







 该项目通过爬取豆瓣电影Top100的电影类型,使用jieba进行中文分词,然后利用wordcloud进行词云图的生成,展示电影类型的热度。数据处理和分析使用了pandas,最后通过pyecharts展示具有特定样式的词云图。
该项目通过爬取豆瓣电影Top100的电影类型,使用jieba进行中文分词,然后利用wordcloud进行词云图的生成,展示电影类型的热度。数据处理和分析使用了pandas,最后通过pyecharts展示具有特定样式的词云图。
目录
一.项目简介
1.词云
词云是基于文本分析的一种可视化方式,通过统计分析文本中每个词的出现频率,并在图 形界面上根据词频以不同大小、颜色、形状等方式展现,来反映文本的热点话题或主题关键 词,具 有可视化、直观、易理解等特点,在文本分析领域得到广泛应用。
词云的生成可以分成三步:读入文本,将文本进行分词,统计词频并生成词云图。
2. wordcloud介绍
wordcloud对象有很多参数设定,可以绘制不同形状、颜色和尺寸的词云图。
| 参数 | 说明 |
| font_path | 设置字体,指定字体文件的路径 |
| width | 生成图片宽度,默认400像素 |
| height | 生成图片高度,默认200像素 |
| mask | 词云形状,默认使用矩形 |
| min_font_size | 词云中最小的字体字号,默认四号 |
| font_step | 字号步进间隔,默认1 |
| max_font_size | 词云中最大的字体字号,默认根据高度自动调节 |
| max_words | 词云显示的最大词数,默认200 |
| stopwords | 设置停用词(需要屏蔽的词),停用词不在词云中显示,默认使用内置的STOPWORDS |
| background_color | 图片背景颜色,默认黑色 |
wordCloud常用方法
| 方法 | 功能 |
| generate(text) | 加载词云文本 |
| to_file(filename | 输出词云文件 |
3.数据
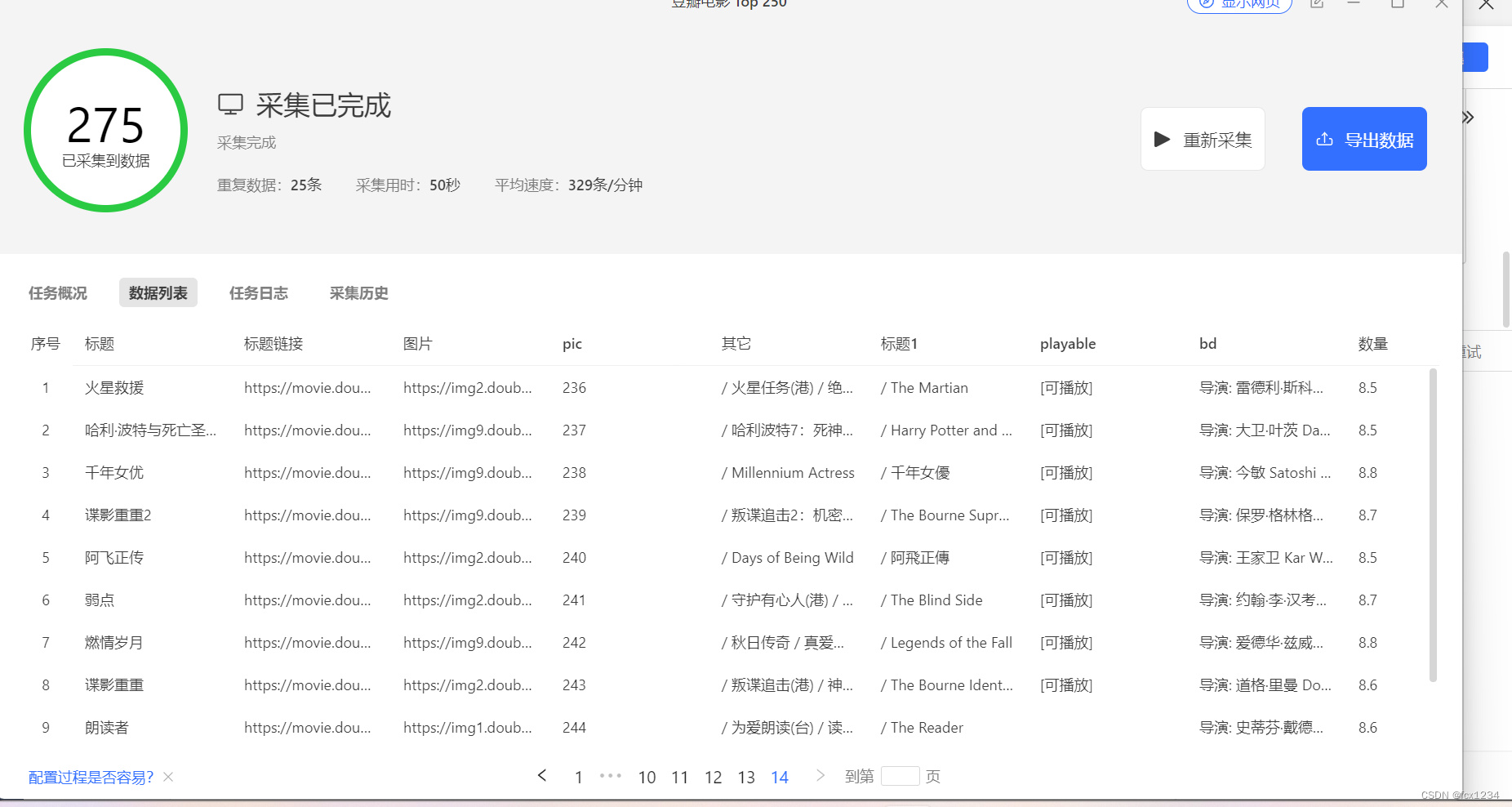
使用八爪鱼软件爬取豆瓣电影的top100电影的类型,因为所爬取的内容中影片的类型不止一个,所以需要通过jieba分词器分词之后,才能统计各个词出现的频数,再根据词频绘制词云图,这是数据分析的内容,用pandas库实现。
数据来源:豆瓣电影
二.项目实施步骤
1.安装相应的第三方库
因为wordcloud默认是为英文文本来做词云,如果需要制作中文文本词云,则需要用jieba中文分词库进行分词
首先是中文分词jieba的安装
$ pip3 install jieba然后安装wordcloud词云图库
$ pip3 install wordcloud
2.导入相关的模块
import pandas as pd
import jieba
from snownlp import SnowNLP
import pyecharts.options as opts
from pyecharts.charts import WordCloud3.读取爬取的数据
打开文件,读入文本
data=pd.read_excel('D:\可视化大屏\豆瓣电影排行\data\豆瓣电影 Top 100.xlsx')
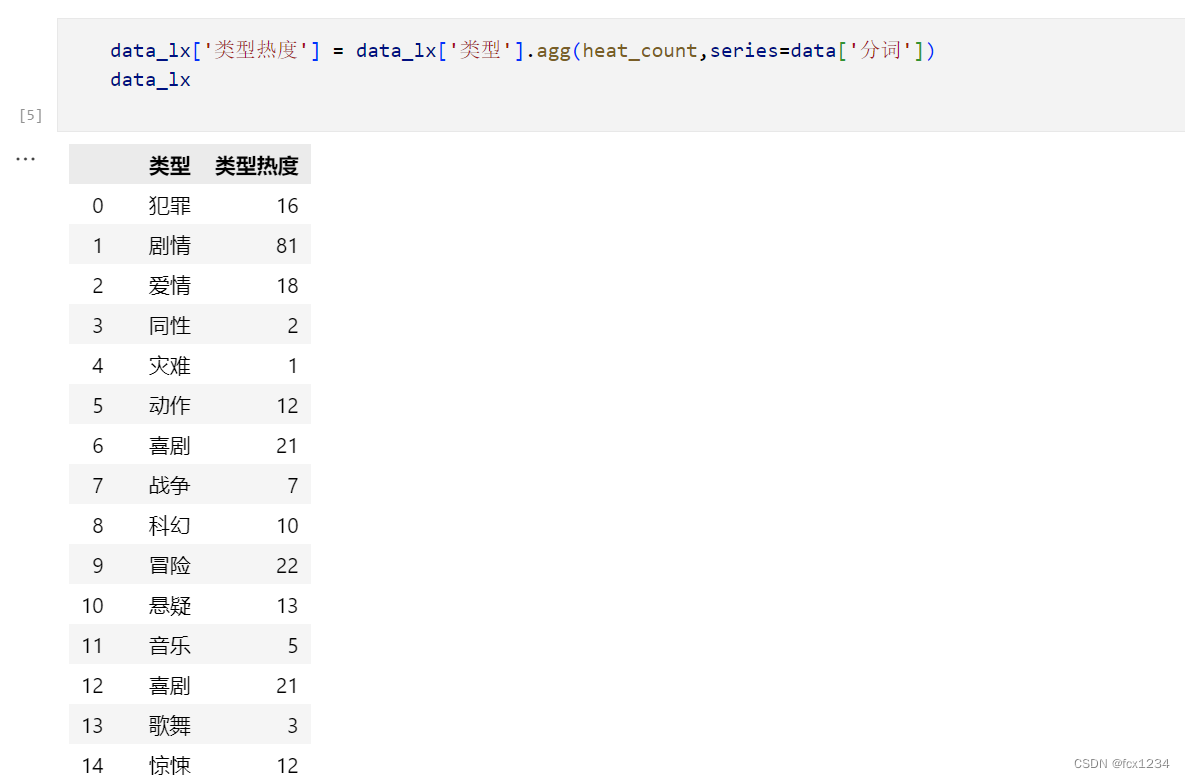
4.创建热度统计函数
#热度统计函数
def heat_count(lx,series):
count = 0
for i in series:
for j in i:
if j==lx:
count+=1
return count5.使用jieba分词器分词
# 分词
data['分词'] = data['类型'].agg(lambda x:jieba.lcut(x))
6.热度统计代码及结果
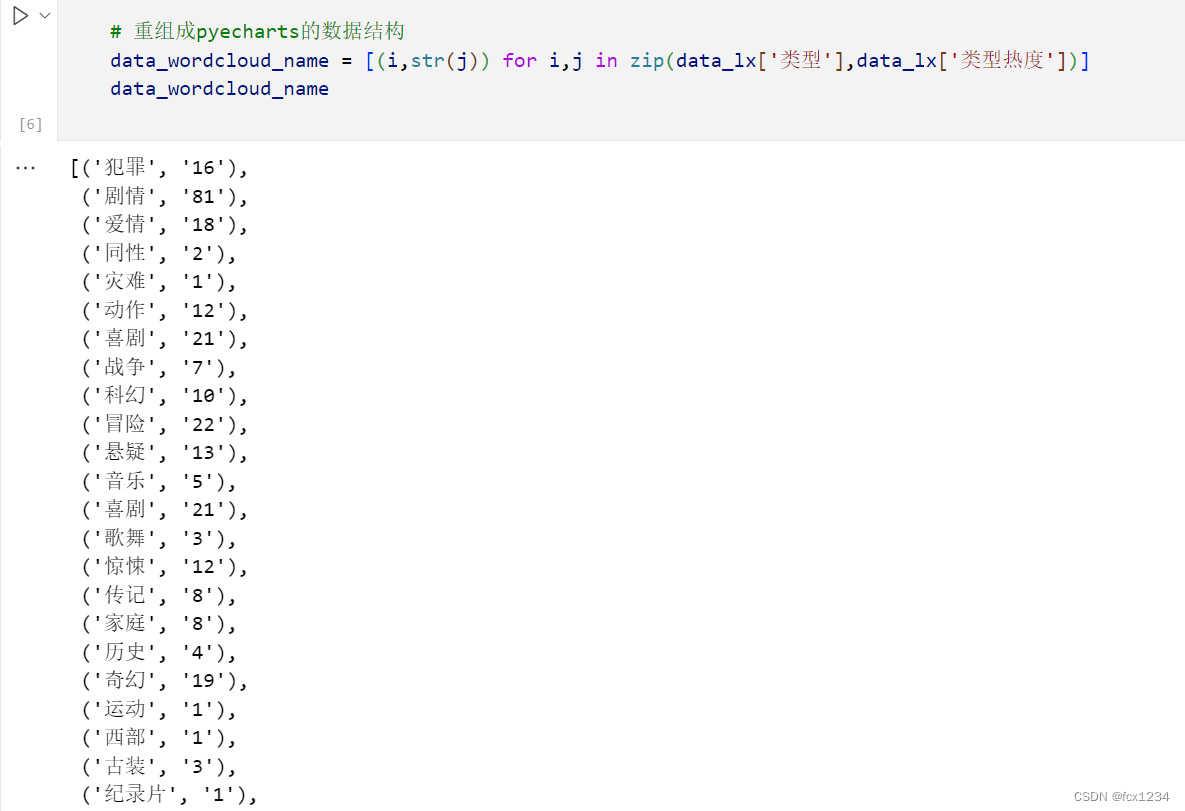
7.重组成pyecharts的数据结构
三.生成词云图的代码及效果图展示
c = (
WordCloud()
.add(series_name="",
data_pair=data_wordcloud_name,
word_size_range=[20, 80],
#shape='star',#设置词云图样式
#word_size_range=[5, 80],
#mask_image='./7.jpg' #通过图片设置词云样式
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="电影类型热度", title_textstyle_opts=opts.TextStyleOpts(font_size=30)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
)
c.render_notebook()
拓展词云图生成特定样式
如果想要生成有不同样式的词云图,可通过对shape进行设定,也可使用白色背景的图片定义词云图的样式,有图案的地方会被词云填充使用mask进行操作,我使用的图片也是星星,可自己选择喜欢的图片,代码如上。



















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









