







 本文详细分析了支持向量机(SVM)的SMO算法,包括对偶函数的优化问题、核函数缓存、梯度求解、序列最小化法的约束条件以及优化规则。通过选取规则和权重计算,阐述了如何在[0,C]区间内调整α值,以实现SVM模型的优化。提供了代码地址供参考。"
130956343,6680800,RockyLinux9.2中部署k8s1.27+kubeadm+calico+BGP+OpenELB详细教程,"['kubernetes', '容器', '网络', '负载均衡']
本文详细分析了支持向量机(SVM)的SMO算法,包括对偶函数的优化问题、核函数缓存、梯度求解、序列最小化法的约束条件以及优化规则。通过选取规则和权重计算,阐述了如何在[0,C]区间内调整α值,以实现SVM模型的优化。提供了代码地址供参考。"
130956343,6680800,RockyLinux9.2中部署k8s1.27+kubeadm+calico+BGP+OpenELB详细教程,"['kubernetes', '容器', '网络', '负载均衡']
1.SVM对偶函数最后的优化问题



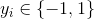
2. 对核函数进行缓存

由于该矩阵是对称矩阵,因此在内存中的占用空间可以为m(m+1)/2
映射关系为:

#define OFFSET(x, y) ((x) > (y) ? (((x)+1)*(x) >> 1) + (y) : (((y)+1)*(y) >> 1) + (x))
//...
for (unsigned i = 0; i < count; ++i)
for (unsigned j = 0; j <= i; ++j)
cache[OFFSET(i, j)] = y[i] * y[j] * kernel(x[i], x[j], DIMISION);
//...3. 求解梯度
既然α值是变量,因此对α值进行求导,后面根据梯度选取α值进行优化。
梯度:
for (unsigned i = 0; i < count; ++i) { gradient[i] = -1; for (unsigned j = 0; j < count; ++j) gradient[i] += cache[OFFSET(i, j)] * alpha[j]; }

若使W最大,则当α减少时,G越大越好。反之,G越小越好。
4. 序列最小化法(SMO)的约束条件
每次选取2个α值进行优化,其它α值视为常数,根据约束条件得:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









