






 本文通过数学统计方法,分析《红楼梦》中主要人物频率变化(问题一)、虚词使用频率(问题二)、词间相关性(问题三)以及句长分析和SVM算法(问题四),对比前八十回与后四十回的作者笔迹,发现主要人物频率、虚词使用和词间关系的异同,最终得出结论:前八十回与后四十回作者并非同一人。
本文通过数学统计方法,分析《红楼梦》中主要人物频率变化(问题一)、虚词使用频率(问题二)、词间相关性(问题三)以及句长分析和SVM算法(问题四),对比前八十回与后四十回的作者笔迹,发现主要人物频率、虚词使用和词间关系的异同,最终得出结论:前八十回与后四十回作者并非同一人。
摘要
《红楼梦》不同章回之间作者的异同,历来被学术界争论不休。当新的计算工具出现之后,我们就可以用数学的知识统计分析《红楼梦》不同章回作者异同的问题。
针对问题一,问题一要求根据主要人物在不同章回出现的频率不同,确定作者异同。首先选取《红楼梦》中十二个主要人物的名称,然后把整本书分为前四十章回、中四十章回、后四十章回,基于MATLAB进行的频数统计,计算频率,列出表格,并且使用SPSS画出不同章回的折线图。之后进行比对,我们得出前八十回主要人物占总文本的频率为2.8011%,后40回主要人物占总文本的频率为2.83095%,二者大致相同,由此可以判断前八十章和后四十章为一个人所写。
针对问题二,问题二要求我们通过虚词在不同章回出现的频率的异同,判断作者异同。首先我们确定了18个要研究的虚词,分别为“而、何、乎、乃、其、且、若、所、为、焉、也、以、因、于、与、则、者、之”,之后同样把整本书分为前四十回、中四十回、后四十回。利用MATLAB编程进行频数统计,计算频率,并且利用SPSS画出折线图和饼图,可以更直观的观察并得出结果。前80回虚词使用频率约为2.49%,而后40回虚词使用的频率约为1.975%,二者差别明显,故综合知通过虚词的出现频率我们得出的结论为前80回和后40回的作者不是同一人所写。
针对问题三,要求我们通过词与词之间的相关性分析,判断作者异同。我们利用SPSS进行了两变量相关性分析和距离分析,得出了相关性表格和近似值矩阵矩阵,建立了判断作者异同的模型。得出前四十章和中四十章的相关性大于前四十章与后四十章的相关性、中四十章与后四十章的相关性;前四十章和中四十章的欧式距离也小于前四十章与后四十章的欧式距离、中四十章与后四十章的欧式距离,我们得出结论,前八十章和后四十章不为一个人所写。
针对问题四,要求我们用其他方法分析作者的异同。我们首先运用句长分析的方法,对前四十章回、中四十章回、后四十章回的“。”频数进行统计,但是太过单一,所以我们又想了SVM方法增加器可行性。SVM又称为支持向量机,在空间中得到一个超平面,通过计算各数据点到超平面的距离进行数据分类进而可以找出作者的异同,结果是不为一个作者所写。
关键词:频率 两变量相关性分析 距离分析文言虚词 文本分类 SVM算法
一、问题重述
1.1 引言
《红楼梦》是具有高度思想性和艺术性的伟大作品,代表中国古典小说的最高成就,为中国古代“四大名著”之首。因某些历史原因,《红楼梦》在传播和保留过程中出现了令人遗憾的缺失。关于《红楼梦》作者的问题,历史上有较大争议。前80回是曹雪芹著作,后40回是高鹗续写是目前比较公认的版本,请你通过建模分析,解决问题这一问题。
1.2 问题的提出
(1)根据前八十章回和后四十主要人物出现频数的不同,判断是否为一个作者所写。
(2)利用120章回中你感兴趣词语的词频(比如虚词或者常用高频词的词频)的不同,能否证明不同章回之间作者的异同;
(3)利用词与词之间的相关性进行分析,能否证明不同章回之间作者的异同;
(4)你是否有其他方法(比如语义分析等)来分析不同章回之间作者的异同?
二、问题分析
2.1 问题一
要求我们依据红楼梦中主要人物出现的频率来判断作者在前80回和后40回是否异同,首先我们把红楼梦120回平均分为三部份,基于matlab编程,解出第一个问题。我们首先用matlab计算出每个主要人物的名字在前四十回、中四十回和后四十回中出现的频数。然后根据数学原理,计算出每个主要人物出现的频率,加以对比,判断前八十回和后四十回作者的异同。
2.2 问题二
要求我们通过感兴趣的词频(我们选用虚词来判断),判断作者在前80回和后40回是否异同,首先我们把红楼梦120回平均分为三部份,基于matlab编程,解出第二个问题。我们首先用matlab计算出每个虚词在前四十回、中四十回和后四十回中出现的频数,并且对三部分虚词总体和各个虚词进行统计,然后根据数学原理,计算出每个虚词出现的频率,加以对比,判断前八十回和后四十回作者的异同。
2.3 问题三
此问要求我们通过相关性分析,对不同章回作者的异同作出判断,基于SPSS的相关分析中的两变量相关分析和距离分析,求出结果。首先对各个虚词出现的person相关、斯皮尔曼等级相关和肯德尔相关作出分析,然后进行距离分析,使用欧式距离,得出近似值矩阵,然后得出结论。判断各章回作者的异同。
2.4 问题四
此问要求我们用其它的方法确定作者的异同,我们就想到了句长分析的方法。但是句长分析的方法过于单一,所以我们选择用SVM方法补充。通过超平面的寻找和数据到超平面的距离判断作者的异同。
三、问题假设
1.假设三个部分主要人物频率的异同可以反映作者的行文风格;主要人物出现的频率很低可以忽略,对结果无影响;
2.假设三个部分虚词频率的异同可以反映作者的行文风格;虚词出现的频率很低可以忽略,对结果无影响;
3.假设虚词数据可靠;
4.表格中用“1”或“前”代表1-40章回,用“2”或“中”代表40-80章回,用“3”或“后”代表80-120章回。
四、符号说明

五、模型的建立与求解
5.1 问题一模型的建立与求解
要求我们依据红楼梦中主要人物出现的频率来判断作者在前80回和后40回是否异同,在用matlab求频数之前,通过查阅相关资料我们要选取主要人物来分析问题。然后根据主要人物出现的频率来判断作者是不是同一人。
5.1.1 主要人物的选取
《红楼梦人物谱》该书分别依据庚辰本《脂砚斋重评石头记》和程乙本《红楼梦》,精确统计出作品中除历史人物外的全部人物,标出每个人物在作品中首次出现的回数,并根据人物间的血缘,隶属或其他关系,编制两套人物表[1]。表中还以注释的形式,对人物之间复杂微妙的关系和其他众多疑难问题进行了精辟详尽的分析说明。在书中我们依次选取宝玉、黛玉、宝钗、贾环、袭人、麝月、莺儿、李嬷嬷、凤姐、晴雯、贾母、赵姨娘来进行数据分析。
5.1.2 主要人物选取后的相关计算
我们首先对文档进行处理,分为三个部分,前四十回为“1”、中四十回为“2”,后四十回为“3”,各个部分对应的文档字数记作为:
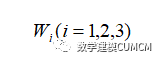
然后使用MATLAB进行编程处理。我们选取了12个主要人物进行分析,记作在前四十回、中四十回和后四十回中各个部分所选取12个主要人物的频数记作为:
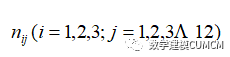
然后计算各部分所选取主要人物的频数之和记作为:
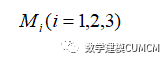
然后计算各个部分,各个人物所占本部分的频率记作为:
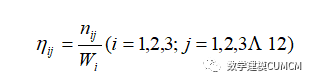
最后计算出各个部分主要人物的出现占总文本频率记作为:
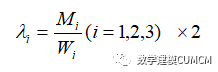
5.1.3 模型的计算结果分析
通过MATLAB计算出结果,我们用SPSS得到三个部分中主要人物使用情况和出现频率的模型结果:
三个部分文本的总字数分别为:273879、328310、279058;
三个部分主要人物出现频数总和为:4265、4012、3930;
各个部分主要人物的出现总字数为:8597、8087、7900;
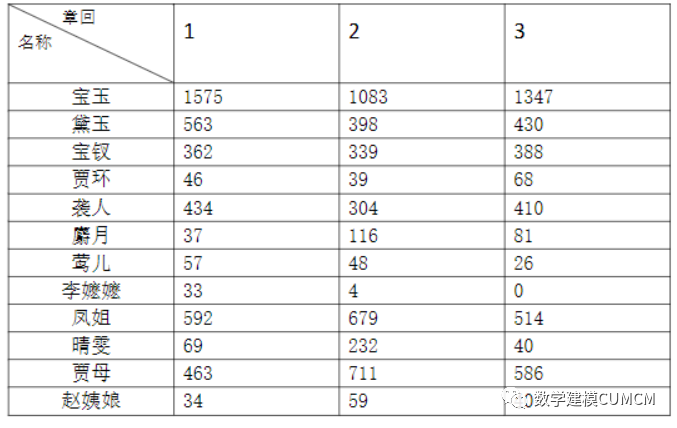
计算主要人物出现的频率为:
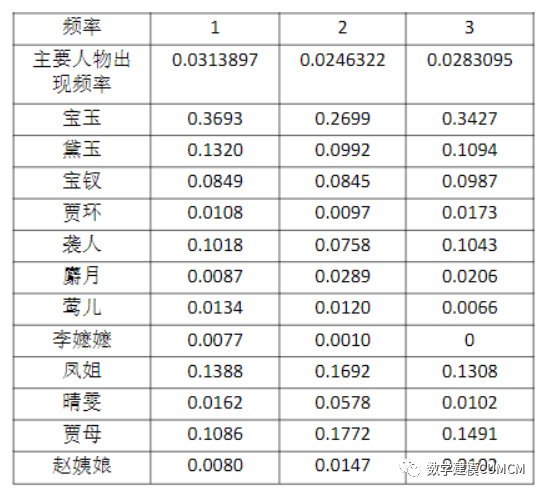
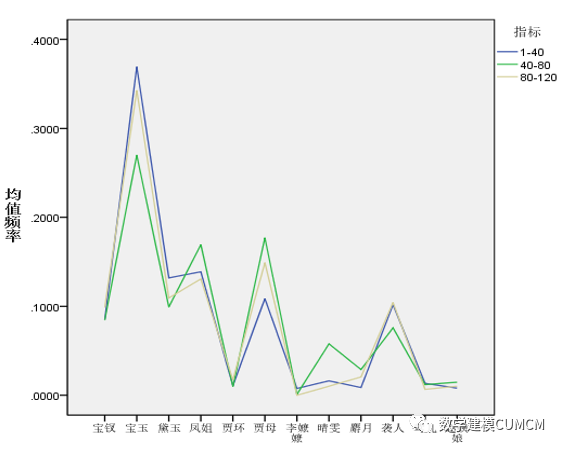
从上述表中我们可以看出宝玉出现的频率最大,通过对比三部分各主要人物的频率知比较大致相似,前80回出现主要人物占总文本的频率为2.8011%,后40回主要人物占总文本的频率为2.83095%,二者大致相同,又有折线图知各个人物频率大致也相似,通过对主要人物出现的频率来解释,我们得出结论为前80回合后40回是同一个作者所写。
5.2 问题二的模型建立与求解
要求我们通过感兴趣的词频(我们选用虚词来判断),判断作者在前80回和后40回是否异同,也是和问题一相似,通过选出虚词,来判断各个虚词在每个部分的频率,各个虚词占总样本的频率。通过对比来分析作者的异同。
5.2.1 虚词的选取
能够区别文学作品的特征主要有 用词、句式、修辞手法、中心意象、主题等等。但是能用于统计的特征有语音、字、词、句子、段落,语篇结构等等可以量化考察的信息。因此它反映的不是作者想表现的内容,而是作者行文中不经意间体现出的用词造句习惯。我们知道古代虚词有18个,《红楼梦》内容是文言文的形式,在这里选用虚词这一文言文中的特殊词汇判定作者行文风格,虚词是一类特殊的词汇,它不在文章中有实义,从而虚词在文言文中的使用情况仅由作者用词习惯决定,从而可以通过对虚词的使用情况分析代表作者的一类行文风格
故我们可以选取这18个虚词来分析,它们依次是而、何、乎、乃、其、且、若、所、为、焉、也、以、因、于、与、则、者、之。然后统计每部分的字数,再分别统计出各虚词在每部分中的使用频数,对三部分中的虚词使用比率进行比较,分析出作者使用虚词的总体情况。在分别就每一个虚词的使用分析确定作者的风格。
5.2.2 相关计算
使用MATLAB进行编程处理。我们选取了18个虚词进行分析,记作在前四十回、中四十回和后四十回中各个部分所选取18个虚词的频数记作为:
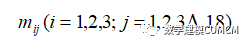
然后计算各部分所选取虚词的频数之和记作为:
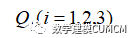
然后计算各个部分,各虚词所占本部分的频率记作为:
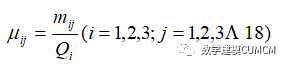
最后计算出各个部分主要人物的出现占总文本频率记作为:
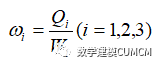
5.2.3 模型的计算结果分析
通过MATLAB计算出在三部分虚词出现的频数,以下是相应的结果给出三个样本中虚词出现频数的表格,模型结果如下知三部分各个虚词总数依次为6830、8161、5512。
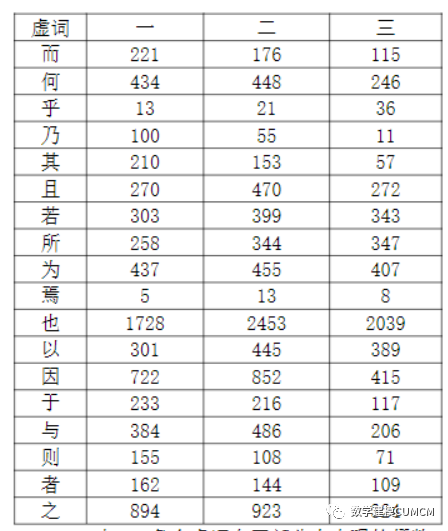
计算虚词的使用频率为 :
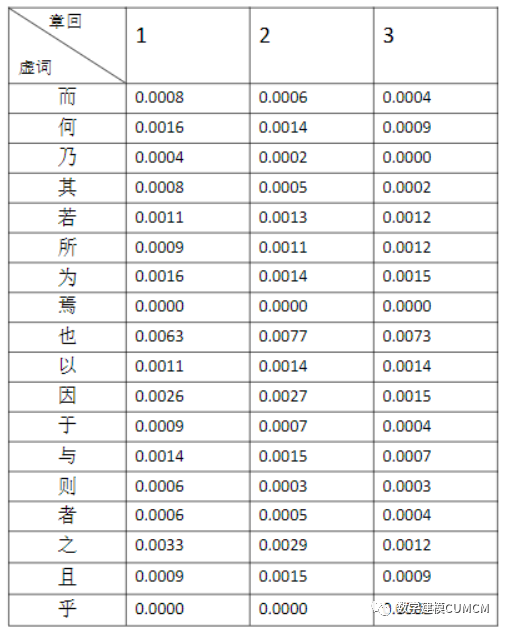
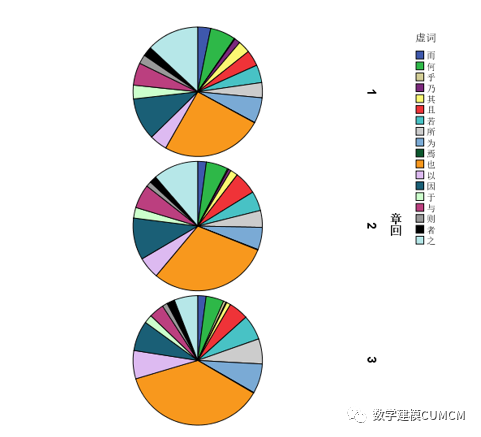
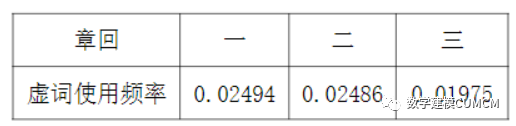
从以上表中我们可以看出虚词的使用频率,“也”使用占比例最大第一部分各虚词分布集中,第二部分除去也外也比较集中,对比一二第三部分较为分散,由饼状图也可以看出1、2比较相似,而3和1、2有明显的区别。从这里看出前80回和后40回作者不是同一个人,另一方面从虚词的使用频率来看,前80回虚词使用频率约为2.49%,而后40回虚词使用的频率约为1.975%,二者差别明显,故综合知通过虚词的出现频率我们得出的结论为前80回和后40回的作者不是同一人所写。
5.3 问题三的模型建立与求解
题目要求我们根据词与词之间的相关性分析,确定不同章回的作者异同。首先我们把全书分为前、中、后三部分,每个部分40章回,然后运用SPSS进行虚词之间的相关性分析。
5.3.1 两变量相关性分析
首先使用相关性分析,对虚词之间的关系进行相关性分析。我们使用了Person相关系数,用以衡量章回和虚词出现频数的线性关系。
(1)Person相关系数:
此系数用于衡量间隔尺度变量间的线性关系。公式如下:
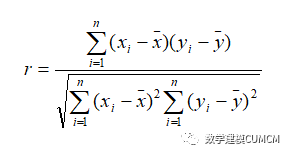
(2)斯皮尔曼等级相关系数:
由于person相关系数适用于两变量的度量水平都是间隔尺寸数据,两变量的总体是正态分布或近似分布,所以改用适用于变量总体的分布不详的斯皮尔曼等级相关系数:
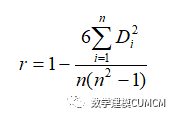
(3)肯德尔相关系数:
为了得出正确的数据我们采取了多个相关系数进行分析,肯德尔相关系数基于数据的秩,利用变量的秩计算相关性:
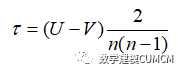
计算过相关系数后,就要开始相关系数的显著性检验。样本相关系数是从总体样本中抽取随即样本观测值计算出来的,是近似值,为了确定样本相关系数不是偶然结果,我们还需要做显著性检验。
(4)person相关系数假设检验:
在假设总体相关系数为0的情况下,与样本有关的统计量服从自由度为(n-2)的T 分布:
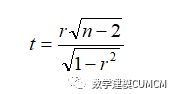
(5)斯皮尔曼等级相关系数假设检验:
在原假设相关系数为0的小样本的条件下,采用斯皮尔曼相关系数,进行大样本分析时,要使用正态检验统计量Z:
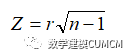
(6)肯德尔相关系数假设检验:
在原假设相关系数为0的小样本的条件下,肯德尔服从肯德尔分布,大样本数据分析时,采用统计检验量:

5.3.2 距离分析
距离分析是对变量之间广义距离的一种度量,有助于分析复杂的数据集。我们把红楼梦分为前中后三部分,通过SPSS软件进行相似性度量和不相似性度量,可以得到变量之间广义距离的矩阵,并且可以通过欧式距离确定变量的近似值矩阵。
Euclidean(欧式距离):
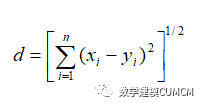
5.3.3 模型的计算结果分析
根据SPSS的运行结果,我们得到如下表格,可以分析得知词与词之间的相关性。我们把全文分为前、中、后三个部分,每部分四十回,由此判断作者的异同。
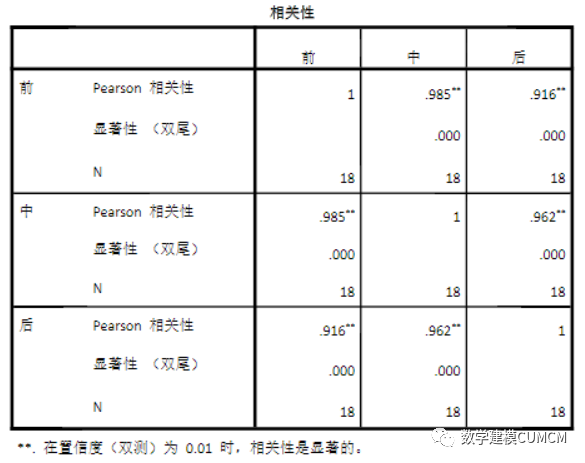
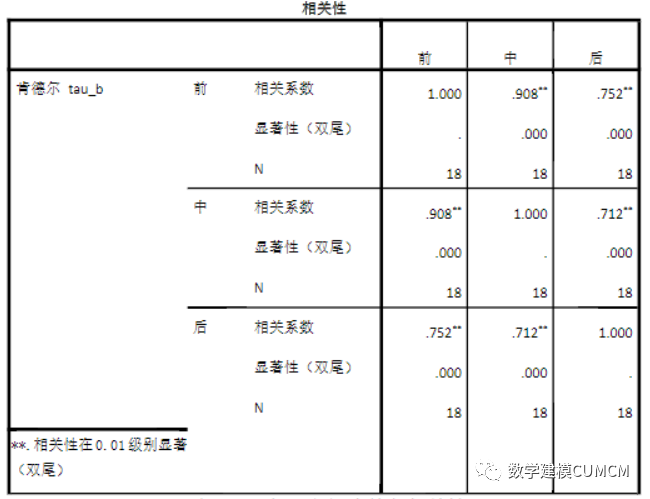
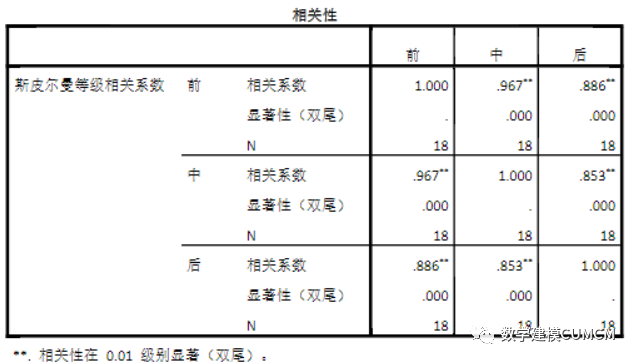
由表格可以得出,在由三种相关系数计算得到的的计算结果中,前四十回与中四十回的相关性明显高于前四十回、中四十回与后四十回的相关性。
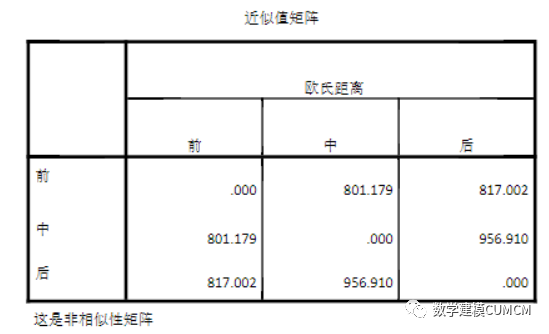
由表9可以看出,采用了欧式距离,是一个非相似性矩阵,变量之间的差别是:“前四十回”和“后四十回”、“中四十回”和“后四十回”的欧式距离大于“前四十回”和“中四十回”的欧式距离。可以得出“前四十回”和“后四十回”、“中四十回”和“后四十回”的差别大于“前四十回”和“中四十回”的差别。由以上分析可知可以得出结论,红楼梦前八十回和后四十回不是一个人写的。
5.4 问题四模型的建立与求解
5.4.1 句长分析
句长分析是通过MATLAB统计“。”的个数,确定前中后三部分的句子个数,再根据总字数确定每个部分的平均句子长度,分析对比这三部分的平均句子长度,发现三部分的句子长度很相近,并且用句子分析过于单调,所以我们加入了其它分析方法。
5.4.2 SVM介绍
(1)SVM主要思想
针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
(2)SVM主要特征
⑴ SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
⑵ SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
⑶ 通过对数据中每个分类属性引入一个哑变量,SVM可以应用于分类数据。
⑷ SVM一般只能用在二类问题,对于多类问题效果不好。
5.4.3 SVM算法
SVM又称为支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。其思想是找到数据空间中的一个超平面,使得数据空间中的所有数据到这个超平面的距离最短。通过计算各数据点到超平面的距离进行数据分类进而可以找出作者的异同。
(1)点到超平面的距离公式:
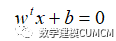
通过各个特征变量组成的数据点,我们可以求出数据点到超平面的距离。特征变量我们选取句子个数、句长和虚词个数,公式如下:
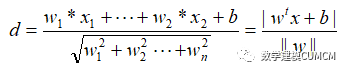
5.4.4 结果
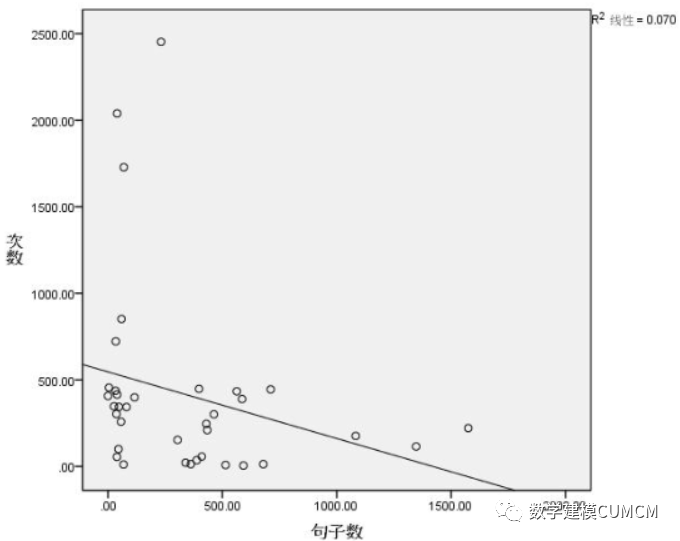
得出结论,由于前八十章回的数据点和后四十章回的数据点距超平面的距离相差很大,所以前八十章和后四十章不是一个作者写的。
附录
问题一 代码:
fid=fopen('filename.txt','r');
if fid==-1
disp('can not open the file');
return;
end
dict=char('宝玉','黛玉','宝钗','贾环','袭人','麝月','莺儿','李嬷嬷','凤姐','晴雯','贾母','赵姨娘');
freq=zeros(size(dict,1),1);
while(~feof(fid))
aLine=fgetl(fid);
disp(aLine)
for i=1:size(dict,1)
re=strfind(aLine,deblank(dict(i,:)));
freq(i)=freq(i)+length(re);
end
end
for i=1:size(dict,1)
disp([dict(i,:),'出现次数:',num2str(freq(i))])
end
fclose(fid);
问题二 代码:
fid=fopen('filename.txt','r');
if fid==-1
disp('can not open the file');
return;
end
dict=char('而','何','乎','乃','其','若','所','为','焉','也','以','因','于','与','则','者','之');
freq=zeros(size(dict,1),1);
while(~feof(fid))
aLine=fgetl(fid);
disp(aLine)
for i=1:size(dict,1)
re=strfind(aLine,deblank(dict(i,:)));
freq(i)=freq(i)+length(re);
end
end
for i=1:size(dict,1)
disp([dict(i,:),'出现次数:',num2str(freq(i))])
end
fclose(fid);

















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











