






论文题目:An adaptive federated learning scheme with differential privacy preserving
中科院二区 2022年发表在 Future Generation Computer Systems
一些概念
information entropy(信息熵):信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛,没什么信息量)。
简介
联邦学习的通信总成本与通信轮数、各参与方的通信消耗、合理学习率的设定以及计算公平性的保证有关。联邦学习框架中的隔离数据策略并不能完全保证用户的隐私安全。针对上述问题,文章提出了一种结合自适应梯度下降策略和差分隐私机制的联邦学习方案,适用于多方协同建模场景。为了适应超大规模分布式安全计算场景,文章引入差分隐私机制来抵御各种背景知识攻击。实验结果表明,在固定通信开销下,所提出的自适应联邦学习模型性能优于传统模型。这种新颖的建模方案对不同的超参数设置也具有较强的鲁棒性,为联邦学习过程提供了更强的可量化的隐私保护。
本文模型
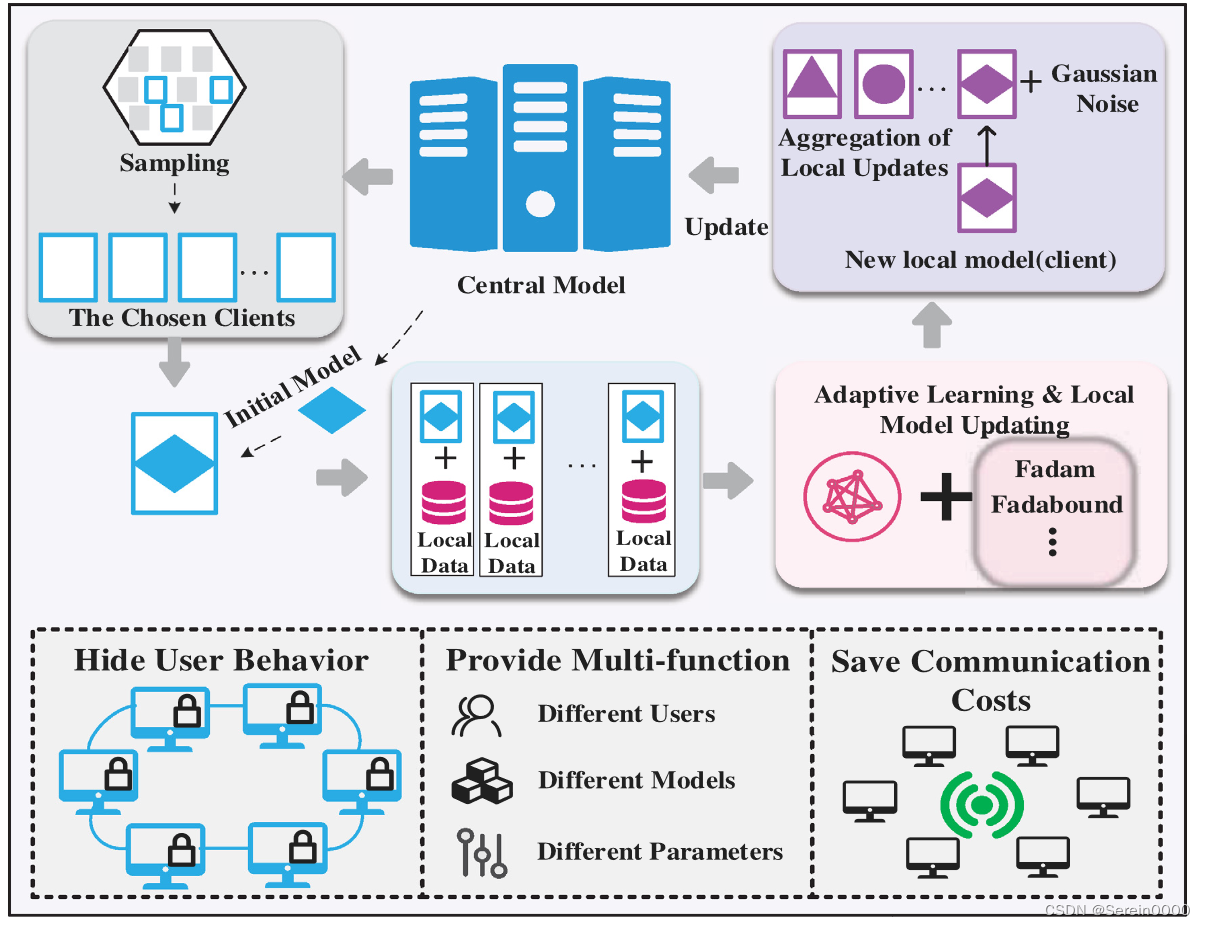
步骤1:客户选择。中心服务器M从一组客户端中选择符合要求的K个节点客户端。在此过程中,中心服务器根据客户端运行状态和网络状态选择样本用户。
步骤2:广播。服务器将中心模型M分发给样本客户端。
步骤3:客户端计算。每个客户端k使用本地数据更新本地计算模型。例如,运行梯度下降算法优化机器学习模型,加密并将本地更新
传递到中心。在样本对齐和模型训练过程中,每个客户端的数据都存储在本地。
步骤4:聚合。服务器收集所有更新信息。为了提高效率,一旦有足够的设备报告结果,滞后的设备将被丢弃。该步骤包括多个过程,包括安全聚合、有损压缩、噪声添加和更新剪裁。
步骤5:模型更新。将参与当前轮i的所有客户端的累计更新量Ui进行聚合,服务器基于此更新中心共享模型,并在下一轮中将新模型发布到选定的客户端。
联邦学习中的自适应调整
梯度下降算法
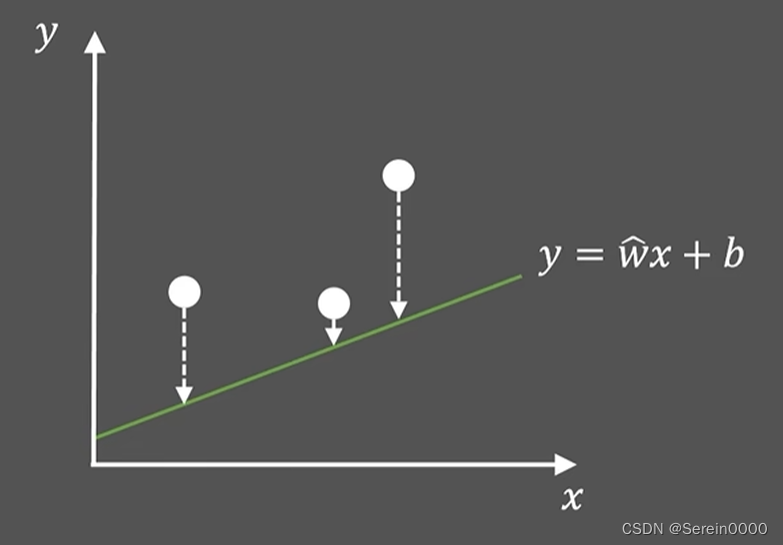
假设w已知,求b使得点到直线的距离最小(即损失函数最小,损失函数L是关于b的二元一次方程)
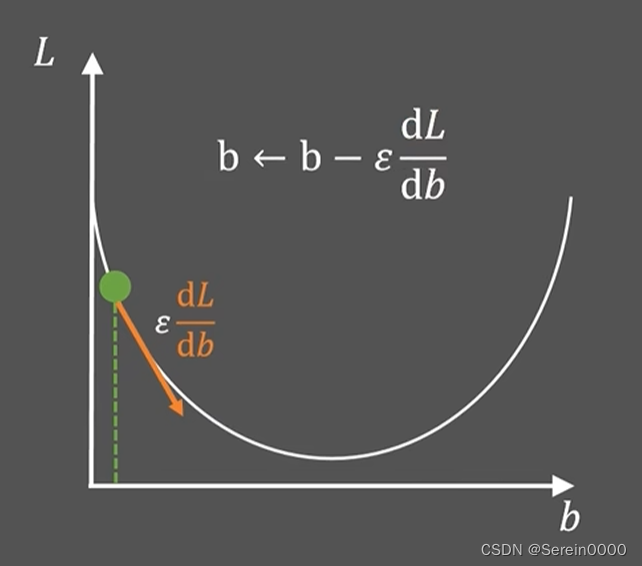
函数的最低点是最优值。随机假设一个值为b,使b走向最优值。可以求出当前点的斜率,再乘以一个常数
,箭头的方向是斜率的负方向,让b更新为
,一直迭代至使b最小。
一般化的函数如下:

问题:内存开销大,迭代速度慢。
随机梯度下降算法
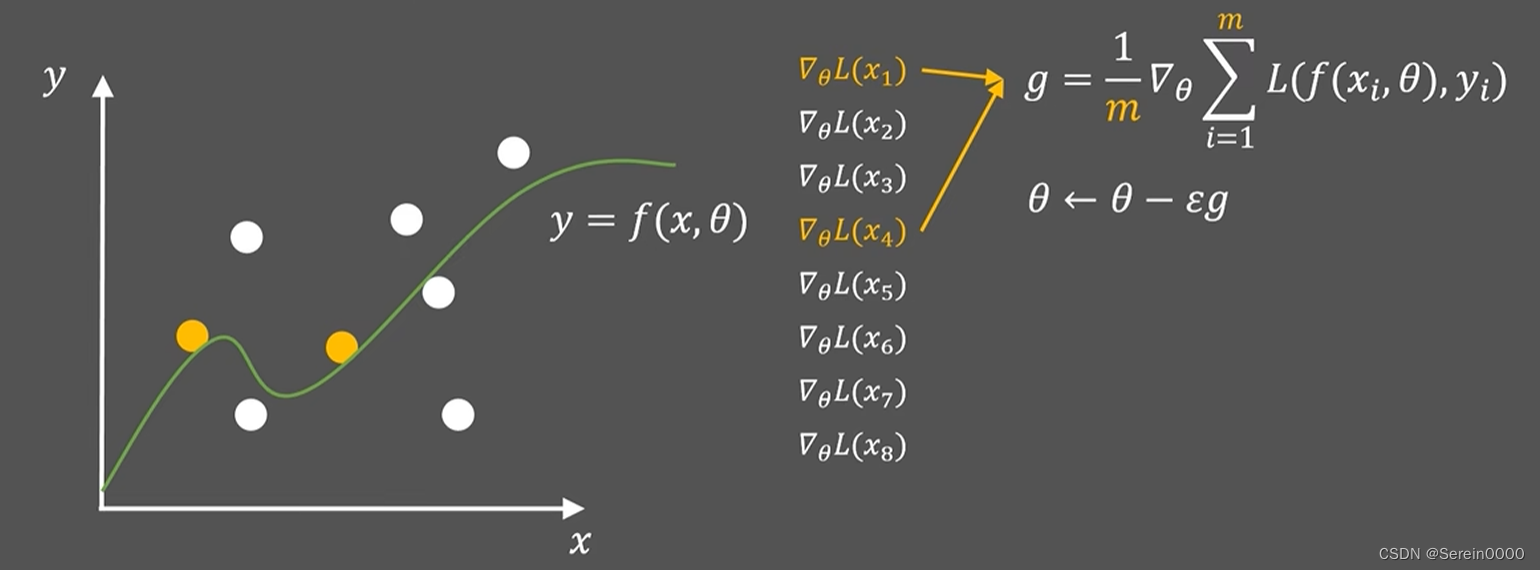
我们假设每次随机从N个样本里面选择m个样本,且每次都不重复,这样解决了内存开销大,迭代速度慢的问题。
adam算法
根据梯度自动调整学习率。
s是自适应的动量,用
来控制,g是梯度
r是梯度大小随时间的积累量,
,用
手动调节来控制优化过程
修正参数,使其在训练之初比较大,帮助算法快速收敛
修正参数,使其在训练之初比较大,帮助算法快速收敛
r在分母上,当梯度波动很大的时候,学习率会迅速下降;当梯度波动很小的时候,学习率会下降的慢一些,这样实现了学习率
的自动调整。
是一个小量,为了防止分母为零来稳定数值计算。
adabound算法
,
分别为学习率的下限和上限。为了实现学习率的平滑过渡,随着学习时间的变化,学习率的下限
从0逐渐增大到
,上限
从∞逐渐减小到
。
Adabound 算法结合了Adam和SGD的优点,表明该算法在训练前期收敛速度快,后期收敛速度慢,最终性能较好。换句话说,Adabound在训练初期看起来像Adam,在训练结束时更像SGD。
Fadabound算法是将Adabound算法应用到FL过程中。
Fadam算法是将adam与FL相结合的方法。
中心模型的更新过程主要包括几个关键步骤:
( 1 )中心服务器选择适合训练的用户设备k,发送原始参数模型Mi或打开下载权限。
( 2 )样本客户端利用本地数据更新参数并计算更新后的梯度。在此过程中,采用自适应梯度下降算法来保证良好的收敛性。
( 3 )对特定用户更新的梯度进行缩放,避免单个计算节点贡献过大。
( 4 )在单个通信过程的整体聚合更新中加入差分隐私噪声。
( 5 )将梯度更新结果发送到中心服务器更新中心模型并广播给参与的客户端。















 1995
1995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









