







nccl基础使用
NCCL不只是pytorch,其它框架tensorflow 或者基于pytorch的deepspeed等,在gpu底层通讯库,都是使用的nccl,nccl是一组基于cuda的,通信原语api。
而nccl,其实是有一组复杂的环境变量
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html
反直觉的是,即便只用一张卡,跑单卡模型,也会使用nccl,整个pytorch训练过程,都是在不停使用nccl的(也会直接使用cuda)。
单机单卡,单机多卡,nccl默认的环境变量是无需更改的,足够使用(除非有一定严格的调优需求),可是,多机多卡,nccl默认是会出现很多的问题,大模型热导致多机多卡的需求多了起来,可是网上多机多卡的文档并不是很好,这就是现在许多人在训练中出现问题的主要原因。
NCCL_DEBUG
nccl环境变量很多,但是核心需要使用的只有几个,先说debug 方面的,尤其是当程序跑不起来时,建议加上下面三个环境变量
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=ALL
export NCCL_DEBUG_FILE=debug_torchrun.log
这样,会在当前目录下,生成一个debug_torchrun.log文件,里面也是有不少重要的信息,当然如果顺利跑起来的话,这三个环境变量无需加。
NCCL_SOCKET_IFNAME
指定通信网卡,一般都是eth0,这个网卡需要是机器的默认网卡,在容器里面可能会变名字。
这个网卡的ip也是 master节点使用的ip (master addr)
export NCCL_SOCKET_IFNAME=eth0
需要注意,安全组需要放开
NCCL_IB_HCA
hpc机型都是有rdma网卡的(这里不区分ib和roce,统一称rdma网卡)
输入命令 ibdev2netdev
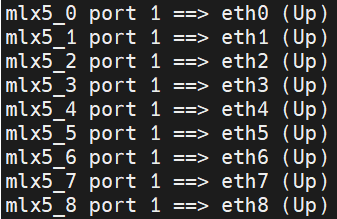
会显示9个网卡,其中,1-8是传输数据,承载流量用的,0只是通信用的!
至于为什么0只是通信用,这与云厂商或者机器厂商有关,往往都是人为划定,从网卡硬件上来看,网卡并没有本质区别,但是网卡的接入的交换机是不同的,比如有时候网卡是给存储使用,使用存储网卡进行训练就会卡死。
这里的网卡0就是普通网卡功能,因为和1-8接入的交换机不同,无法正常使用进行训练,需要通过环境变量人为指定需要的网卡。
1-8 的网卡都有rdma功能,性能强大,0没有rdma功能(有些机器没关,还是有),即便网卡0有rdma功能,也不该让网卡0来承载流量,因为这会严重影响训练的性能,甚至有几倍的差距。
想正确使用这8个网卡,需要明确的指定 (后面这个:1对应的是上图中的 port 1 )
export NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1
这样nccl就会知道使用这八张网卡。
如果只想使用特定的两张网卡是否可以?自然是可以的,以下面为例
export NCCL_IB_HCA=mlx5_1:1,mlx5_2:1
这样只会使用卡1和卡2
但是需要注意的是,nccl不支持 网卡数量大于显卡数量!也就是如果只使用4个gpu,那就只能使用4个网卡,当然也可以使用1个,但是不能使用8个。
如果是整机8卡训练,很简单就是将八张ib网卡都指定即可
export NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1
如果想非整机使用,但还想多机多卡训练,以每台机器只使用两个gpu 0,1 为例
首先,并不推荐这种用法。因为无论网卡性能怎样,两个机器两张卡比起一台机器四张卡,肯定还是差一些的,也麻烦一些,如果一定要这么使用,需要找对正确的网卡,因为在实际硬件中,不同的gpu和不同的ib网卡,有的“近”,有的“远”,这个是硬件决定的,因为设备会分批插到不同的pcie switch上面去,不会插到一起。
如何选择正确的网卡,使用命令nvidia-smi
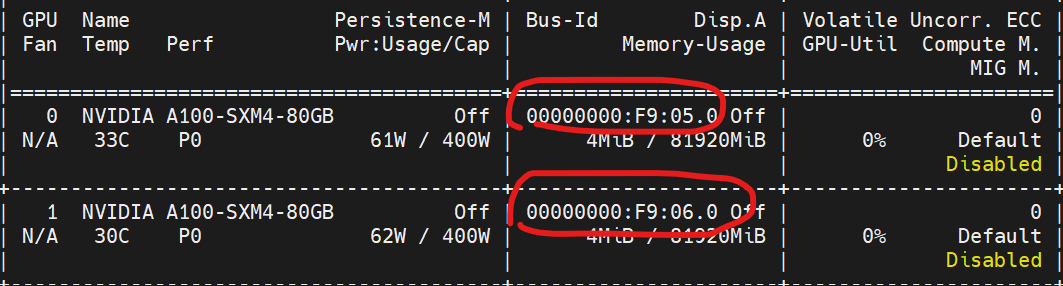
gpu 0和gpu 1 的pci地址分别为 f9:05.0 和 f9:06.0
打开文件 /var/run/nvidia-topologyd/virtualTopology.xml (这个文件不要修改,要是不小心修改了,删除源文件,会自动生成一个新文件)
ps:如果使用容器,需要将这个文件挂载进容器内
示例:
docker run --gpus ‘“device=0,2”’ --network=host -itd -v /run/nvidia-topologyd/virtualTopology.xml:/run/nvidia-topologyd/virtualTopology.xml:ro f78909c2b360 bash
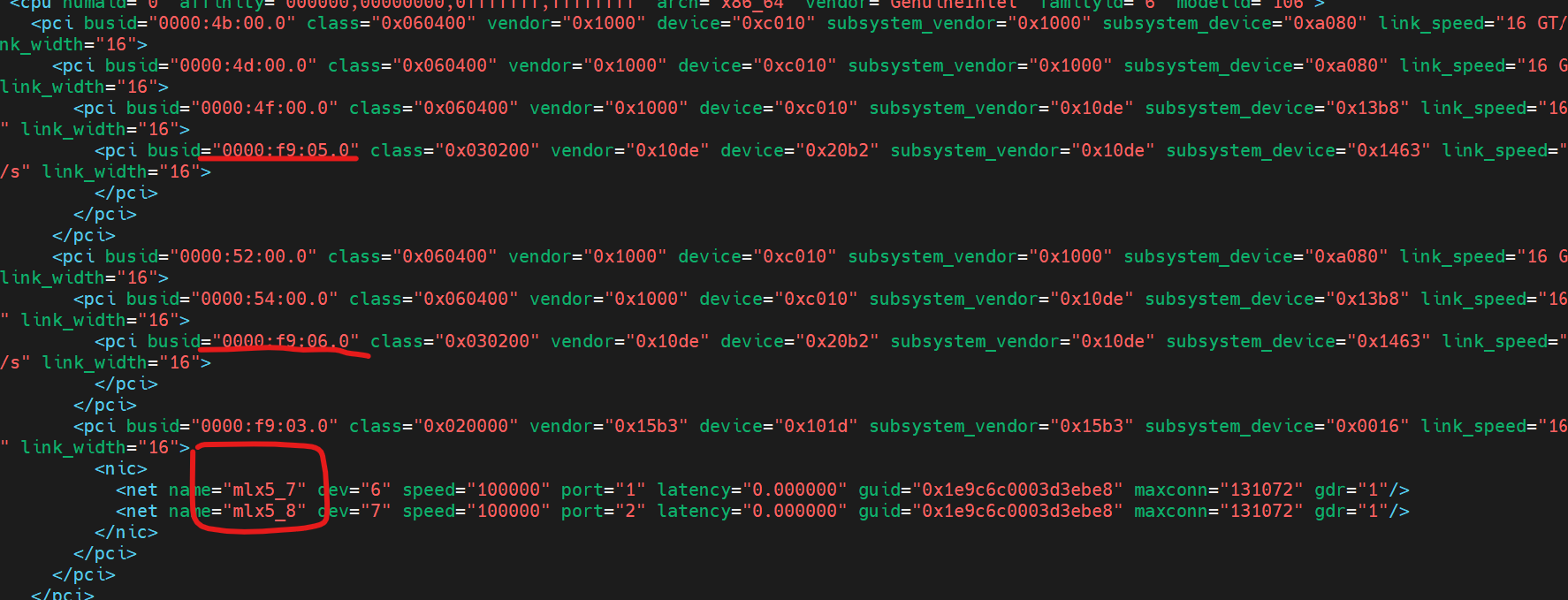
可以看出来,gpu 0 和 gpu 1对应的网卡是mlx5_7和mlx5_8,所以如果想跑多机多卡的时候,需要指定
export NCCL_IB_HCA=mlx5_7:1,mlx5_8:1
(7和8的顺序无所谓)
NCCL_IB_GID_INDEX指定网卡的index
rdma网卡是有很多工作状态的,一般称为index,使用命令 show_gids
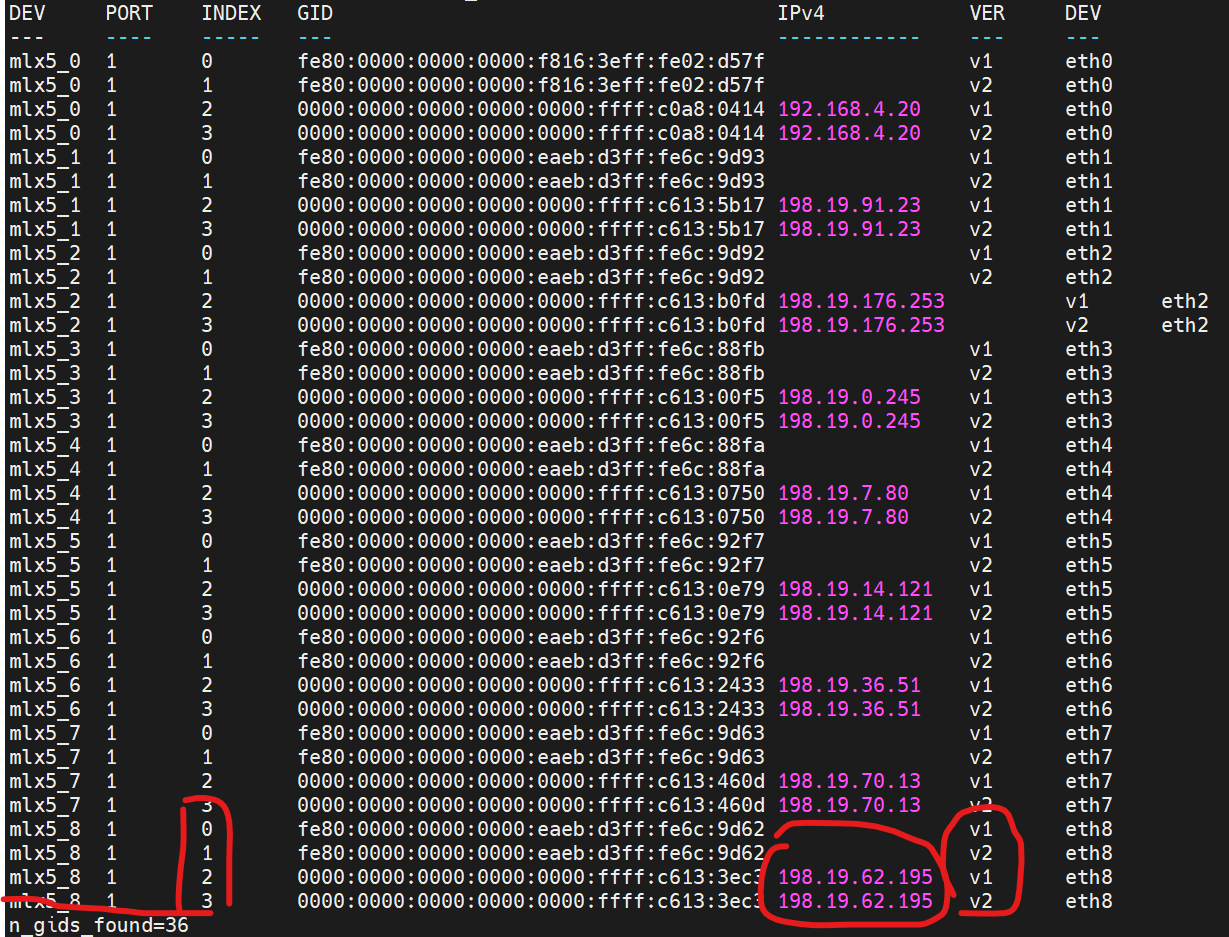
以mlx5_8为例,它的index 有0,1,2,3 四种情况,可以看出来,0和1是没有ip的,ib网卡可以不需要ip,不过目前hpc机型都是roce网卡,所以需要有ip ,而2 和3的区别,在于是roce v1还是roce v2
v2模式是可以跨子网的,v1只能在同一子网使用,这里选择可以跨子网的v2
所以最终环境变量为
export NCCL_IB_GID_INDEX=3
NCCL_NET_GDR_LEVEL
用户可以控制是否使用gpu direct rdma功能,简称gdr
gdr功能可以让显存里面的数据直接传输给网卡,如果不开启gdr,需要gpu -> 内存 -> 网卡 中转一下,开启gdr,可以提升性能,节省内存
但是事实上,gdr并不是每次都开好,有的时候,gpu和网卡之间的距离比较 “远”,传输数据需要跨过很多的硬件,还不如在内存中转一下快,所以需要设定哪些级别需要,就是硬件之间到底多近开启合适
export NCCL_NET_GDR_LEVEL=2
NCCL_IB_DISABLE
是否使用rdma网卡,也是可选的,有时候网卡不够用了,或者嫌弃rdma网卡配置困难,可以选择禁用rdma网卡,加入下面环境变量
export NCCL_IB_DISABLE=1
正常想使用rdma网卡
export NCCL_IB_DISABLE=0
使用示例
NCCL_IB_GID_INDEX=3
NCCL_NET_GDR_LEVEL=2
NCCL_DEBUG=INFO
NCCL_DEBUG_SUBSYS=ALL
NCCL_DEBUG_FILE=debug_torchrun.log
NCCL_IB_DISABLE=0
NCCL_SOCKET_IFNAME=eth0
OMP_NUM_THREADS=1
NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1
torchrun
–nproc_per_node 8 --nnodes 2 --node_rank 0
–master_addr=‘192.168.16.40’
–master_port=‘6101’ example_mini.py

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









