






DIRECTED EXPLORATION FOR REINFORCEMENT LEARNING
总的来说和Go-explore差不多
These uncertainty-based methods use a reward bonus approach, where they compute a measure of uncertainty and transform that into a bonus that is then added into the reward function. Unfortunately this reward bonus approach has some drawbacks. The main drawback is that reward bonuses may take many, many updates before they propagate and change agent behavior.
This is due to two main factors: the first is that function approximation itself needs many updates before converging; the second is that the reward bonuses are non-stationary and change as the agent explores, meaning the function approximator needs to update and converge to a new set of values every time the uncertainties change.
This makes it necessary to ensure that uncertainties do not change too quickly, in order to give enough time for the function approximation to catch up and propagate the older changes before needing to catch up to the newer changes.
RND 里的0.25% mask原来就是干这个用的。
If the reward bonuses change too quickly, or are too noisy, then it becomes possible for the function approximator to prematurely stop propagation of older changes and start trying to match the newer changes, resulting in missed exploration opportunies or even converging to a suboptimal mixture of old and new uncertainties.
Non-stationarity has already been a difficult problem for RL in learning a Q-value function, which the DQN algorithm is able to tackle by slowing down the propagation of changes through the use of a target network [Mnih et al., 2013]. These two factors together result in slow adaptation of reward bonuses and lead to less efficient exploration.
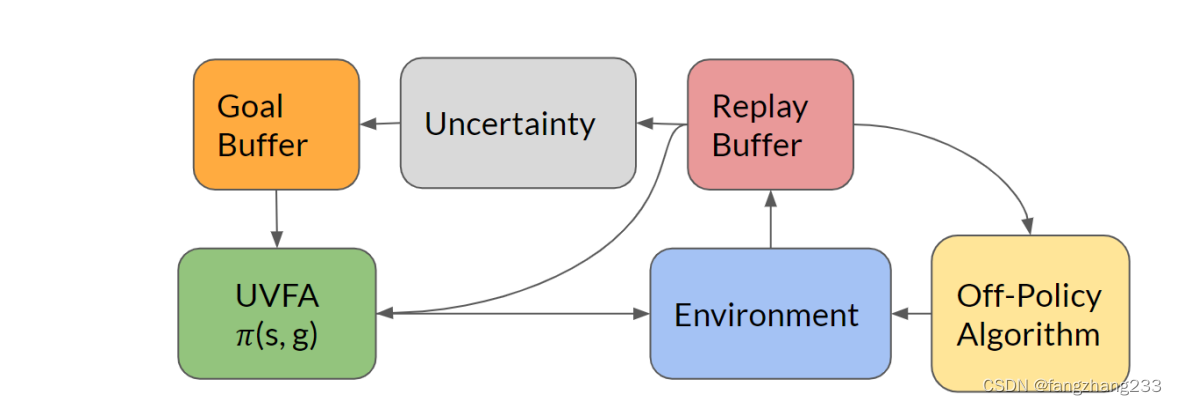
用goal-conditioned policy 因为 This results in an algorithm that is completely stationary, because the goal-conditioned policy is independent of the uncertainty.
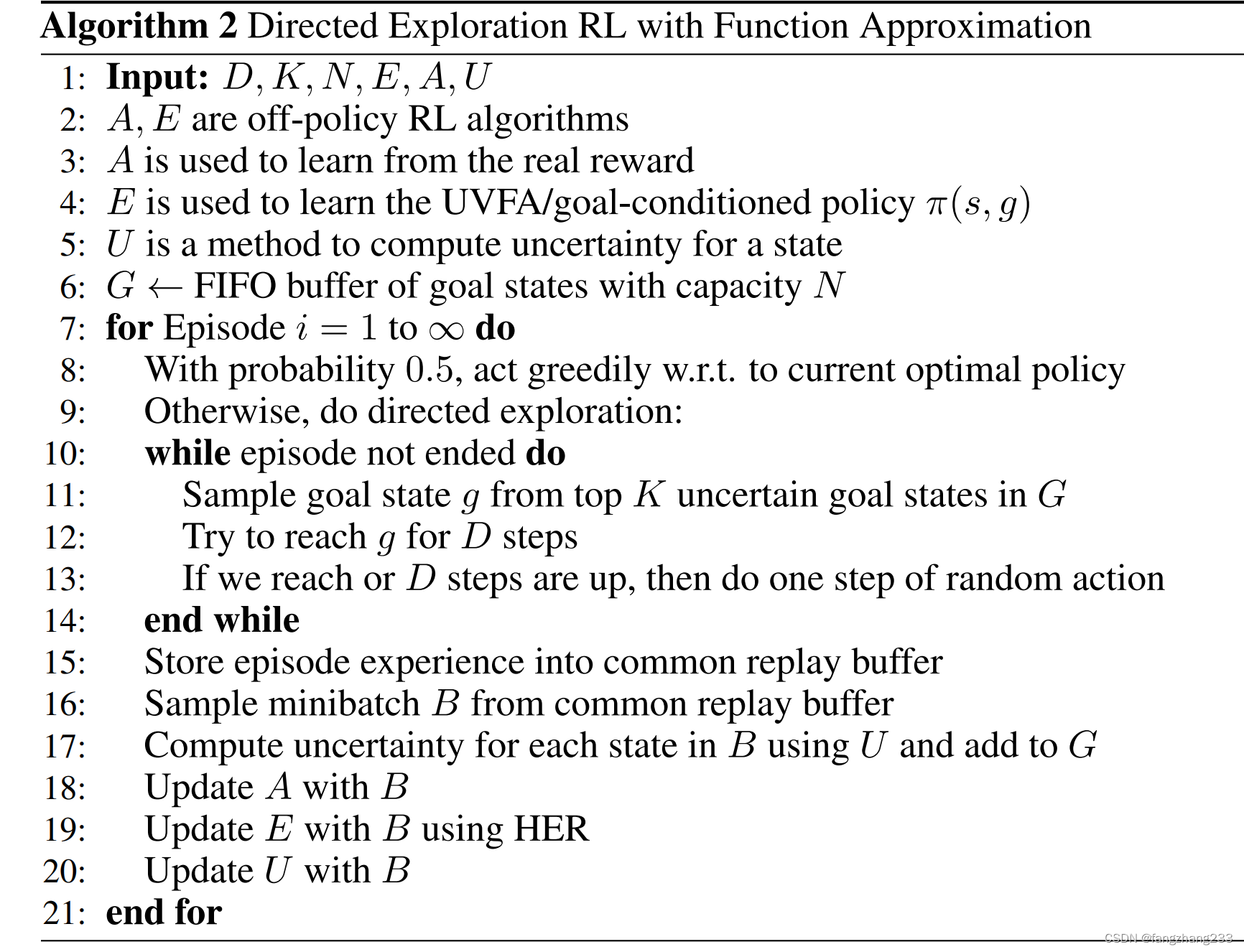
全部算法:

















 28
28











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









