






来源:SCI 1区 2022年10月发表 IEEE Transactions on Computational Social Systems
简介
现代医疗系统运行在高度动态的环境中,需要自适应的访问控制机制。对于敏感数据和医疗设备的访问,应根据患者当前的健康情况授予或拒绝。为此我们提出了一种新的模型,该模型允许根据表征来源、访问请求类型、患者和与患者条件相对应的估计风险的情景进行动态访问控制决策。本文提出了一种新的基于风险的联邦学习的医疗授权中间件( FRAMH ),支持基于风险的访问控制,以应对不断变化和不可预见的医疗情况。
FRAMH访问控制模型
风险分类
FRAMH对患者健康状况的严重程度进行分类,该分类假设患者的病情可能是危重的、严重的或稳定的。在风险更大的形势下,安全重于隐私;在稳定的情况下,隐私优先于安全。
危重:患者生命存在重大危险。在这种情况下,安全重于隐私,医务人员访问数据或医疗设备的请求可以被授予。
严重:患者病情被认为是紧急的。在这种情况下,医生可以从其他部门获取患者数据。我们允许访问风险较高的数据,以加快患者的治疗。
稳定:用户只能访问授权数据。由于患者没有面临生命危险的情况,因此没有理由获得额外的信息。
情景模型
情景模型用于表示、存储和检索情景信息,这些信息用于建立访问控制策略,从而进行访问控制决策。
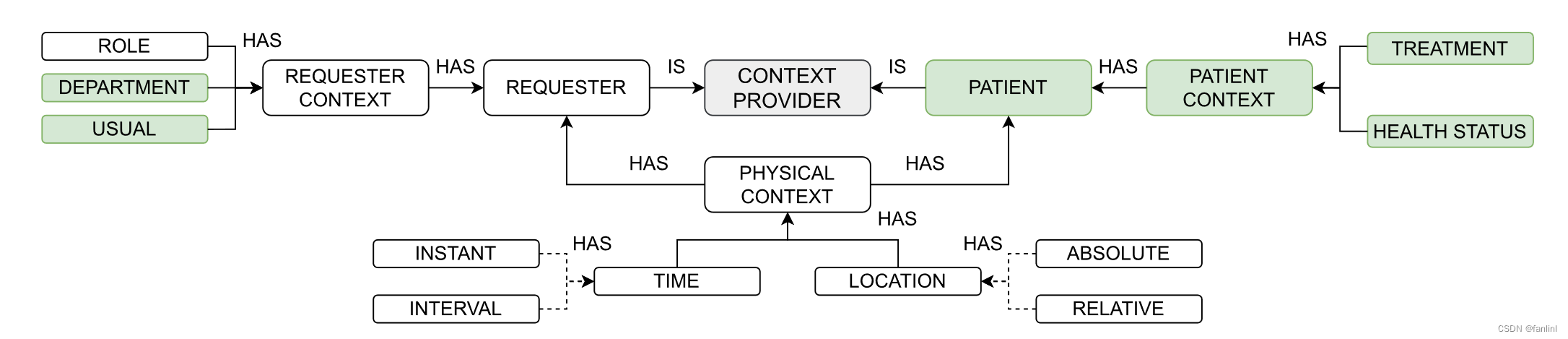
情境提供者具有由一组属性表征的情境元素:请求者和患者。
请求者和患者都有一个物理情景,包括时间和位置情景信息。前者可以是一个瞬间,也可以是一个间隔,而后者可以是一个绝对的或相对的地理位置(即医院内的经纬度或房间号)。
时间信息可以在特定的时间段内规范访问,而位置信息可以根据请求者所占用的当前位置来授予或拒绝访问。
请求者包括角色、部门和通常。角色表示医疗保健专业类别或连接患者与请求者的关系,比如一个熟人或朋友。部门属性包含了与请求者专业化相关的部门信息。通常的属性概述了患者是否已经被该请求者访问过。
患者特有的情境信息包括正在接受的治疗和健康状况(危重的、严重的或稳定的)。
白色方框内的领域无关信息是指其他应用领域可重用的公共信息。彩色方框我们采用源自Health Level Seven ( HL7 )参考信息模型的主要概念。(类似于XML,JSON格式一样,HL7也是一种数据格式,可以理解为一个包含很多行字符串的消息体,这一整个就是一个HL7消息内容)
访问控制模型形式化
1 )请求者:我们用表示请求者
的集合。
2 )请求者属性:用表示请求者属性
可以假设的可能值集合。
3 )患者属性:用表示患者属性
可以假设的可能值集合。
4 )资源:用表示一个请求者
可以访问的资源集合
。
5 )动作:用表示请求者
可以在与病人
相关的资源
上执行的动作集合。
6 )情景参数:用表示情景参数
可能取值的集合。一个情景参数由一个名字
和值
来描述,因此
是tuple。
FRAMH架构
FRAMH架构由三层组成:授权层、患者层和学习层。
授权层:提供了用于验证访问请求和执行访问控制决策的组件。
患者层:为患者情景数据的收集提供服务。
学习层:基于与区块链集成的FL的学习层,负责支持与当前患者病情相关的风险水平的预测。
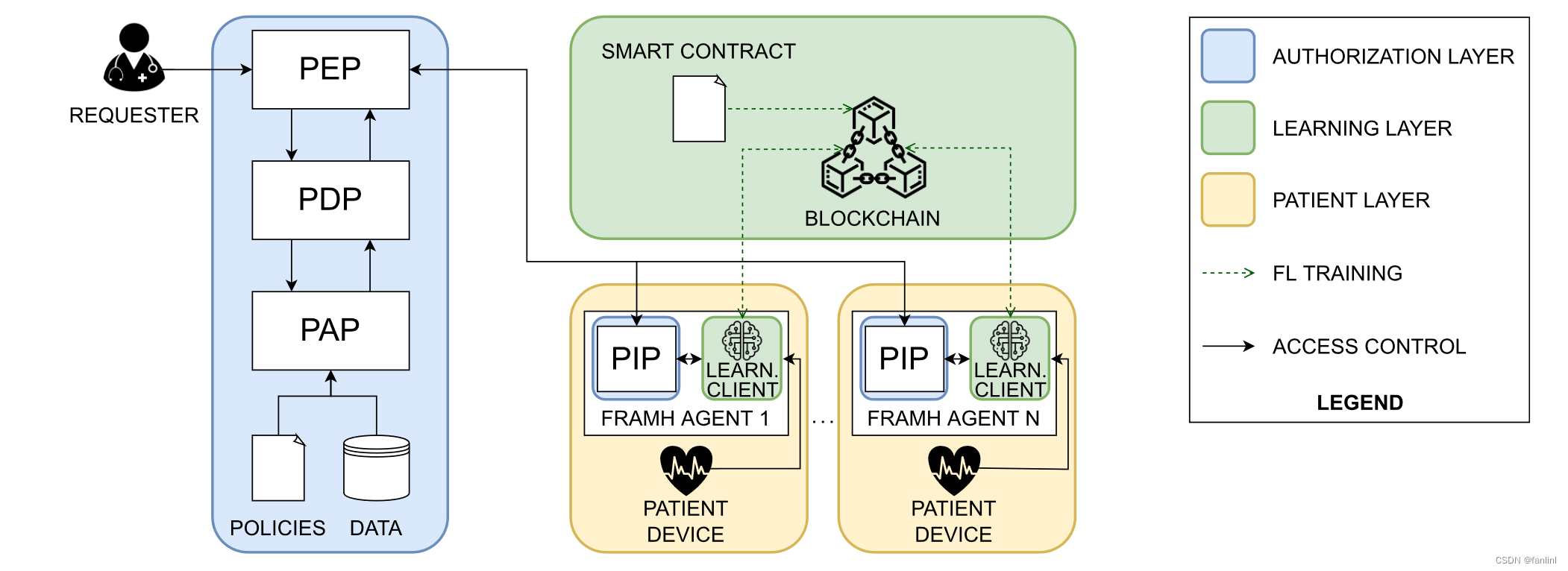
授权层
策略执行点(Policy Enforcement Point,PEP):策略执行点( PEP )处理所有传入的访问请求。它从请求中提取信息,并建立一个可以被策略决策点( PDP )理解的查询。进一步地,如果传入请求没有提供所需的全部数据,PEP从包含在查询中的外部来源收集额外信息进行评估。
策略决策点(Policy Decision Point,PDP):PDP是负责评估传入的请求,并确定它们是否应该被授予或拒绝的实体。它必须满足制定访问控制决策所需的政策和数据。
策略信息点(Policy Information Point,PIP):策略信息点( PIP )是部署在每个节点上的组件,提供PDP做出访问控制决策所需的额外信息。特别地,它提供了患者信息,包括与全局模型预测的当前健康状况相关的信息。
政策管理点(Policy Administration Point,PAP ):政策管理点( PAP )是允许管理员管理政策和上传政策评估过程中使用的数据服务。
患者层
患者设备:一种可穿戴的IoMT设备,可持续监测患者的健康状况。它周期性地将患者数据发送给其关联的FRAMH代理。
FRAMH代理:每个患者的设备都有一个与之相关的FRAMH代理。用于计算患者健康状况的风险水平和向其他FRAMH架构模块提供与当前健康状况相关的患者数据的所有服务。每个FRAMH试剂从病人设备接收重要的生理数据。这些信息作为全局模型的输入定期提供,嵌入到学习客户端中,输出患者的健康状况。如果访问请求满足相应的访问控制策略,则FRAMH代理授予对这些数据的访问权限。当被PDP认为时,发送做出访问控制决策所需的患者情景信息。
学习层
区块链:我们使用区块链,因为它保证了透明度、公平性和公正性,即使在与FL过程合作的不受信任方之间也是如此。此外,通过依靠智能合约技术,我们消除了传统FL方法中通常需要一个负责聚合所有部分模型的中心化实体的需求。智能合约的采用允许客户端在区块链上发布部分模型。正是智能合约以自动化的方式将它们聚合在一起。区块链还存储了全球模型的所有版本。通过查看交易历史,可以检索到一个全局模型版本。例如,一个优点是,如果在训练阶段由于过拟合而导致性能下降,就有可能恢复出模型的最佳版本。得益于区块链的不可篡改和不可抵赖的特性,所有的变化都向局部和全局模型转变可以很容易地跟踪。此外,当用于签名交易的密钥与物理实体相关联时,可以在FL过程中提供问责制。这些特性在医疗保健背景下是相关的,模型生成中的错误甚至可能产生法律后果。使用区块链还可以防止恶意用户可能在没有被检测的情况下为生成全局模型做出贡献。例如,攻击者可能会提供带有某种后门的部分模型,从而破坏全局模型在特定子任务上的性能(例如,将危重病人的病情分类为稳定)。
学习客户:学习客户(也称为客户)是参与培训过程的实体。他们利用患者的重要生理数据在局部训练ML模型。训练同时利用了局部决策(优化算法)和全局决策(聚合各部分模型的算法)。后者区分哪些数据应该在区块链上发布,以及发布的频率。一旦本地训练结束,客户端依靠智能合约的支持来发布自己的结果。区块链服务器利用客户端提供的信息更新全局模型,然后将全局模型返回给客户端,并将其作为下一轮本地训练的起点。一旦培训结束,为学习客户提供一个全局模型,使他们能够推断患者的健康状况。
工作中的FRAMH
1 )每个FRAMH代理使用被监测患者收集的数据训练一个局部模型。一旦生成最终的全局模型并发送给FRAMH代理,FRAMH就准备好接收和评估访问请求。
2 )监测患者的可穿戴式IoMT设备周期性地向FRAMH代理发送重要的生理数据,FRAMH代理为他们提供全局模型,进而输出患者当前的健康状况。因此,当有新的访问请求时到达时,FRAMH代理人知晓患者病情。
在运行时,当医生需要访问患者数据时,访问控制过程包括以下几个阶段。
1 )医生向PEP发送访问请求,包含他自己的情景信息。
2 ) PEP收集请求者提供的数据以及进一步的情景信息(即请求的位置和时间戳)。此外,它通过PIP检索与该访问请求相关联的患者的健康状况和其他情景信息。让我们假设,当医生试图访问患者神经系统数据时,PIP提供的上下文信息表明患者病情是稳定的。
3 ) PEP利用检索到的信息构建一个可以被PDP解释的查询。
4 ) PDP根据相应的策略对PEP发送的访问请求进行评估。PDP在访问控制验证过程中使用的策略和数据由PAP提供。在这种情况下,拒绝了这一请求。
实验结果
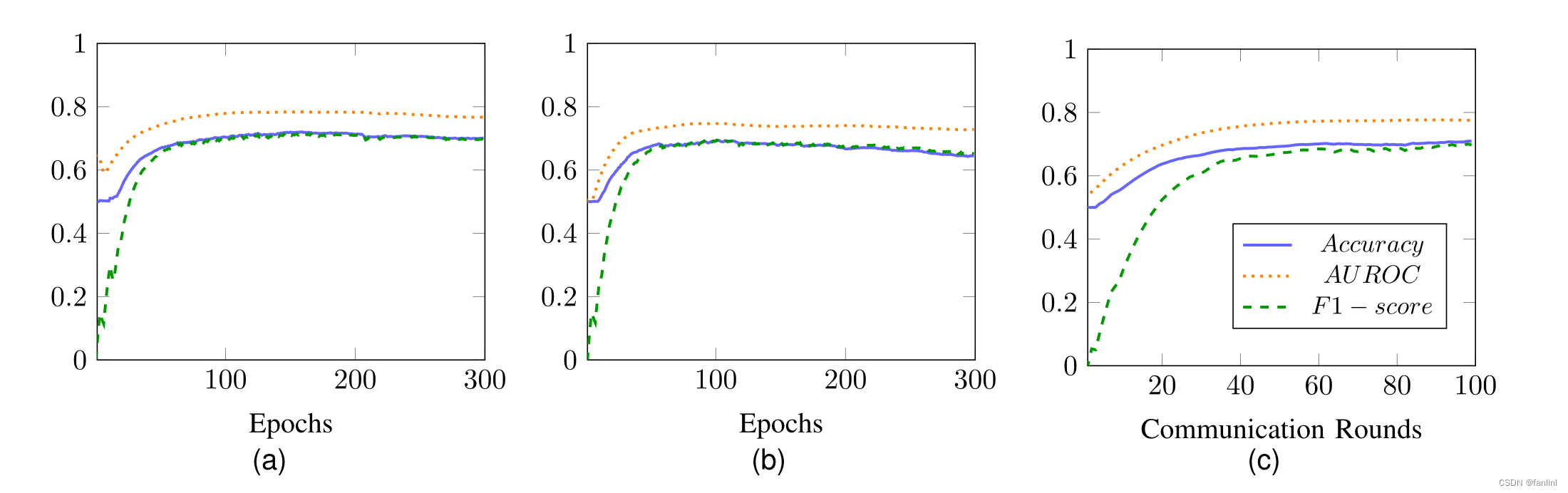
从三个图中,我们可以说明通过FL得到的模型达到了与使用整个训练集训练的集中式模型相当的性能。有趣的是,使用75 %的训练集训练的集中式模型比联邦式模型表现更差。
AUROC是对不同阈值设置下分类问题的性能度量。它告诉我们模型在多大程度上能够区分类别。
F1值可以理解为精确率和召回率的调和平均值。精确率是真阳性的数量除以所有阳性的数量,而召回率是真阳性的数量除以所有应该被识别为阳性的样本的数量。
在医疗保健场景中,预测假阴性和有效区分患有疾病和没有疾病的患者是两个严重的问题。















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









