






 本文介绍了Vulkan图形 API 如何通过命令池和同步原语实现多线程优化,提高效率。Vulkan将线程安全的责任交给应用,允许应用根据需要分配命令池和管理多线程录制。通过使用semaphores、events和fences进行同步,应用可以精细控制工作流,确保GPU忙碌并减少CPU空闲时间。这种优化对于游戏和高性能图形应用尤其重要。
本文介绍了Vulkan图形 API 如何通过命令池和同步原语实现多线程优化,提高效率。Vulkan将线程安全的责任交给应用,允许应用根据需要分配命令池和管理多线程录制。通过使用semaphores、events和fences进行同步,应用可以精细控制工作流,确保GPU忙碌并减少CPU空闲时间。这种优化对于游戏和高性能图形应用尤其重要。
Quick background
Vulkan was created from the ground up to be thread-friendly and there's a huge amount of details in the spec relating to thread-safety and the consequences of function calls. In OpenGL, for instance, the driver might have a number of background threads working while waiting for API calls from the application. In Vulkan, this responsibility has moved up to the application level, so it's now up to you to ensure correct and efficient multi-threading behavior. This is a good thing since the application often has better visibility of what it wants to achieve.
Command pools
In Vulkan command buffers are allocated from command pools. Typically you pin command pools to a thread and only use this thread when writing to command buffers allocated from its command pool. Otherwise you need to externally synchronize access between the command buffer and the command pool which adds overhead.
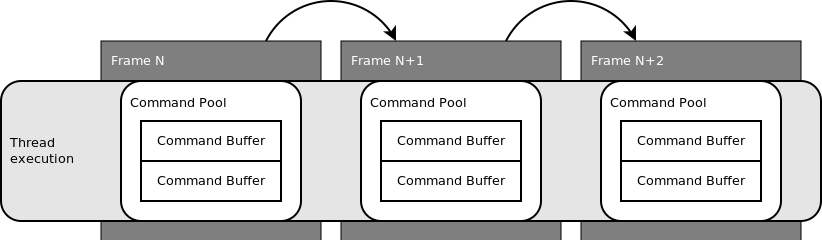
For graphics use-cases you also typically pin a command pool per frame. This has the nice side-effect that you can simply reset the entire command pool once the work for the frame is completed. You can also reset individual command buffers, but it's often more efficient to just reset the entire command pool.
Coordinating work
In OpenGL, work is executed implicitly behind the scenes. In Vulkan this is explicit where the application submits command buffers to queues for execution.
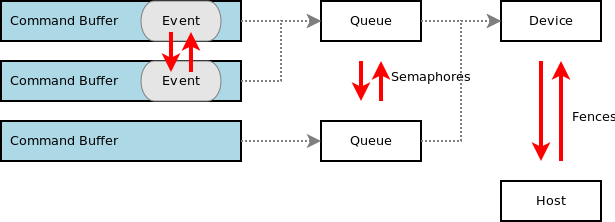
Vulkan has the following synchronization primitives:
- Semaphores - used to synchronize work across queues or across coarse-grained submissions to a single queue
- Events and barriers - used to synchronize work within a command buffer or a sequence of command buffers submitted to a single queue
- Fences - used to synchronize work between the device and the host
Queues have simple sync primitives for ordering the execution of command buffers. You can basically tell the driver to wait for a specific event before processing the submitted work and you can also get a signal for when the submitted work is completed. This synchronization is really important when it comes to submitting and synchronizing work to the swap chain. The following diagram shows how work can be recorded and submitted to the device queue for execution before we finally tell the device to present our frame to the display.
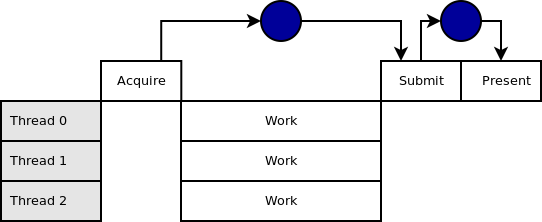
In the above sequence there is no overlap of work between different frames. Therefore, even though we're recording work to command buffers in multiple threads, we still have a certain amount of time where the CPU threads sit idle waiting for a signal in order to start work on the next frame.
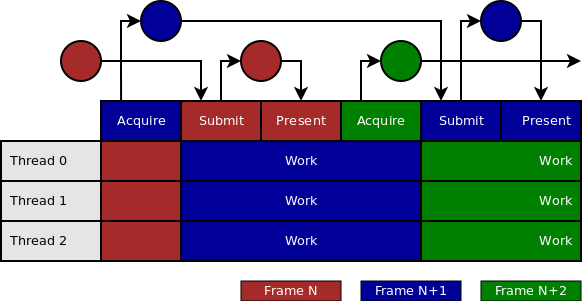
This is much better. Here we start recording work for the next frame immediately after submitting the current frame to the device queue. All synchronization here is done using semaphores. vkAcquireNextImageKHR will signal a semaphore once the swap chain image is ready, vkQueueSubmit will wait for this semaphore before processing any of the commands and will signal another semaphore once the submitted commands are completed. Finally, vkQueuePresentKHR will present the image to the display, but it will wait for the signaled semaphore from vkQueueSubmit before doing so.
Summary
In this blog post I have given a brief overview of how to get overlap between CPU threads that record commands into command buffers over multiple frames. For our own internal implementation we found this really useful as it allowed us to start preparing work for the next frame very early on, ensuring the GPU is kept busy.

















 6182
6182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









