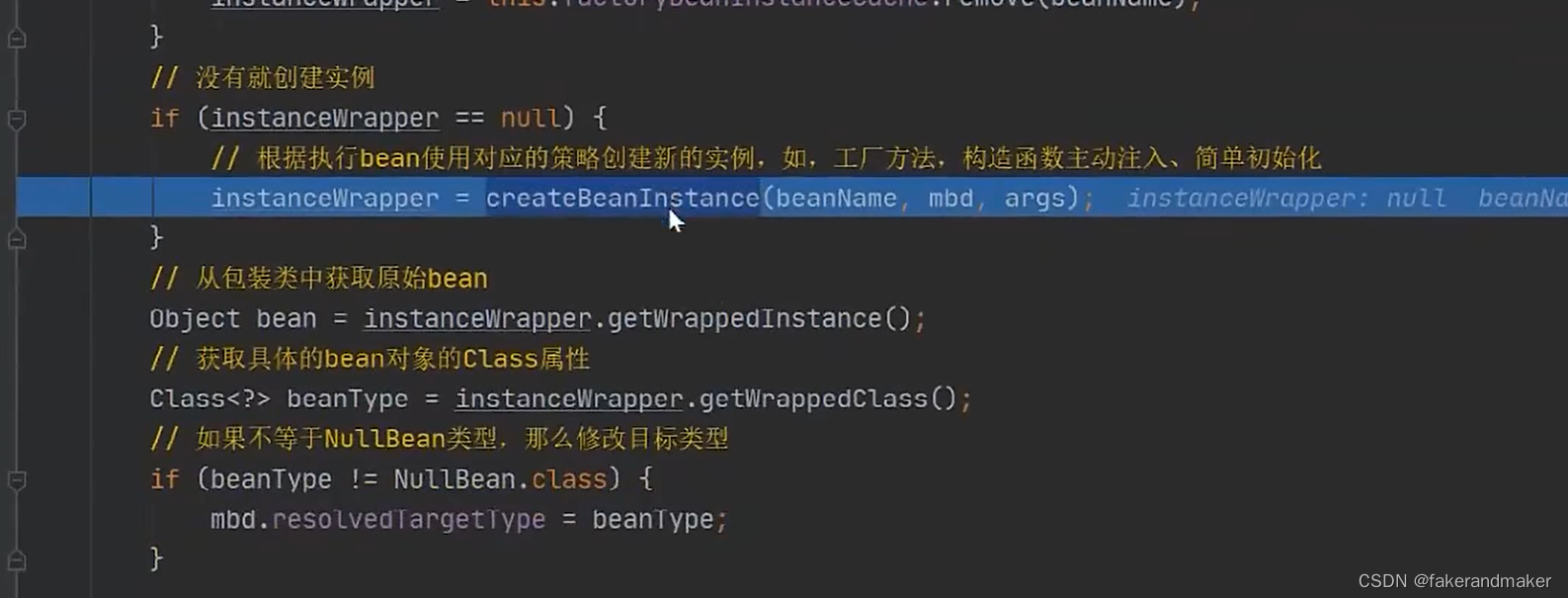
①实例化:在堆空间中申请空间,对象的属性值一般是默认值反射创建对象的过程–》createBeanInstance
②初始化:自定义属性赋值-----》populateBean(set方法完成赋值操作)
③检查aware相关接口并设置依赖–》容器对象属性赋值–》invokeAwareMethods
***********执行到此步骤之后,对象的创建和属性的赋值都完成了,那么此时对象是否可以直接拿来使用了?理论上是可以的,但是注意spring要考虑扩展性。
question:获得普通对象是否需要扩展
执行前置处理方法----》BeanPostProcessor【【【AOP】】】】】动态代理【jdk,cglib】
invokeinitMethods
检测 bean是否实现了initialzingBean接口 ,调用afterPropertiesSet方法,可以在该方法中//设置属性//调用方法//添加任意的处理逻辑
执行后置处理方法----》AOP是IOC整体流程中的一个扩展点
④使用bean对象
⑤销毁bean对象
spring中的bean对象按照使用者分为几类: ①自定义对象 ②容器对象 eg:BeanFactory,ApplicationContext Environment
//谁在什么时候调用这些方法
//容器
//需要给出一个统一的标识,然后在统一的地方进行处理
setBeanFactory()
三、BeanFactory:并不是指根接口,而是bean对象创建的整体流程,Bean的生命周期是一个完整的标准花的流程,相对比很麻烦
FactoryBean:用来创建Bean对象
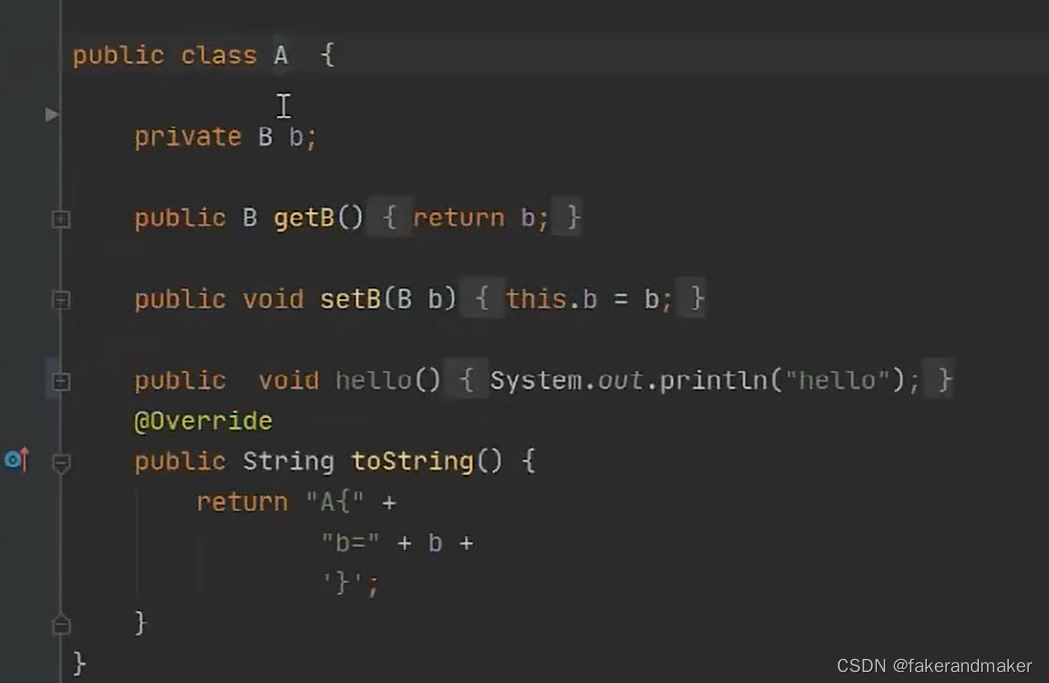
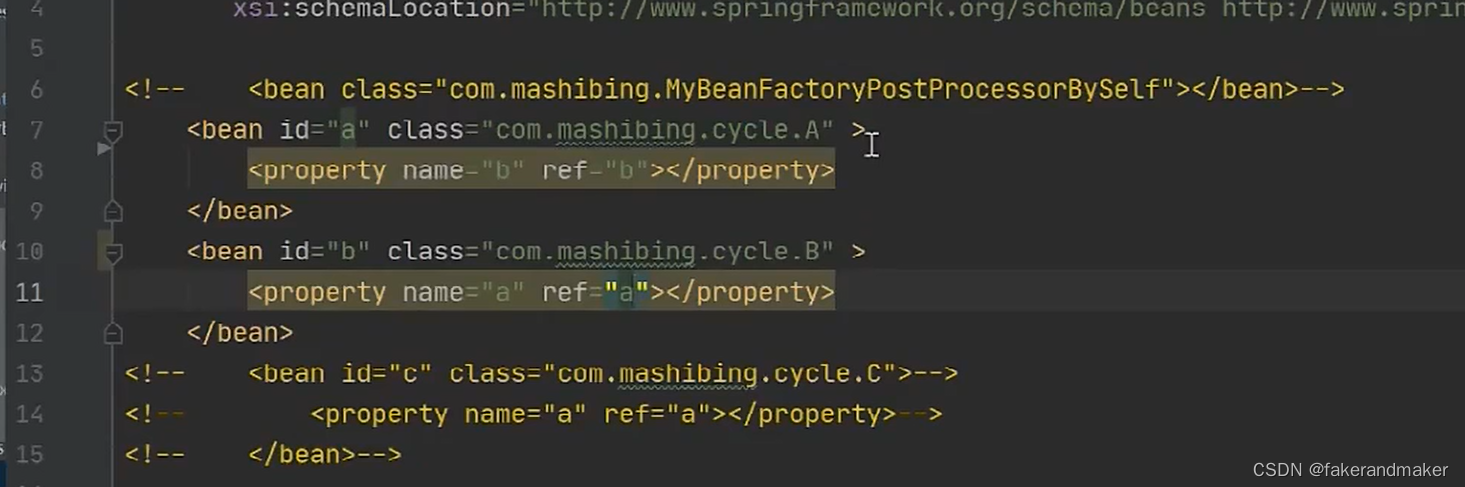
四、循环依赖
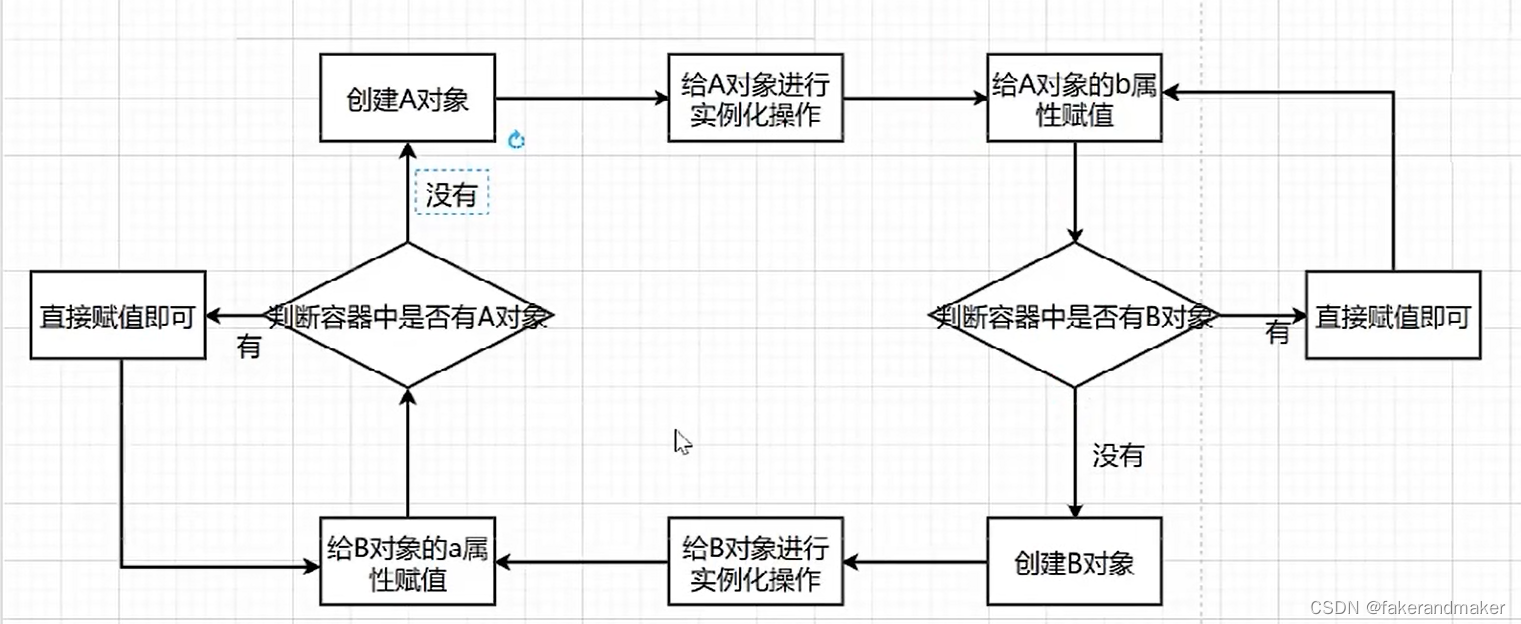
将对象按照状态来分类①成品(完成实例化和初始化)②半成品(完成实例化但未完成初始化)
当持有了某一个对象的引用之后,能否在后续步骤的时候给对象进行赋值操作
ObjectFactory:函数式接口,可以将lambda表达式作为参数放到方法的实参中,在方法执行的时候,并不会实际的调用当前的lambda表达式,只有在调用getObject方法的时候才会去调用lambda表达式。
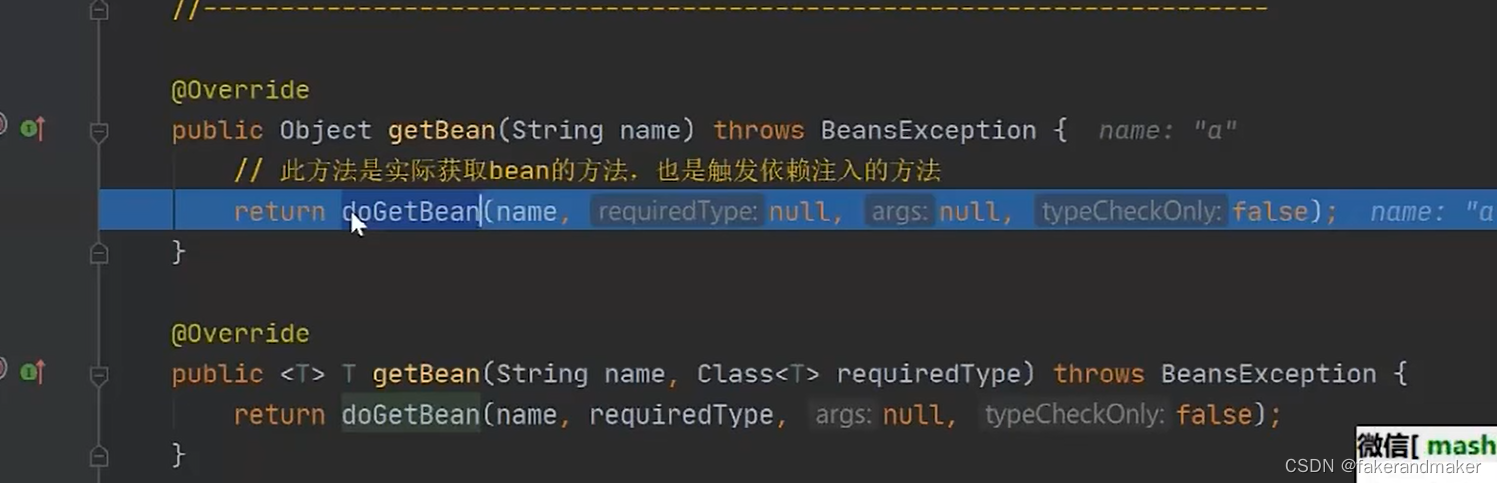
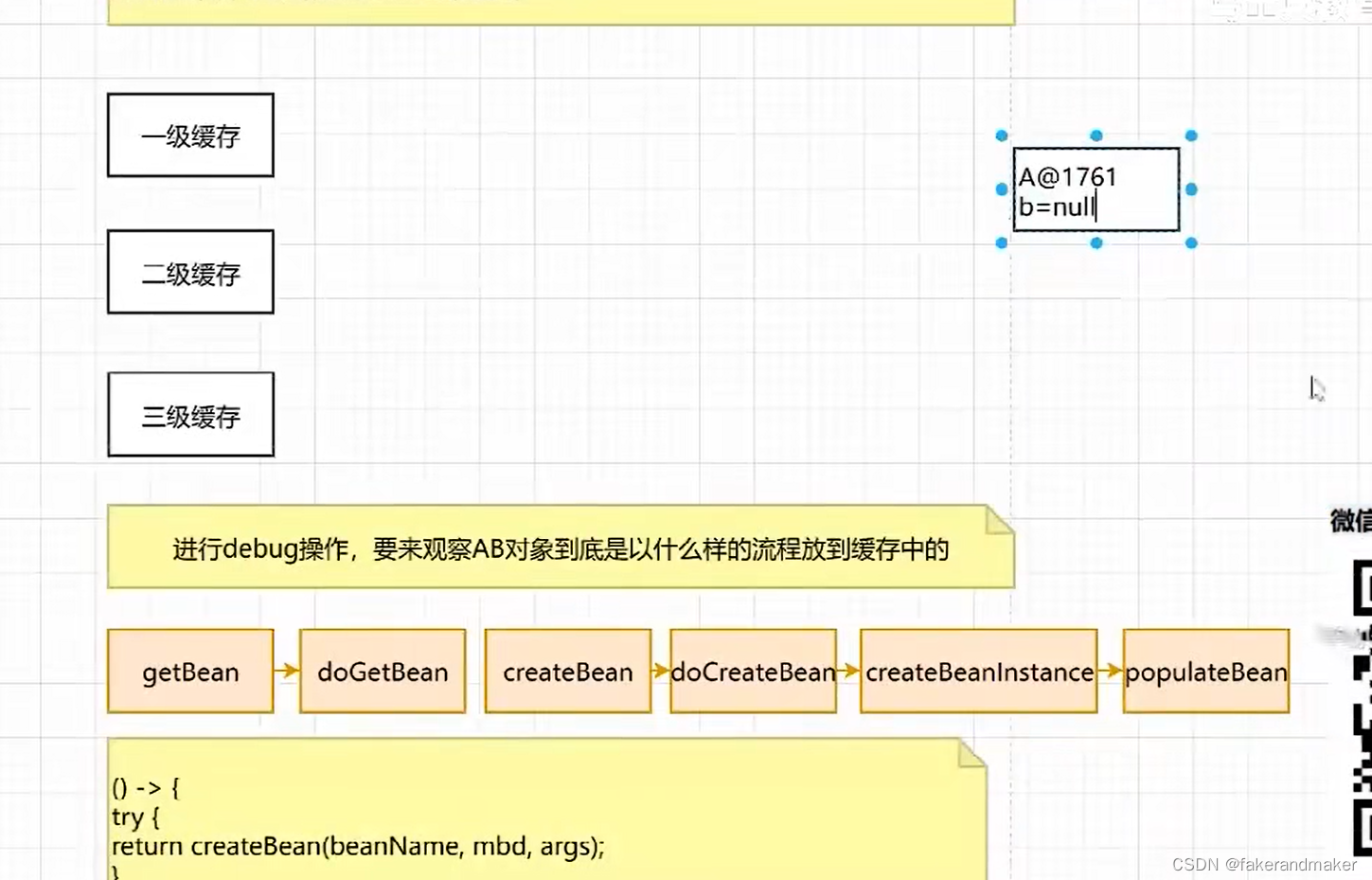
getBean-dogetBean-createBean-doCreateBean-createBeanInstance-popularBean
abstractApplicationContext类中有个refresh方法,该方法中有finishBeanFactoryInitialization(beanFactory)方法进行具体创建bean,该方法中有传递参数有一个beanFactory,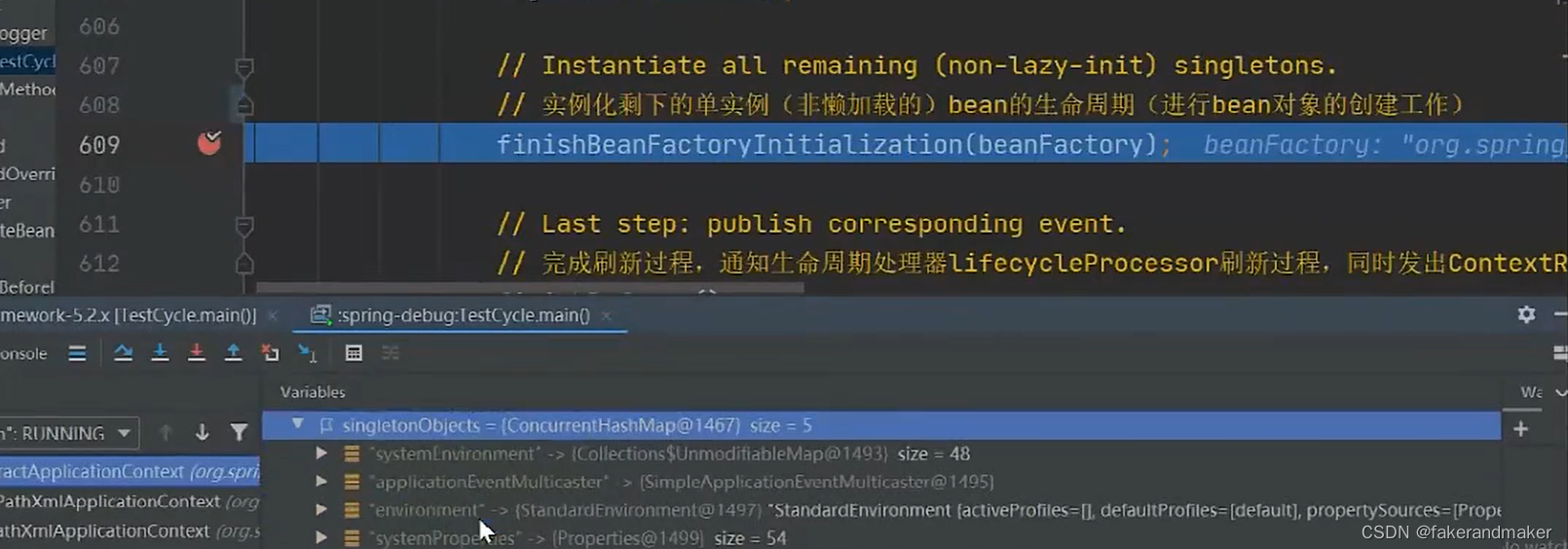
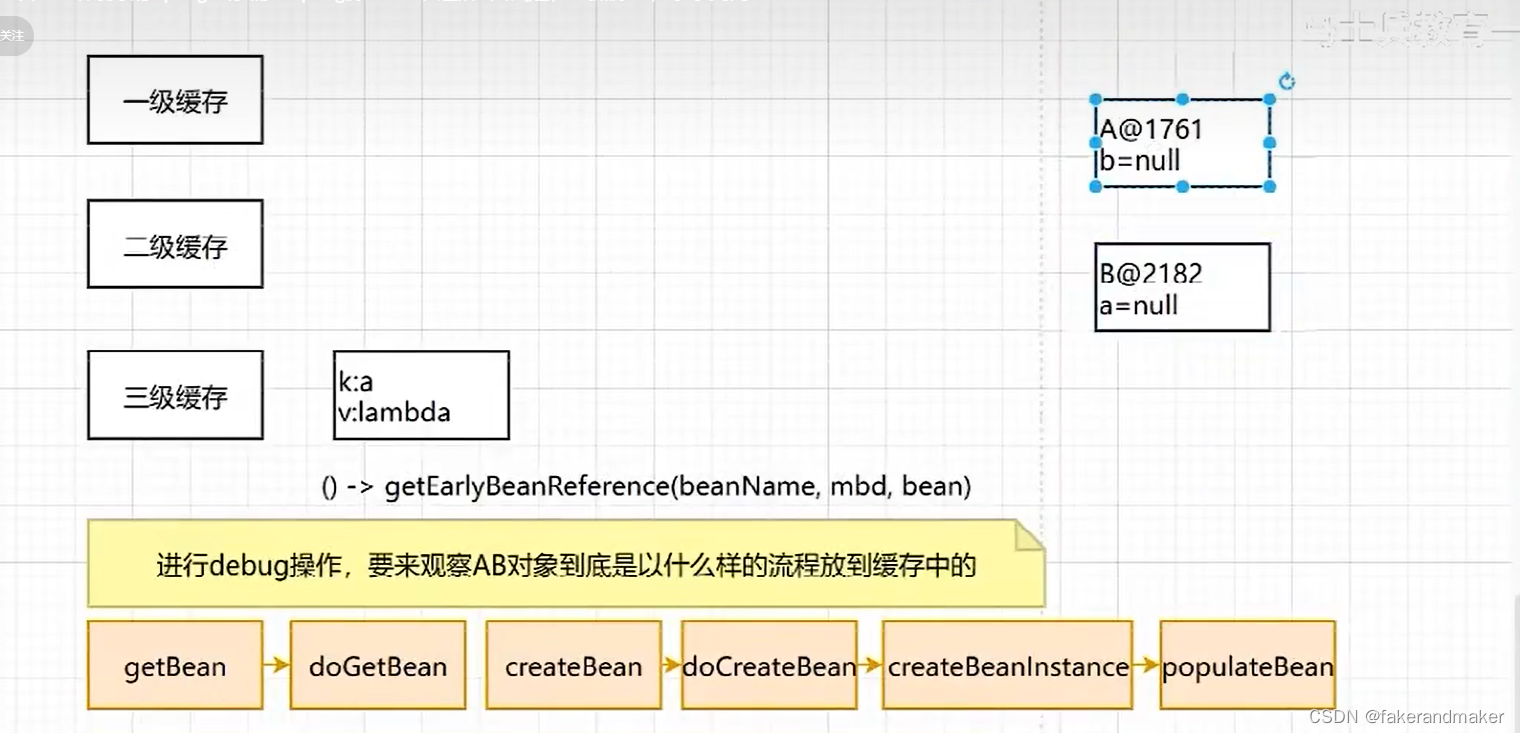
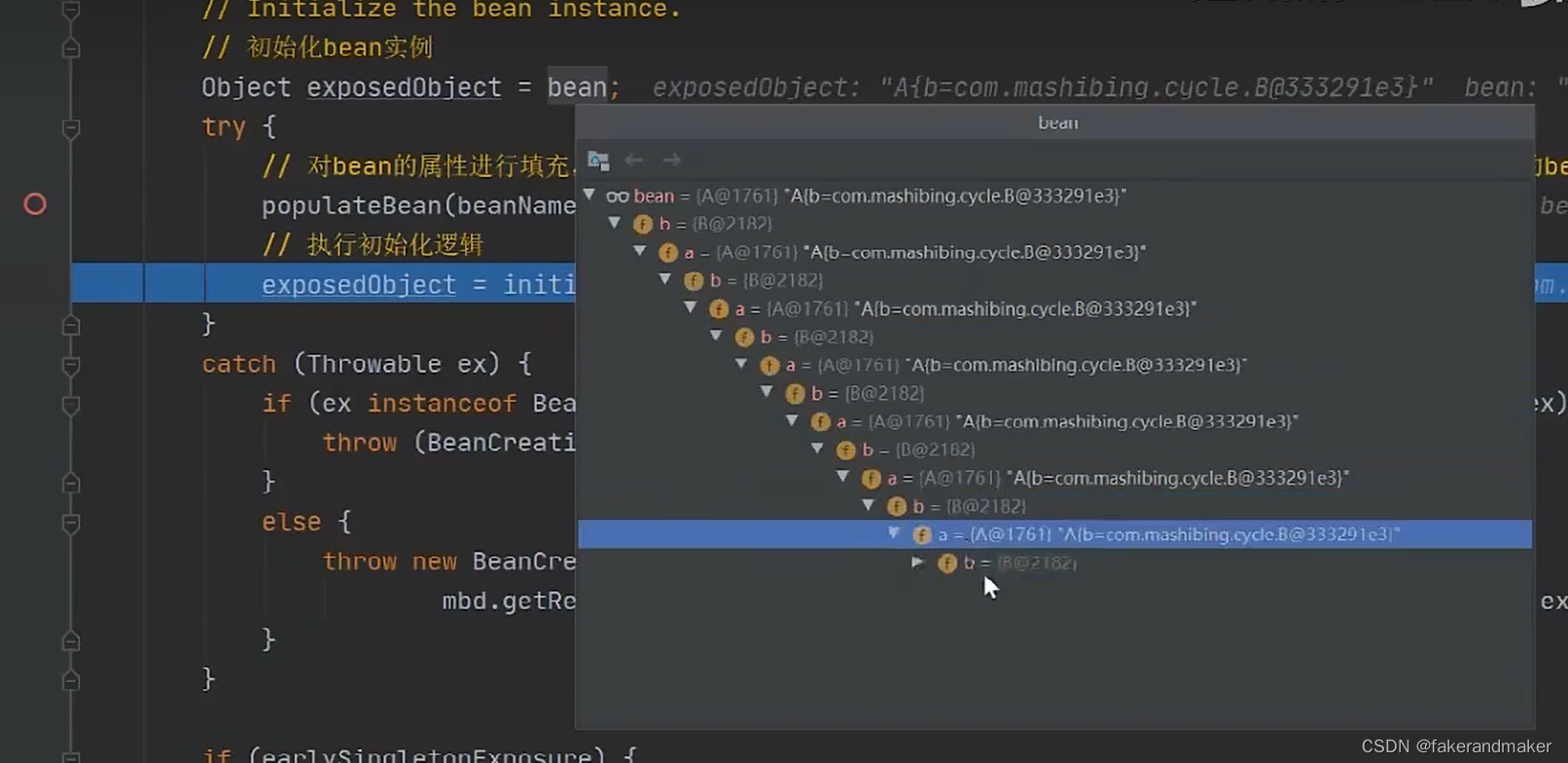
此时singleOBject中没有AB对象,有五个其他对象,earlySingletonObject里面有0个,singletonFactories里面有0个,
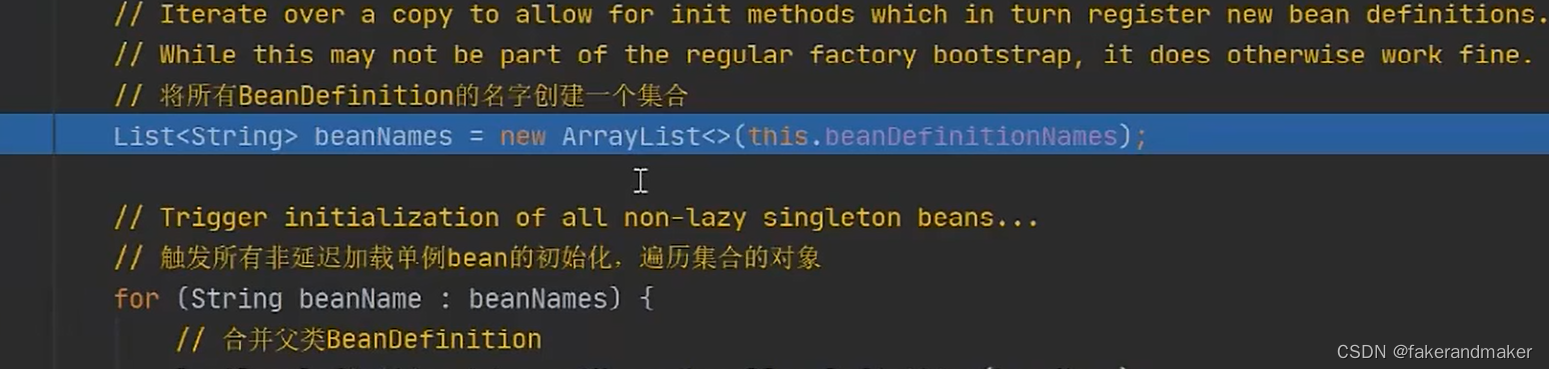
此时
cis




实际创建对象
 反射创建对象
反射创建对象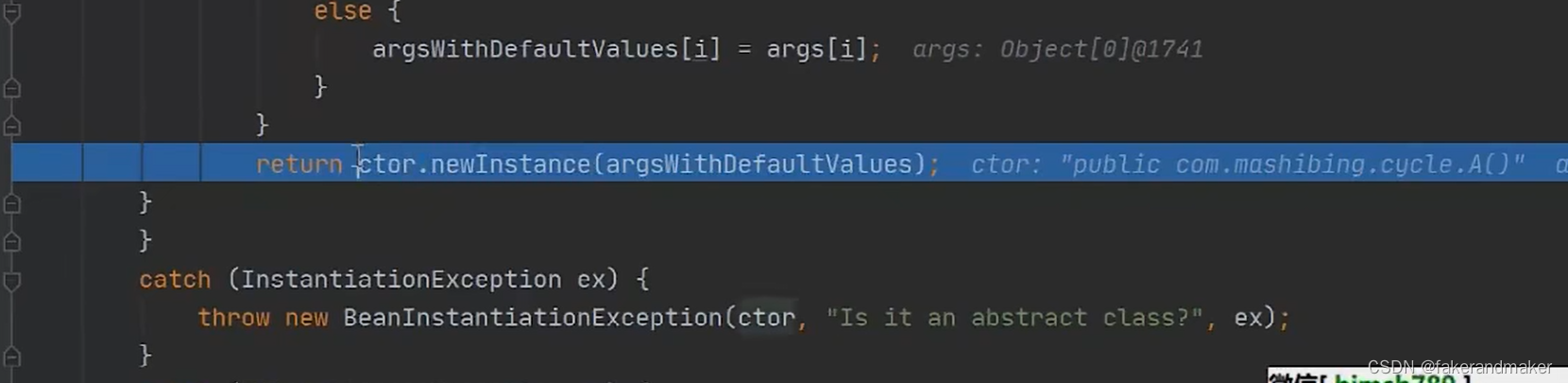
此时B为空
开始套娃
 创建完B对象
创建完B对象
此时A,B对象
此时三级缓存都有
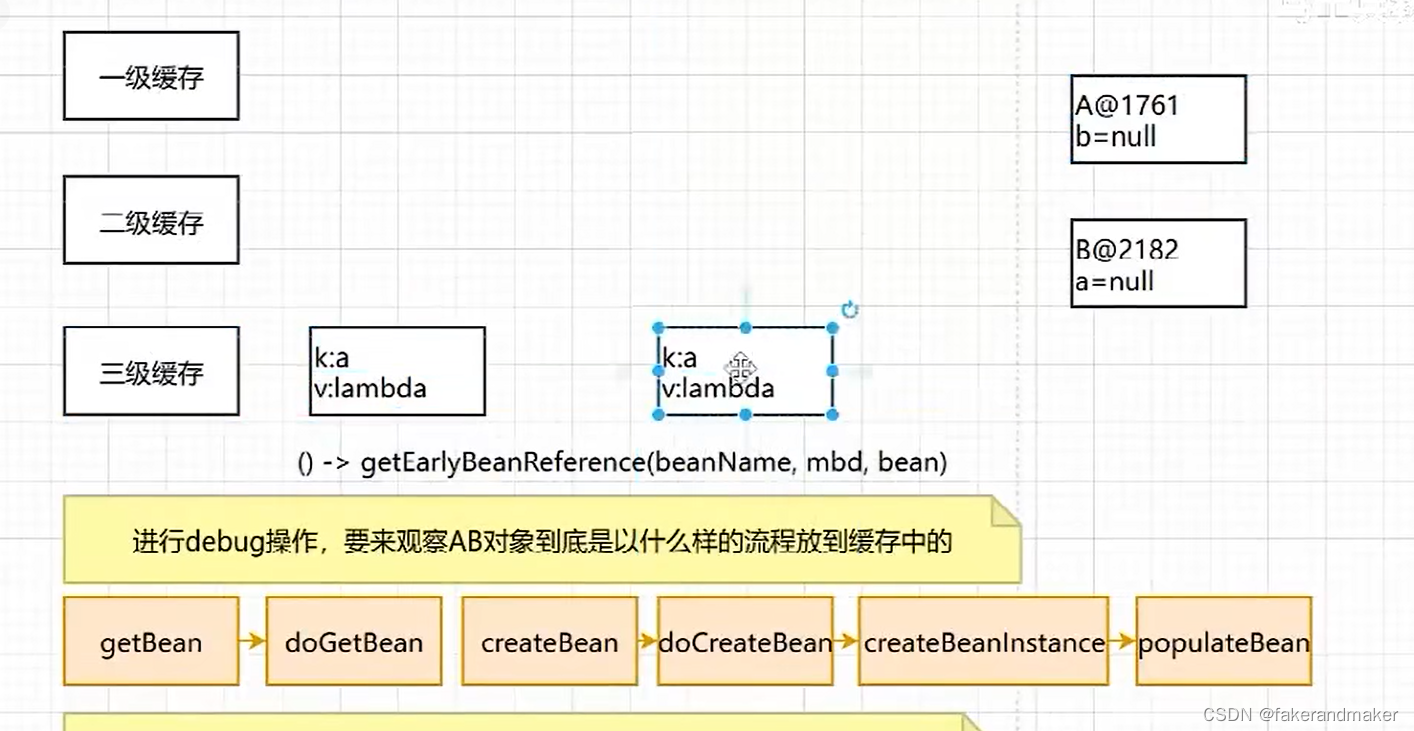
第三遍:getBean
放到二级缓存中
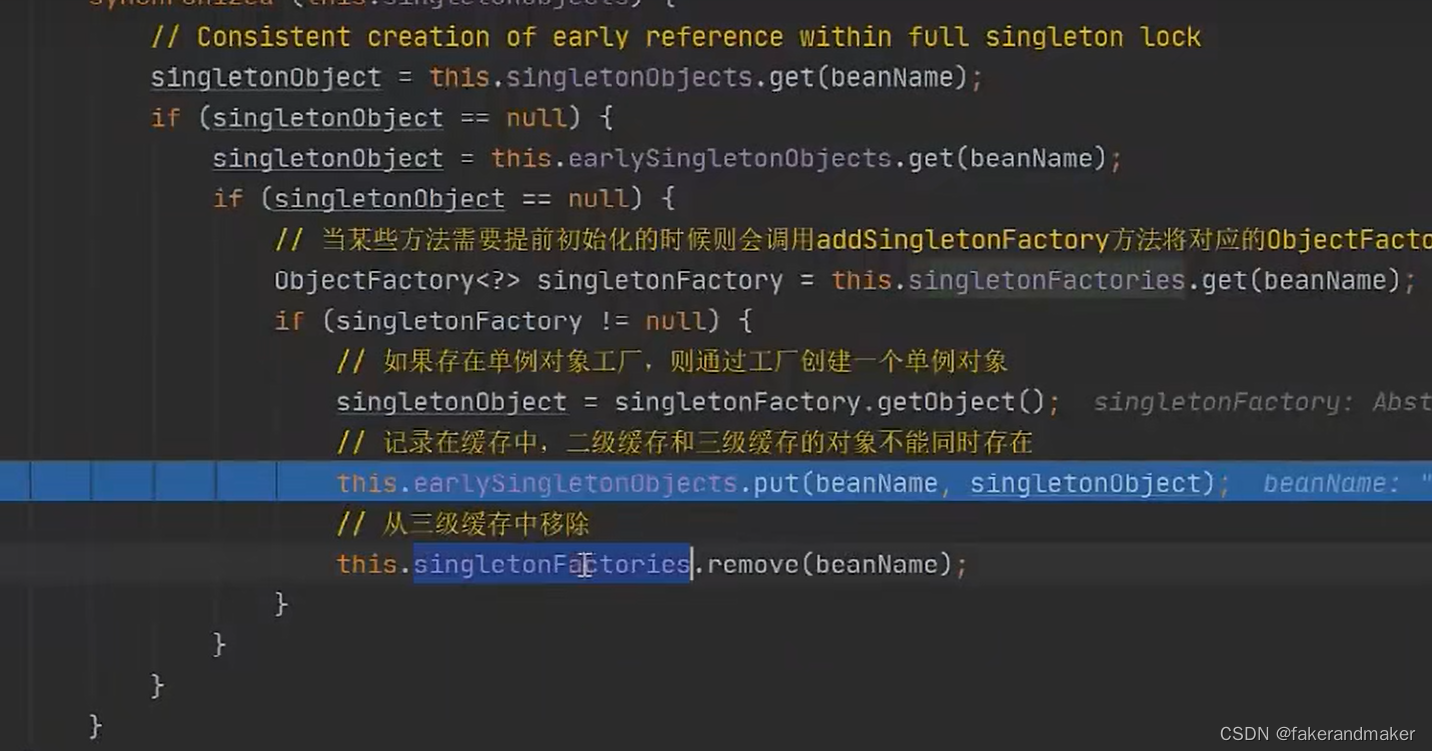
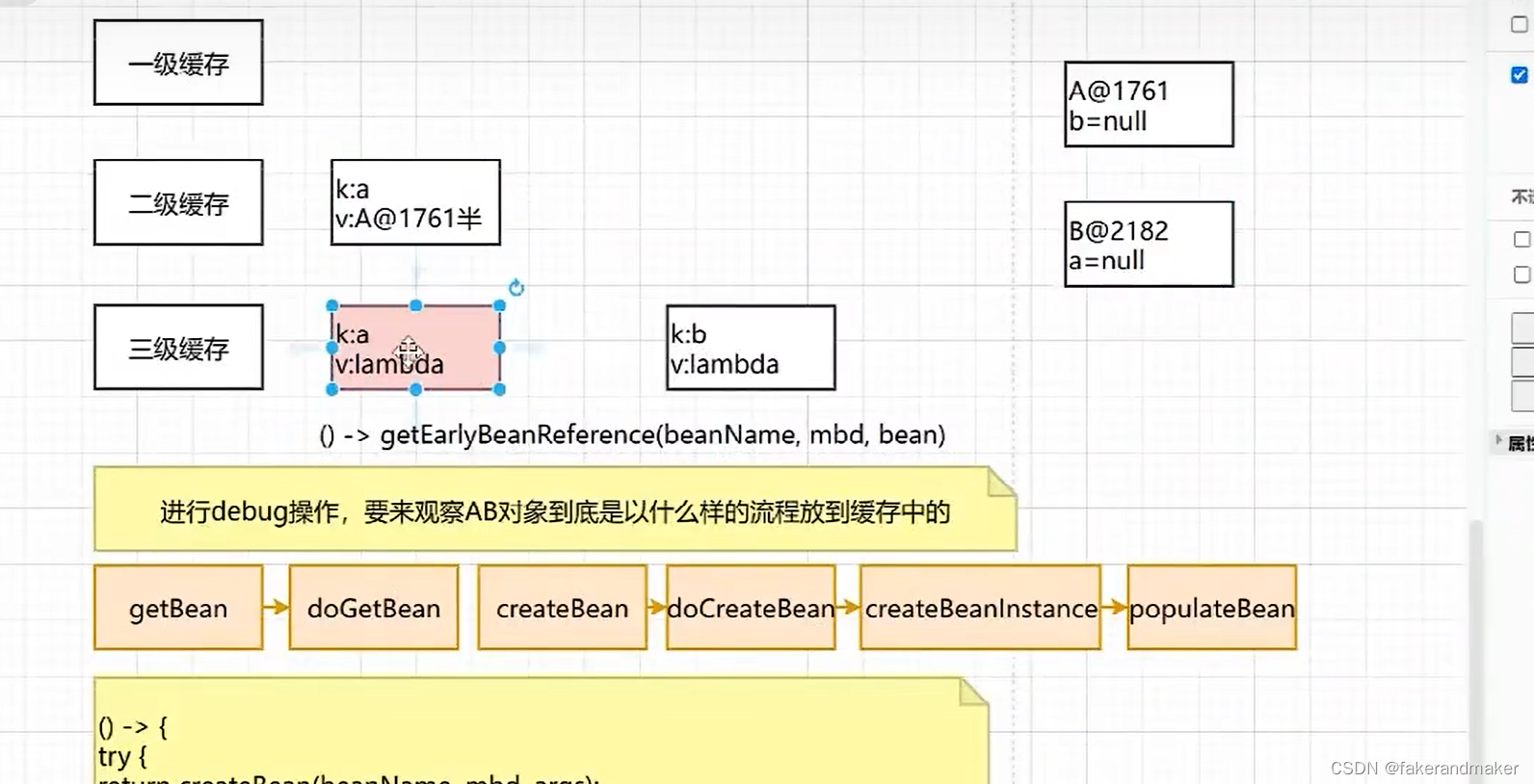
接着给B对象的A属性赋值
将b从三级缓存放到一级缓存中作为成品对象
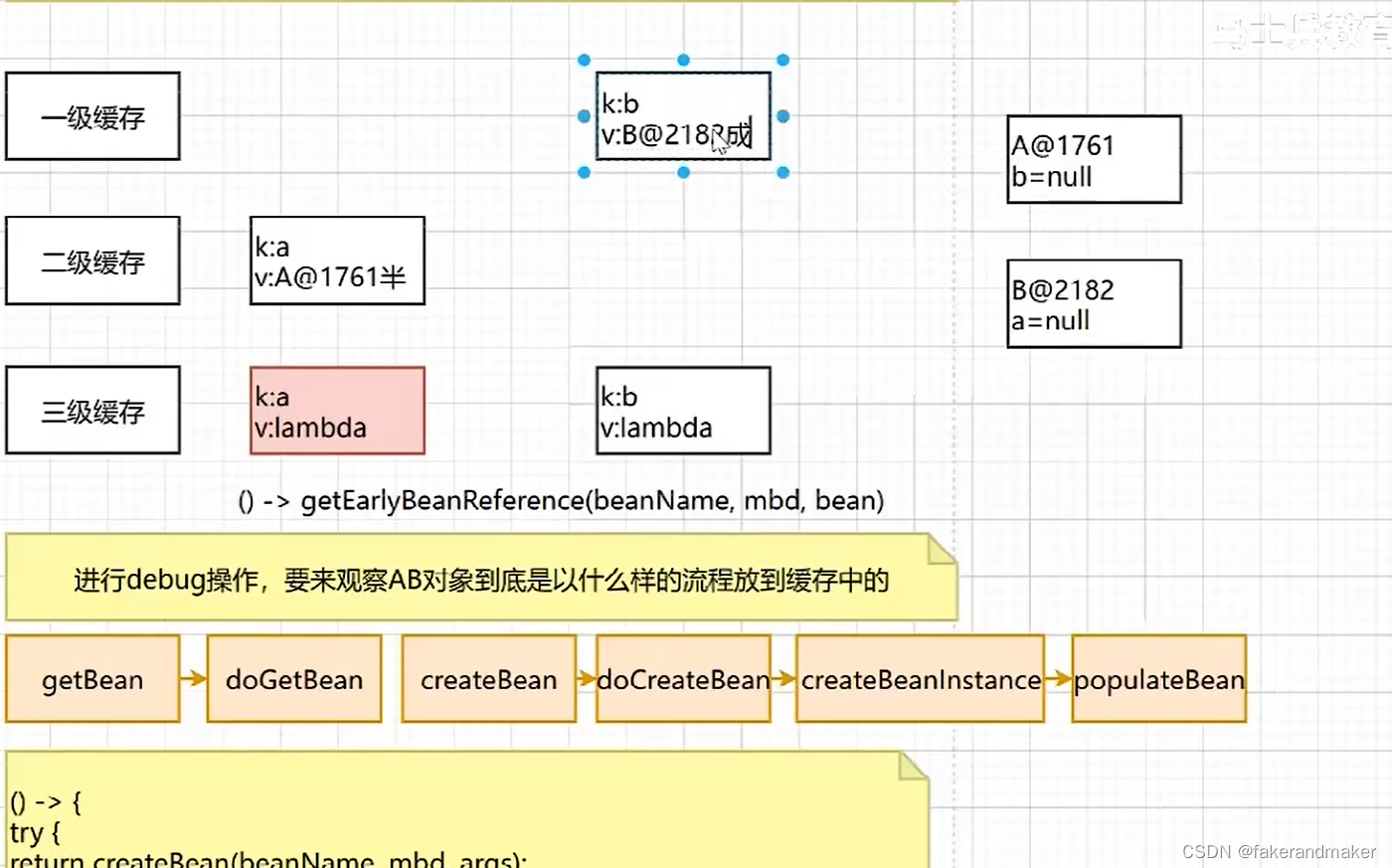
再通过此方法把B对象赋值给A,将A变为成品对象

结果:
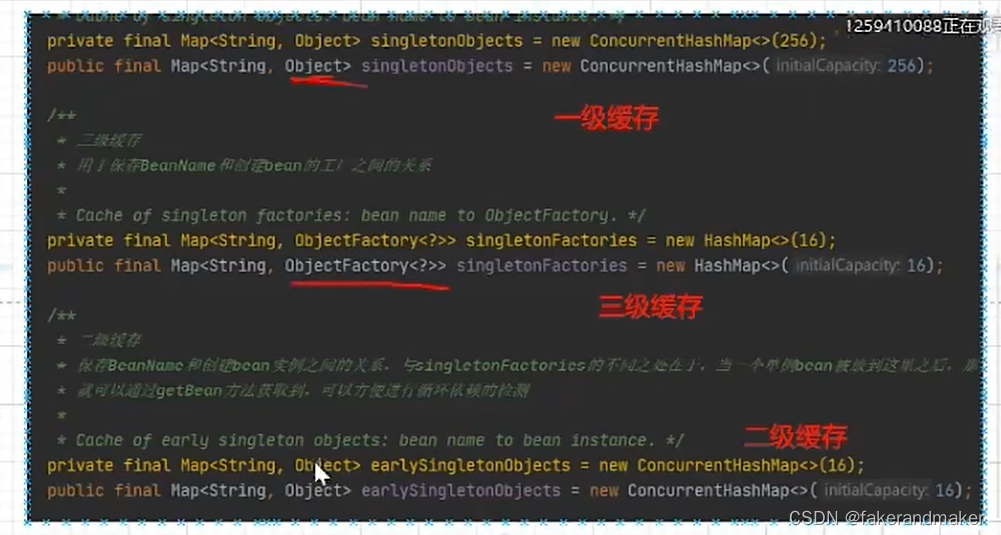
1.三级缓存结构map分别存储什么类型的对象
一级缓存:成品
二级缓存:半成品
三级缓存:lambda表达式
2.三个map结构在进行对象查找的时候,顺序是什么样的?
1,2,3
3.如果只有一个map结构,能解决循环依赖问题吗?
理论上可行,实际上没人这么干,使用两个map的意义在于将成本对象和半成品对象进行区分,半成品对象是不能直接暴露给外部对象使用的。可以设置标志位来标识成品还是半成品,但是操作起来比较麻烦,所以直接用两个map即可。
加一个aop之后:会报错
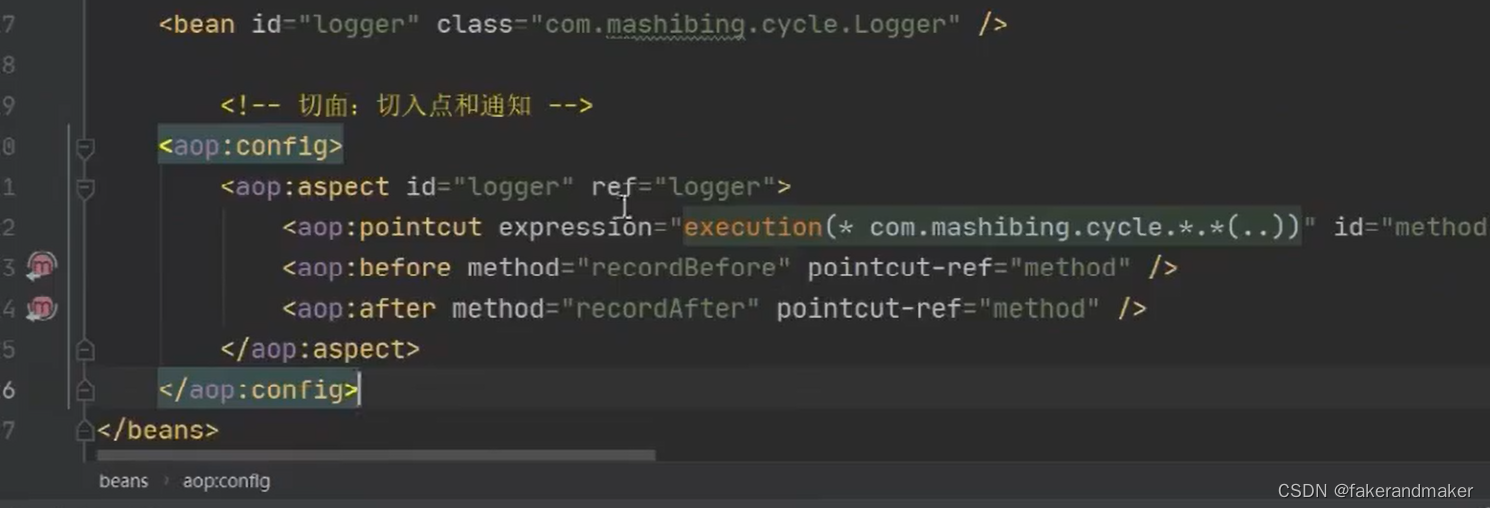

结论:
4.如果只有两个map结构,能解决循环依赖问题吗?
可以解决、但是有前提:没有代理对象的时候,当不使用aop的时候,两个缓存map就可以循环依赖问题。
5.为什么使用三级缓存之后就可以解决带aop的循环引用
①一个容器中能包含同名的两个对象吗?
②对象创建过程中,原始的对象有没有可能需要生成代理对象
③如果创建了代理对象,那么程序在调用的时候到底使用原始对象还是代理对象?应该使用代理对象,但是程序是死的是提前写好的,他怎么知道要选择代理对象呢?所以,当出现代理对象时候,要使用代理对象替换掉原始对象。
④代理对象的创建在初始化过程的扩展阶段,而属性的赋值是在生成代理对象之前执行的,那怎么完成替换呢?
⑤那为什么非要使用lambda表达式的机制来完成呢?
对象在什么时候被暴漏出去或者被其他对象引用是没办法提前确定好好的,所以只有在被调用的那一刻才可以进行原始对象还是代理对象的判断,使用lambda表达式类似于一种回调机制,不暴露的时候不需要调用执行,当需要被调用的时候,才真正的执行lambda表达式,来判断返回的到底是代理对象还是原始对象,















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









