






ON BONUS-BASED EXPLORATION METHODS IN THE ARCADE LEARNING ENVIRONMENT
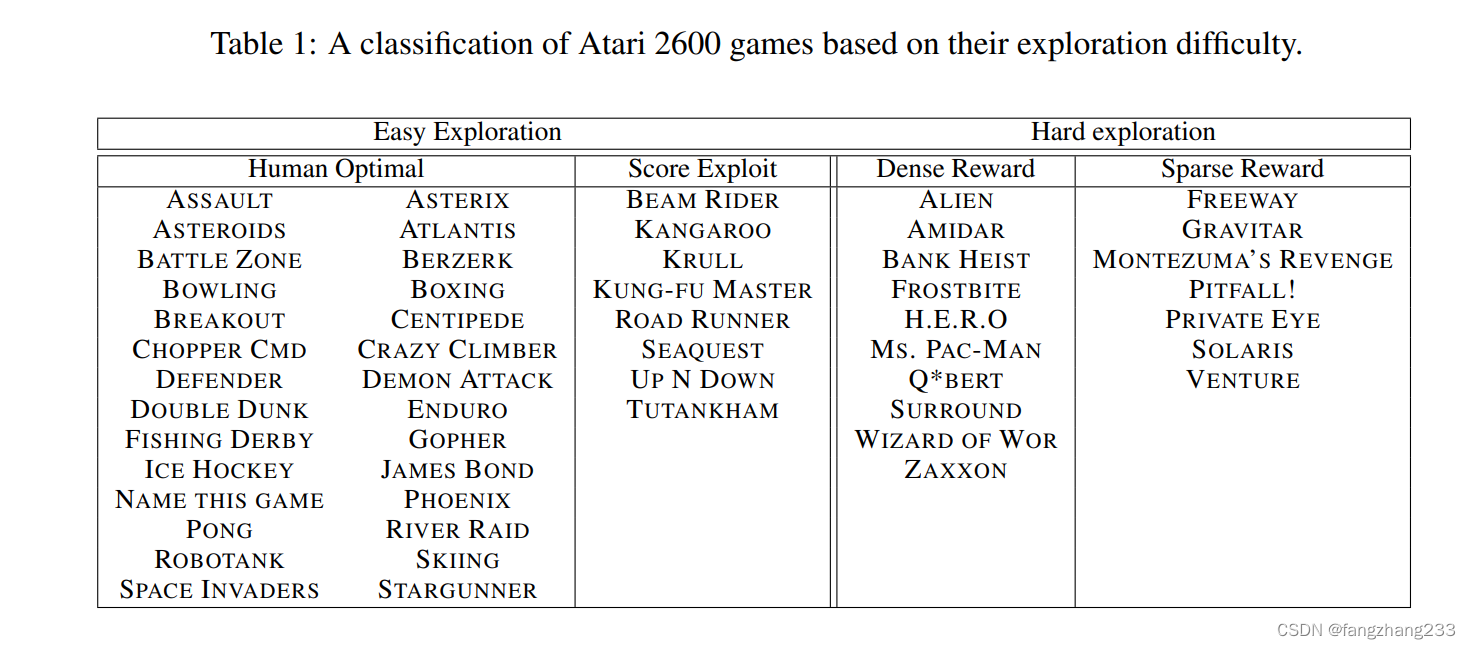
atari里对于游戏的分类,主要关注右边一列
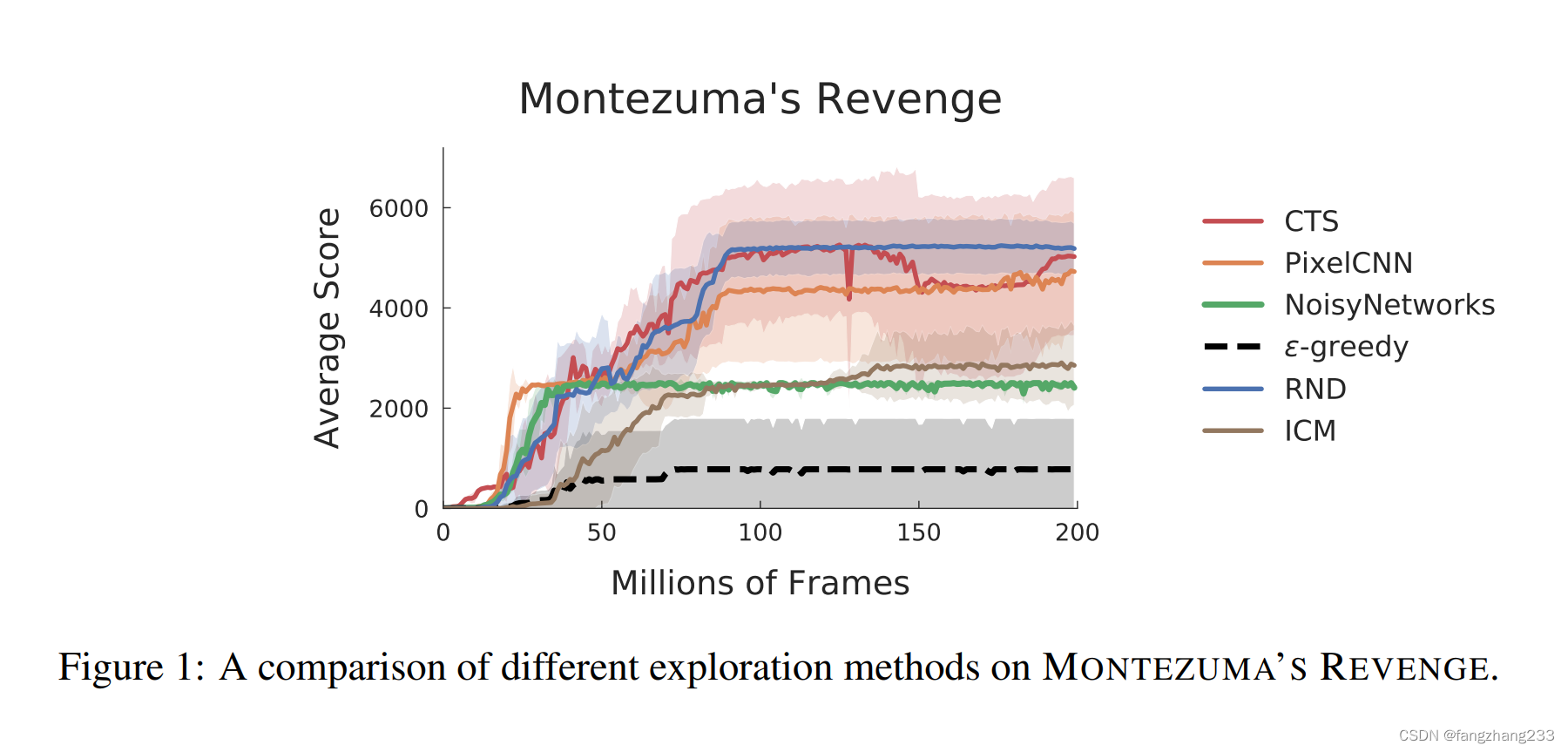
这么看起来,CTS上限更高啊
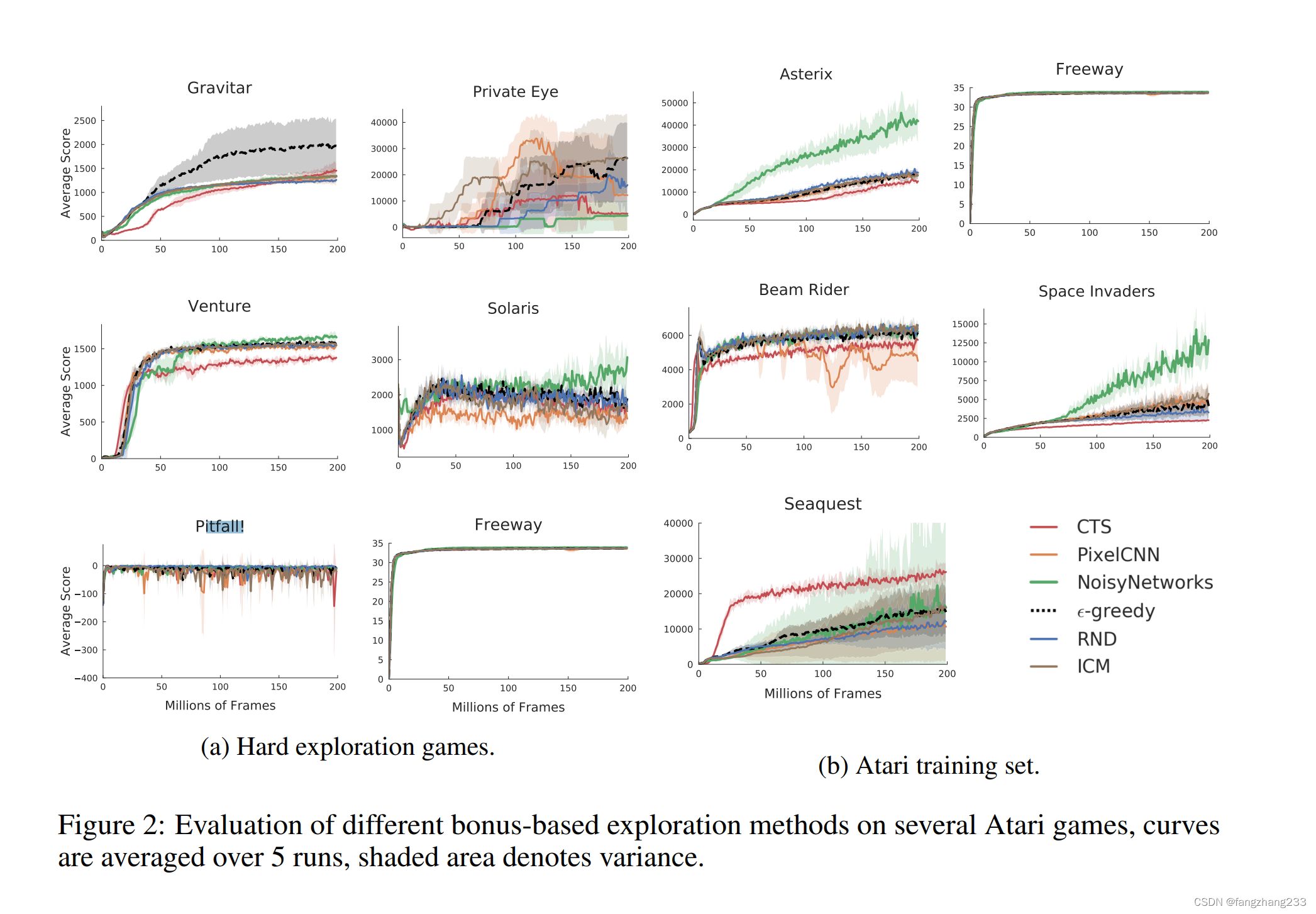
感觉pitfall好难啊,大家都差不多
具体的
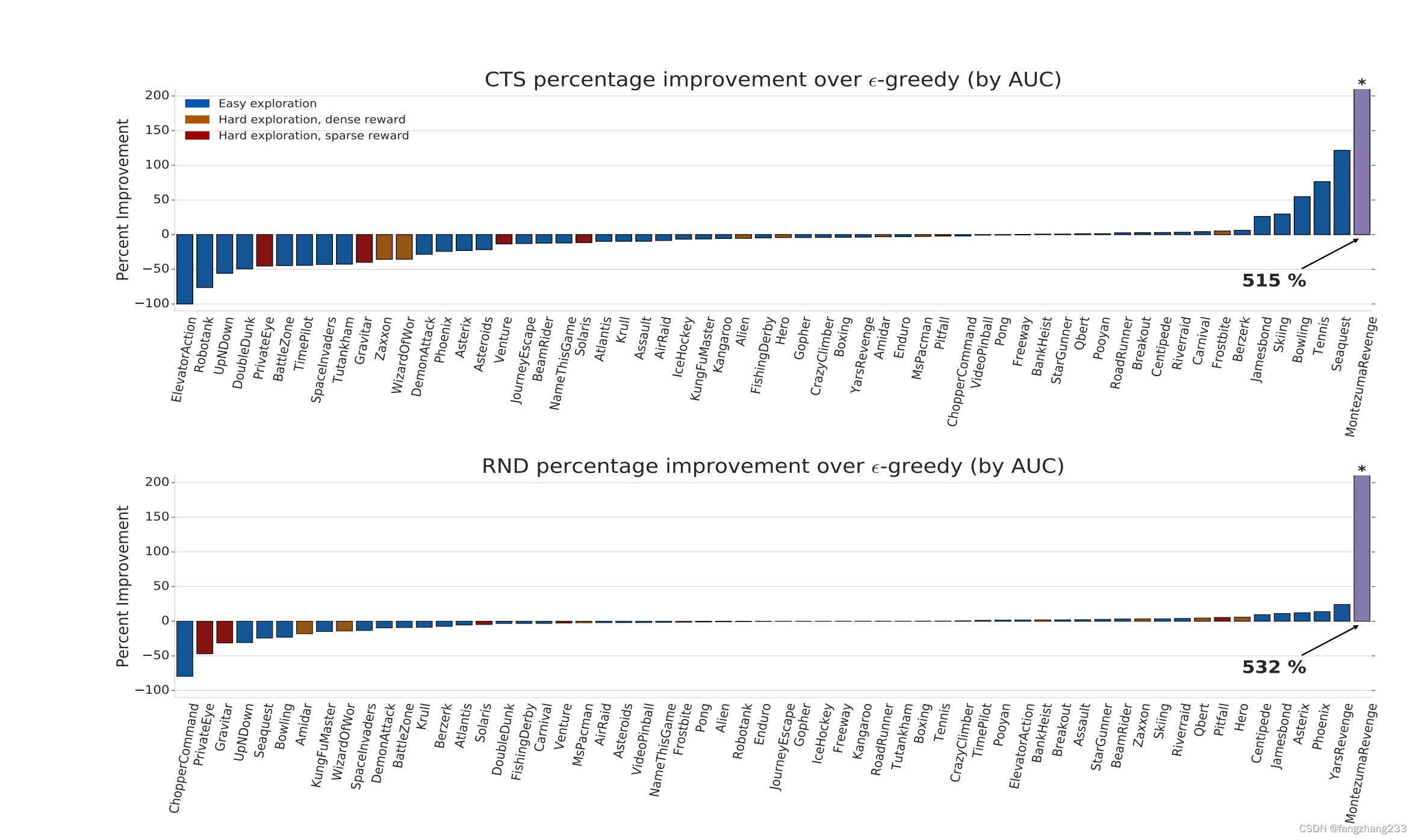
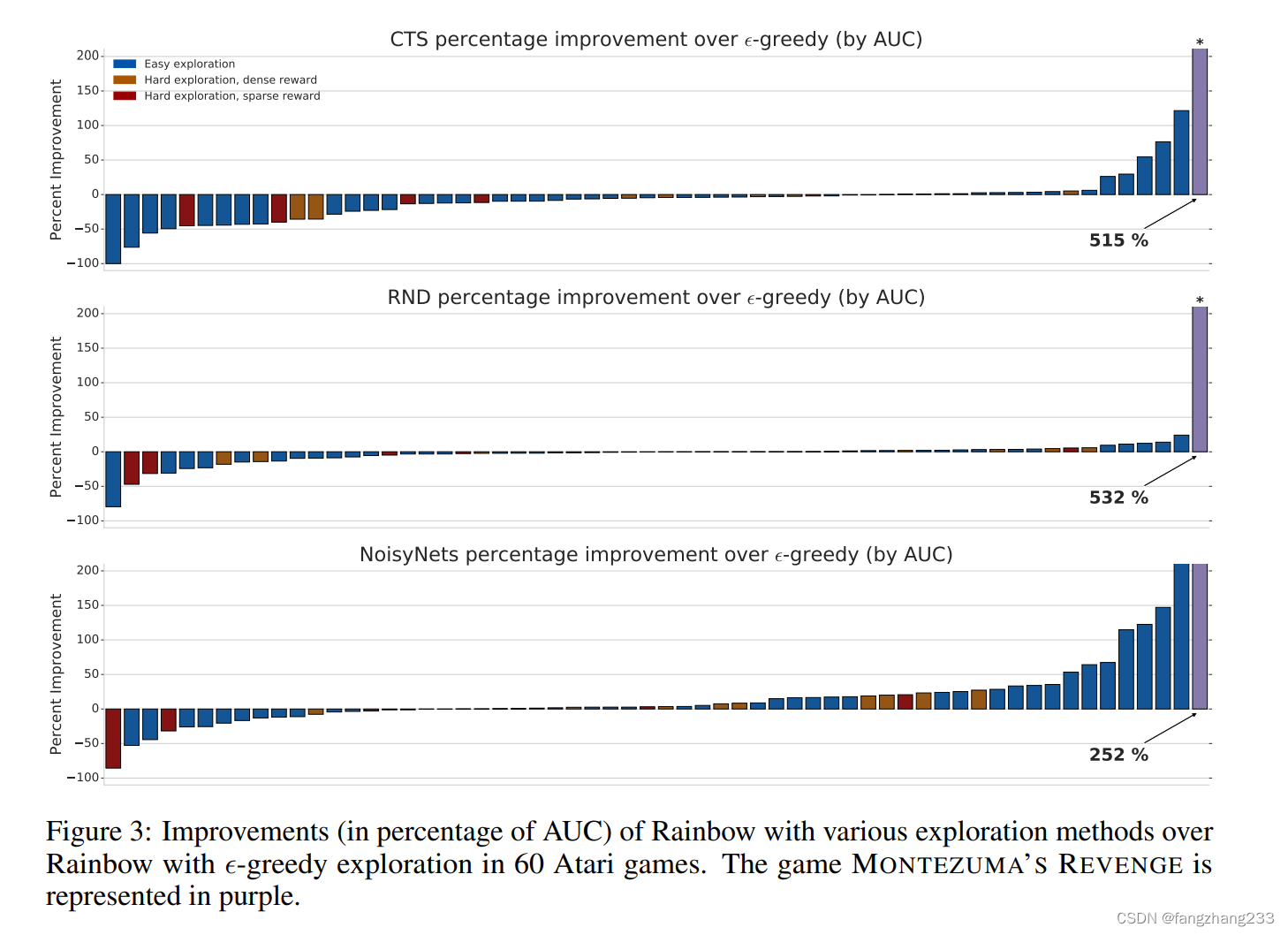
RND似乎只是在蒙特祖玛上提升特别多,别的不咋地
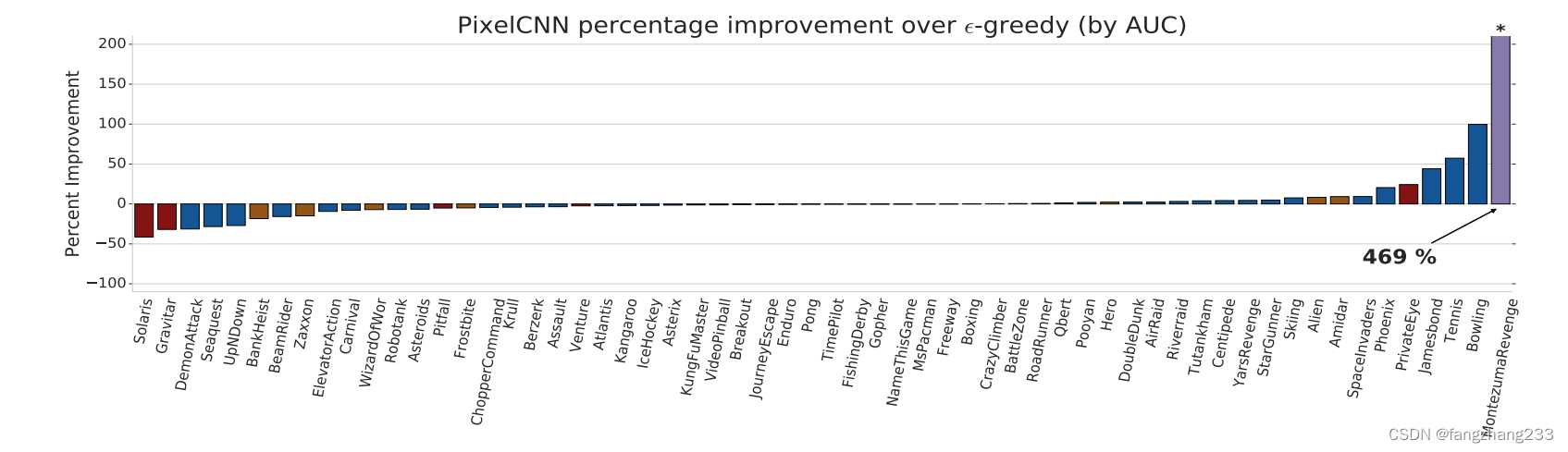

nosiy net对于非地图类的提升也不错。
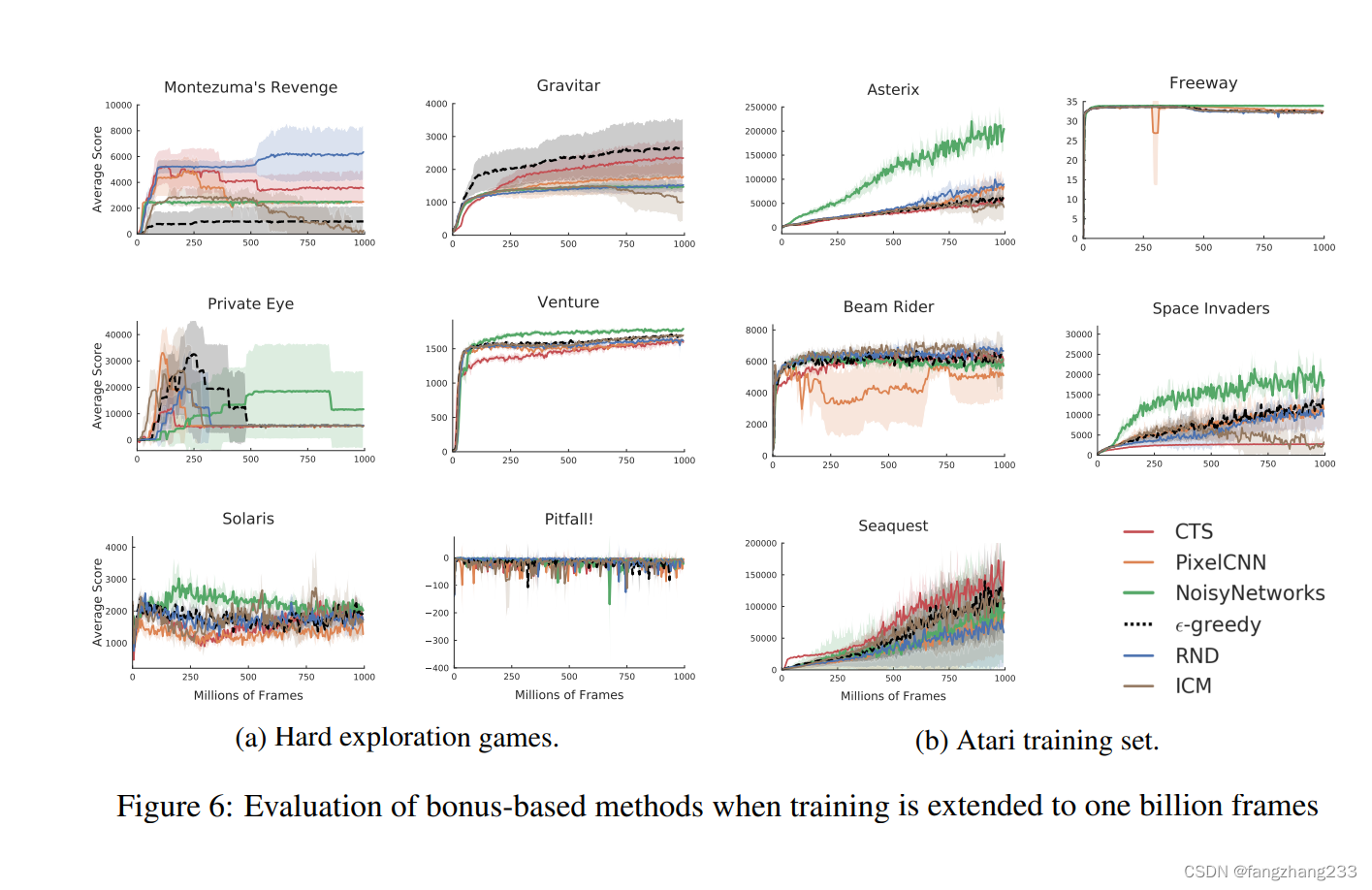
长期到one billion来看,RND还是可以的
最新的coin-fliping呢?看看论文里说的(ON BONUS-BASED EXPLORATION METHODS IN THE ARCADE LEARNING ENVIRONMENT)
4.5. Performance in MONTEZUMA’S REVENGE
Finally, we test our method on the challenging exploration benchmark: MONTEZUMA’S REVENGE. We follow the experimental design suggested by Machado et al. (2015) and compare CFN to baseline Rainbow, PixelCNN and RND. Figure 7 shows that we comfortably outperform Rainbow in this task. All exploration algorithms perform similarly, a result also corroborated by Taiga et al. (2020). Since all exploration methods perform similarly on the default task, we created a more challenging versions of MONTEZUMA’S REVENGE by varying the amount of transition noise (via the “sticky action” probability (Machado et al., 2018)). Figure 7 (right) shows that CFN outperforms RND at higher levels of stochasticity; this supports our hypothesis that count-based bonuses are better suited for stochastic environments than prediction-error based methods. Notably, we find that having a large replay buffer for CFN slightly improves performance, which increases memory requirements for this experiment.
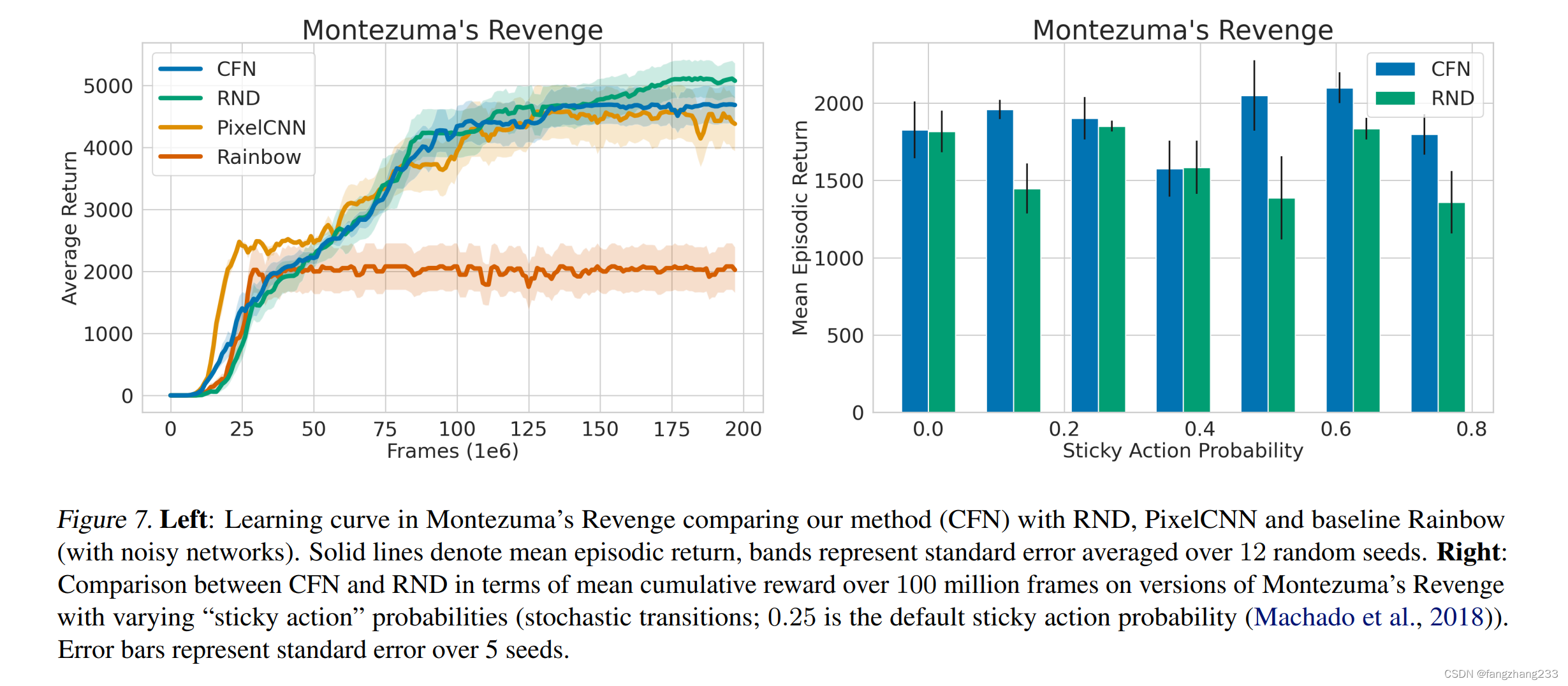 从左边来看,不如RND
从左边来看,不如RND
从右边来看,强于RND
原来是右边只到了100 million就停止了,左边持续到 200 million!好险恶的雷氏对比法!!















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









