







对梯度下降算法的理解
在线性回归问题中,梯度下降算法用于寻找最适合的参数向量θ,以构造一条能够最好地拟合训练集的曲线,以对新的特征值进行预测。梯度下降是与代价函数J(θ)搭配使用的,在线性回归问题中,代价函数J(θ)为平方差代价函数,其公式为👇:(给出的为仅包含一个特征量的情况,实际问题中,θ为一个n+1维向量,包含n个特征量。)
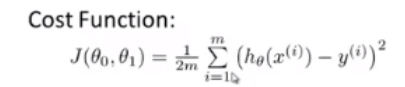
👆通过计算机的迭代不断改变参数θ的值,使代价函数的值最小(收敛)时,得到最佳的参数θ,完成任务。
每一次迭代对于θ值的改变:

其中,α为学习率,控制着每一次迭代的步长。
另注: 代价函数J(θ)的图像是固定的,并不会随着每一次θ的改变而改变,因为θ是自变量而非因变量。
线性回归中的梯度下降
对于线性回归问题,由于其使用的代价函数是平方差代价函数,故每一次迭代θ值变化的公式中,偏导项是可以表示出来的。下👇为线性回归中梯度下降参数迭代的公式:

由于上式👆仅包含了θ0和θ1(包含1个特征量),故下面引出向量化(包含n个特征量)的线性回归梯度下降版本。
向量化
向量化的目的即对多元式子进行简化运算。

如上图👆,为一个向量化的假设函数hθ(x),为θ向量的转置与x向量相乘(实现了一向对一项的乘积和)。
同理,在梯度下降的迭代过程中,更新参数时只需要对向量θ进行维护即可。

(上图👆为赋n = 2时,更新参数的过程,其中,x0显式地表示了出来,但无论何时我们都应默认x0 = 1。)
对参数的更新过程进行向量化,得:θ := θ - α*σ。
其中,θ为 n+1 维向量,α为学习率,是需要你预先设定的,σ也为 n+1 维向量,其每一项的表达式为👇:
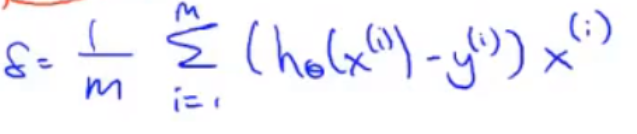
实际上,σ为每个偏导项组成的向量,由于偏导项最后需要乘以一个x,而x由n+1个(因为包含了x0,从0到n当然是n+1个数),故偏导众项也可以组成一个n+1维向量。这样,向量化的任务就完成了。
学习率α的选择
代价函数收敛(找到了最小值,即迭代完成)的条件:如果一步的迭代使代价函数的前后差值小于10-3则认为代价函数已经收敛。数学家已经证明,如果学习率α足够小,那么每一次迭代都能够做到代价函数值下降。(即我们想要的结果) 但倘若α太小,会降低代价函数收敛的速度,降低梯度下降的效率。
由于学习率α是由我们自己选择的,所以我们可以尝试不同的值,以得到最佳的学习率α。

以上就是将梯度下降应用在线性回归中的所有内容。















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









