






config 代码
import os
emotion = ["Valence"]
### For preprocessing
### If tagged with "# Check this", then it's adjustable, otherwise leave it alone.
config = {
"extract_class_label": 1,
"extract_continuous_label": 1,
"extract_eeg": 1,
"eeg_folder": "eeg",
"eeg_config": {
"sampling_frequency": 256,
"window_sec": 2, # Check this
"hop_sec": 0.25, # Check this
"buffer_sec": 5, # Check this
"num_electrodes": 32,
"interest_bands": [(0.3, 4), (4, 8), (8, 12), (12, 18), (18, 30), (30, 45)], # Check this
"f_trans_interest_bands": [(0.1, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)], # Check this
"channel_slice": {'eeg': slice(0, 32), 'ecg': slice(32, 35), 'misc': slice(35, -1)},
"features": ["eeg_bandpower"],
"filter_type": 'cheby2', #cheby2, butter
"filter_order": 4
},
"save_npy": 1,
"npy_folder": "compacted_48",
"dataset_name": "mahnob",
"emotion_list": emotion,
"root_directory": r"/home/hd/dingyi/MAHNOB", # Check this
"output_root_directory": r"/home/hd/dingyi/MAHNOB-P", # Check this
"raw_data_folder": "Sessions",
"multiplier": {
"video": 16,
"eeg_raw":1,
"eeg_bandpower": 1,
"eeg_DE": 1,
"eeg_RP": 1,
"eeg_Hjorth": 1,
"continuous_label": 1,
},
"feature_dimension": {
"eeg_raw": (16384,),
"eeg_bandpower": (192,),
"eeg_DE": (192,),
"eeg_RP": (192,),
"eeg_Hjorth": (96,),
"continuous_label": (1,),
"class_label": (1,),
},
"max_epoch": 15, # Check this
"min_epoch": 0,
"model_name": "2d1d", # Check this ## No actual use but only a naming issue.
"backbone": {
"state_dict": "res50_ir_0.887",
"mode": "ir",
},
"early_stopping": 10, # Check this
"load_best_at_each_epoch": 1, # Check this
"time_delay": 0, # Check this, Move the continuous label afterward for n data points. One data point = 0.25s.
"metrics": ["rmse", "pcc", "ccc"],
"save_plot": 0,
}0it [00:00, ?it/s]
出现`0it [00:00, ?it/s]`的错误通常是因为在迭代过程中出现了问题,导致无法计算迭代速度。这可能是由于数据集为空或者迭代器没有正确初始化等原因引起的。建议您检查数据集是否正确加载,确保数据集中包含有效的数据,并且确保迭代器在使用前已正确初始化。您可以逐步调试代码,查看在哪一步出现了问题,以便进一步定位和解决错误。如果需要更详细的帮助,请提供更多代码或上下文信息,我将尽力协助您解决问题。
要在Linux终端中运行Python代码,您可以按照以下步骤操作:
-
打开终端:在Linux系统中,您可以使用终端应用程序(如Terminal、Konsole等)来执行命令和运行Python代码。
-
编辑代码:使用文本编辑器(如vim、nano等)编写您的Python代码,并保存为一个.py文件,比如example.py。
-
运行代码:在终端中使用Python解释器来执行您的Python脚本。在终端中输入以下命令:
bash
插入代码复制代码
python3 example.py
这将运行您的Python脚本,并输出1到5这五个数字。确保您的Python环境已正确安装并配置在Linux系统中。
如果您想在终端中逐行执行Python代码而不是运行整个脚本,可以使用交互式Python解释器。在终端中输入以下命令启动Python解释器:
bash
插入代码复制代码
python3
然后逐行输入代码并按Enter执行。例如:
bash
插入代码复制代码
>>> data = [1, 2, 3, 4, 5] >>> iter_data = iter(data) >>> for item in iter_data: ... print(item)
这样您就可以在Linux终端中逐行执行Python代码了。希望这些说明对您有帮助。如果您有任何疑问或需要进一步帮助,请随时告诉我。
datates 代码
from base.preprocessing import GenericDataPreprocessing
from base.utils import expand_index_by_multiplier, load_pickle, save_to_pickle, get_filename_from_a_folder_given_extension, ensure_dir
from base.label_config import *
import os
import scipy.io as sio
import pandas as pd
import numpy as np
import xml.etree.ElementTree as et
class Preprocessing(GenericDataPreprocessing):
def __init__(self, config):
super().__init__(config)
def generate_iterator(self):
path = os.path.join(self.config['root_directory'], self.config['raw_data_folder'])
iterator = [os.path.join(path, file) for file in sorted(os.listdir(path), key=float)]
return iterator
def generate_per_trial_info_dict(self):
per_trial_info_path = os.path.join(self.config['output_root_directory'], "processing_records.pkl")
if os.path.isfile(per_trial_info_path):
per_trial_info = load_pickle(per_trial_info_path)
else:
per_trial_info = {}
pointer = 0
sub_trial_having_continuous_label = self.get_sub_trial_info_for_continuously_labeled()
all_continuous_labels = self.read_all_continuous_label()
iterator = self.generate_iterator()
for idx, file in enumerate(iterator):
kwargs = {}
this_trial = {}
print(file)
time_stamp_file = get_filename_from_a_folder_given_extension(file, "tsv", "All-Data")[0]
video_trim_range = self.read_start_end_from_mahnob_tsv(time_stamp_file)
if video_trim_range is not None:
this_trial['video_trim_range'] = self.read_start_end_from_mahnob_tsv(time_stamp_file)
else:
this_trial['discard'] = 1
continue
this_trial['has_continuous_label'] = 0
session = int(file.split(os.sep)[-1])
subject_no, trial_no = session // 130 + 1, session % 130
if subject_no == sub_trial_having_continuous_label[pointer][0] and trial_no == sub_trial_having_continuous_label[pointer][1]:
this_trial['has_continuous_label'] = 1
this_trial['continuous_label'] = None
this_trial['annotated_index'] = None
annotated_index = np.arange(this_trial['video_trim_range'][0][1])
if this_trial['has_continuous_label']:
raw_continuous_label = all_continuous_labels[pointer]
this_trial['continuous_label'] = raw_continuous_label
annotated_index = self.process_continuous_label(raw_continuous_label)
this_trial['annotated_index'] = annotated_index
pointer += 1
# this_trial['video_path'] = get_filename_from_a_folder_given_extension(file, "avi")[0].split(os.sep)
# this_trial['extension'] = "mp4"
# Some trials has no EEG recordings
this_trial['has_eeg'] = 1
eeg_path = get_filename_from_a_folder_given_extension(file, "bdf")
if len(eeg_path) == 1:
this_trial['eeg_path'] = eeg_path[0].split(os.sep)
else:
this_trial['eeg_path'] = None
this_trial['has_eeg'] = 0
this_trial['audio_path'] = ""
this_trial['subject_no'] = subject_no
this_trial['trial_no'] = trial_no
this_trial['trial'] = "P{}-T{}".format(str(subject_no), str(trial_no))
this_trial['target_fps'] = 64
kwargs['feature'] = "video"
kwargs['has_continuous_label'] = this_trial['has_continuous_label']
this_trial['video_annotated_index'] = self.get_annotated_index(annotated_index, **kwargs)
this_trial['class_label'] = get_filename_from_a_folder_given_extension(file, "xml")[0]
per_trial_info[idx] = this_trial
ensure_dir(per_trial_info_path)
save_to_pickle(per_trial_info_path, per_trial_info)
self.per_trial_info = per_trial_info
def generate_dataset_info(self):
class_label = {}
for idx, record in self.per_trial_info.items():
self.dataset_info['trial'].append(record['processing_record']['trial'])
self.dataset_info['trial_no'].append(record['trial_no'])
self.dataset_info['subject_no'].append(record['subject_no'])
self.dataset_info['has_continuous_label'].append(record['has_continuous_label'])
self.dataset_info['has_eeg'].append(record['has_eeg'])
if record['has_continuous_label']:
self.dataset_info['length'].append(len(record['continuous_label']))
else:
self.dataset_info['length'].append(len(record['video_annotated_index']) // 16)
if self.config['extract_class_label']:
class_label.update({record['processing_record']['trial']: self.extract_class_label_fn(record)})
self.dataset_info['multiplier'] = self.config['multiplier']
self.dataset_info['data_folder'] = self.config['npy_folder']
path = os.path.join(self.config['output_root_directory'], 'dataset_info.pkl')
save_to_pickle(path, self.dataset_info)
if self.config['extract_class_label']:
path = os.path.join(self.config['output_root_directory'], 'class_label.pkl')
save_to_pickle(path, class_label)
def extract_class_label_fn(self, record):
class_label = {}
if record['has_eeg']:
xml_file = et.parse(record['class_label']).getroot()
felt_emotion = xml_file.find('.').attrib['feltEmo']
felt_arousal = xml_file.find('.').attrib['feltArsl']
felt_valence = xml_file.find('.').attrib['feltVlnc']
arousal = 0 if float(felt_arousal) <= 5 else 1
valence = 0 if float(felt_valence) <= 5 else 1
# Arousal_3cls and Valence_3cls are 3-class label determined by felt categorical emotion tags.
# Arousal and Valence are 2-class label determined by felt arousal and valence intensity.
class_label = {
"Arousal": arousal,
"Valence": valence,
"Arousal_3cls": arousal_class_to_number[emotion_tag_to_arousal_class[number_to_emotion_tag_dict[felt_emotion]]],
"Valence_3cls": valence_class_to_number[emotion_tag_to_valence_class[number_to_emotion_tag_dict[felt_emotion]]]
}
return class_label
def extract_continuous_label_fn(self, idx, npy_folder):
if self.per_trial_info[idx]["has_continuous_label"]:
raw_continuous_label = self.per_trial_info[idx]['continuous_label']
if self.config['save_npy']:
filename = os.path.join(npy_folder, "continuous_label.npy")
if not os.path.isfile(filename):
ensure_dir(filename)
np.save(filename, raw_continuous_label)
def load_continuous_label(self, path, **kwargs):
cols = [emotion.lower() for emotion in self.config['emotion_list']]
if os.path.isfile(path):
continuous_label = pd.read_csv(path, sep=";",
skipinitialspace=True, usecols=cols,
index_col=False).values.squeeze()
else:
continuous_label = 0
return continuous_label
def get_annotated_index(self, annotated_index, **kwargs):
feature = kwargs['feature']
multiplier = self.config['multiplier'][feature]
if kwargs['has_continuous_label']:
annotated_index = expand_index_by_multiplier(annotated_index, multiplier)
# If the trial is not continuously labeled, then the whole facial video is used.
else:
pass
return annotated_index
def get_sub_trial_info_for_continuously_labeled(self):
label_file = os.path.join(self.config['root_directory'], "lable_continous_Mahnob.mat")
mat_content = sio.loadmat(label_file)
sub_trial_having_continuous_label = mat_content['trials_included']
return sub_trial_having_continuous_label
@staticmethod
def read_start_end_from_mahnob_tsv(tsv_file):
if os.path.isfile(tsv_file):
data = pd.read_csv(tsv_file, sep='\t', skiprows=23)
end = data[data['Event'] == 'MovieEnd'].index[0]
start_end = [(0, end)]
else:
start_end = None
return start_end
def read_all_continuous_label(self):
r"""
:return: the continuous labels for each trial (dict).
"""
label_file = os.path.join(self.config['root_directory'], "lable_continous_Mahnob.mat")
mat_content = sio.loadmat(label_file)
annotation_cell = np.squeeze(mat_content['labels'])
label_list = []
for index in range(len(annotation_cell)):
label_list.append(annotation_cell[index].T)
return label_list
@staticmethod
def init_dataset_info():
dataset_info = {
"trial": [],
"subject_no": [],
"trial_no": [],
"length": [],
"has_continuous_label": [],
"has_eeg": [],
}
return dataset_info
if __name__ == "__main__":
from configs import config
pre = Preprocessing(config)
pre.generate_per_trial_info_dict()
pre.prepare_data()调试
python data = load_data_from_file(file_path)
print(data)
在运行 generate_dataset.py 时可能会出现一些错误消息,这是因为原始数据中存在一些格式错误。您可以根据错误消息识别文件并在该文件中纠正格式错误。
需要编辑的确切文件夹/文件包括:
A. Sessions/1200/P10-Rec1-All-Data-New_Section_30.tsv - 删除第 3169-3176 行,因为其格式错误。
B. Sessions/1854 - 删除此试验文件夹,因为它不包含 EEG 记录。
C. Sessions/1984 - 删除此试验文件夹,因为它不包含 EEG 记录。
修改后

main.py 部分
import sys
import argparse
if __name__ == '__main__':
frame_size = 48
crop_size = 40
parser = argparse.ArgumentParser(description='Say hello')
parser.add_argument('-experiment_name', default="pr_rev", help='The experiment name.')
parser.add_argument('-gpu', default=0, type=int, help='Which gpu to use?')
parser.add_argument('-cpu', default=1, type=int, help='How many threads are allowed?')
parser.add_argument('-high_performance_cluster', default=0, type=int, help='On high-performance server or not?')
parser.add_argument('-stamp', default='DY-RP', type=str, help='To indicate different experiment instances')
parser.add_argument('-dataset', default='mahnob_hci', type=str, help='The dataset name.')
parser.add_argument('-modality', default=["eeg_bandpower", "continuous_label"], nargs="*", help='eeg_raw, eeg_bandpower, landmark')
parser.add_argument('-resume', default=0, type=int, help='Resume from checkpoint?')
parser.add_argument('-seed', default=0, type=int)
parser.add_argument('-num-eeg-chan', default=32, type=int)
parser.add_argument('-num-f', default=6, type=int)
parser.add_argument('-case', default='loso', type=str, help='trs: trial-wise shuffling, loso.: leave-one-subject-out.')
parser.add_argument('-task', default='reg', type=str, help='reg: regression, cls: classification.')
parser.add_argument('-debug', default=0, type=str, help='When debug=1, the fold number will be fixed to 3, because there are three subjects'
'in the debug dataset.')
parser.add_argument('-test', default=0, type=int, help='Run test using test=1, run training using test=0')
# Calculate mean and std for each modality?
parser.add_argument('-calc_mean_std', default=0, type=int, help='Calculate the mean and std and save to a pickle file.')
parser.add_argument('-cross_validation', default=1, type=int)
# For trial-level shuffling and 10 fold subject independent
# Not used, just a place-holder for initialization.
# If case = loso, then num_folds = 24. If case = trs, then num_folds = 10.
# It will be automatically set in the experiment according to the case argument. So leave it be here.
parser.add_argument('-num_folds', default=0, type=int, help="How many folds to consider?")
parser.add_argument('-folds_to_run', default=["all"], nargs="+", type=int, help='Which fold(s) to run in this session? If all, then run all the folds.')
parser.add_argument('-dataset_path', default=r'D:\DingYi\Dataset\MAHNOB-P-R', type=str,
help='The root directory of the dataset.') # change this
parser.add_argument('-dataset_folder', default='compacted_{:d}'.format(frame_size), type=str,
help='The root directory of the dataset.')
parser.add_argument('-load_path', default=r'D:\DingYi\Project\MASA-TCN-revision\MASATCN-Reg\load\model_load_path', type=str, help='The path to load the trained model.') # change this
parser.add_argument('-save_path', default=r'D:\DingYi\Project\MASA-TCN-revision\MASATCN-Reg\save', type=str, help='The path to save the trained model ') # change this
parser.add_argument('-python_package_path', default=r'D:\DingYi\Project\MASA-TCN-revision\MASATCN-Reg', type=str, help='The path to the entire repository.') # change this
parser.add_argument('-save_model', default=1, type=int, help='Whether to save the model?')
parser.add_argument('-normalize_eeg_raw', default=0, type=int, help='Whether to normalize eeg raw data?')
# Models
# TCN
parser.add_argument('-bandpower_dim', default=192, type=int, help='electrodes x interest bands')
parser.add_argument('-model_name', default="masatcn", help='Model: tcn, lstm, satcn, masatcn')
parser.add_argument('-backbone_mode', default="ir", help='Mode for resnet50 backbone: ir, ir_se')
parser.add_argument('-backbone_state_dict_frame', default="model_state_dict_0.874", help='The filename for the backbone state dict.')
parser.add_argument('-backbone_state_dict_eeg', default="mahnob_reg_v", help='The filename for the backbone state dict.')
parser.add_argument('-cnn1d_embedding_dim', default=512, type=int, help='Dimensions for temporal convolutional networks feature vectors.')
parser.add_argument('-cnn1d_channels', default=[64, 64], nargs="+", type=int, help='The specific epochs to do something.')
parser.add_argument('-cnn1d_kernel_size', default=[3, 5, 15], help='The size of the 1D kernel for temporal convolutional networks.')
parser.add_argument('-cnn1d_dropout', default=0.15, type=float, help='The dropout rate.')
# LSTM
parser.add_argument('-lstm_embedding_dim', default=68, type=int, help='Dimensions for LSTM feature vectors.')
parser.add_argument('-lstm_hidden_dim', default=68, type=int, help='The size of the 1D kernel for temporal convolutional networks.')
parser.add_argument('-lstm_dropout', default=0.4, type=float, help='The dropout rate.')
parser.add_argument('-learning_rate', default=1e-4, type=float, help='The initial learning rate.')
parser.add_argument('-min_learning_rate', default=1e-6, type=float, help='The minimum learning rate.')
# Groundtruth settings
parser.add_argument('-num_classes', default=1, type=int, help='The number of classes for the dataset.')
parser.add_argument('-emotion', default="valence", nargs="*", help='The emotion dimension to analysis.')
parser.add_argument('-metrics', default=["rmse", "pcc", "ccc"], nargs="*", help='The evaluation metrics.')
# Dataloader settings
parser.add_argument('-window_length', default=96, type=int, help='The length in second to windowing the data.')
parser.add_argument('-hop_length', default=32, type=int, help='The step size or stride to move the window.')
parser.add_argument('-continuous_label_frequency', default=4, type=int,
help='The frequency of the continuous label.')
parser.add_argument('-frame_size', default=frame_size, type=int, help='The size of the images.')
parser.add_argument('-crop_size', default=crop_size, type=int, help='The size to conduct the cropping.')
parser.add_argument('-batch_size', default=2, type=int)
# Scheduler and Parameter Control
parser.add_argument('-scheduler', default='plateau', type=str, help='plateau, cosine')
parser.add_argument('-patience', default=5, type=int, help='Patience for learning rate changes.')
parser.add_argument('-factor', default=0.5, type=float, help='The multiplier to decrease the learning rate.')
parser.add_argument('-gradual_release', default=0, type=int, help='Whether to gradually release some layers?')
parser.add_argument('-release_count', default=0, type=int, help='How many layer groups to release?')
parser.add_argument('-milestone', default=[], nargs="+", type=int, help='The specific epochs to do something.')
parser.add_argument('-save_plot', default=0, type=int,
help='Whether to plot the session-wise output/target or not?')
args = parser.parse_args()
sys.path.insert(0, args.python_package_path)
from experiment import Experiment
exp = Experiment(args)
exp.prepare()
exp.run()




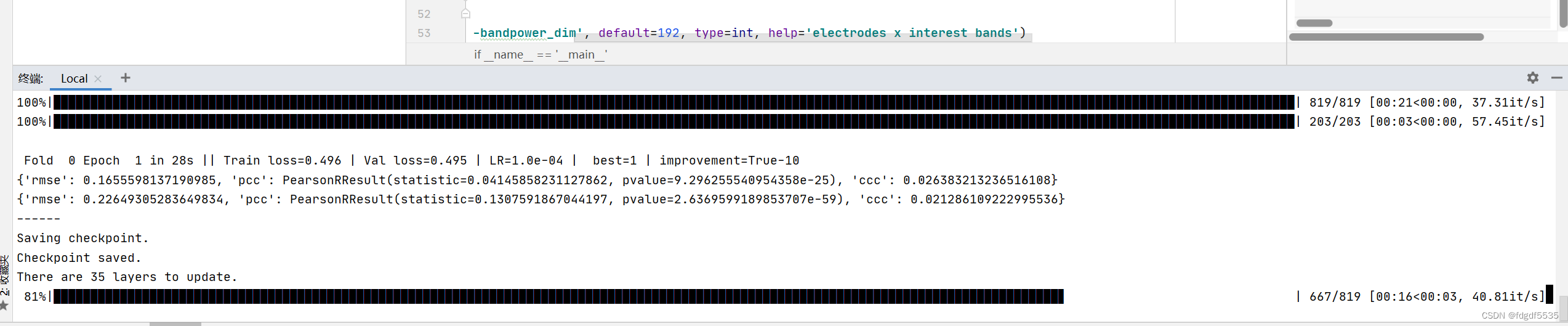
总共 23*15轮

val是验证集。
在机器学习的上下文中,数据集通常被分为三个部分:训练集(train)、验证集(val)和测试集(test)。这三个部分各自承担不同的角色和功能:
训练集(train):用于训练模型,即用来拟合模型的数据集。
验证集(val):在训练过程中,用于评估模型的表现,提供相对于训练集的无偏估计的数据集。它还用于调整超参数和特征选择,实际参与训练过程。验证集的目的是让用户在边训练边看到训练的结果,及时判断学习状态。
测试集(test):最终模型训练好之后,用于提供相对于训练集和验证集的无偏估计的数据集,用来评价模型的结果。
因此,val指的是验证集,它的主要作用是在训练过程中帮助用户及时了解模型的训练状态,通过它来调整超参数和特征选择,以确保模型不会过拟合训练数据。

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









